Как мы превратили традиционные PDF-газеты в современный digital-канал рекламы
Несмотря на бурное развитие digital, основным форматом хранения новостных изданий остаётся PDF, поскольку он сохраняет оригинальную верстку, фотографии и анонсы статей, что особенно важно для исторических изданий.
Однако у такого канала есть серьёзное ограничение – традиционные PDF остаются статичными, не позволяя строить полноценное взаимодействие между рекламодателями и аудиторией. А ведь такой объем рекламных площадей остается неиспользованным.
Рекламодатели и издатели мечтают сделать классическую газету не только информативной, но и “живой”, чтобы реклама в ней взаимодействовала с аудиторией, а результат можно было измерить.
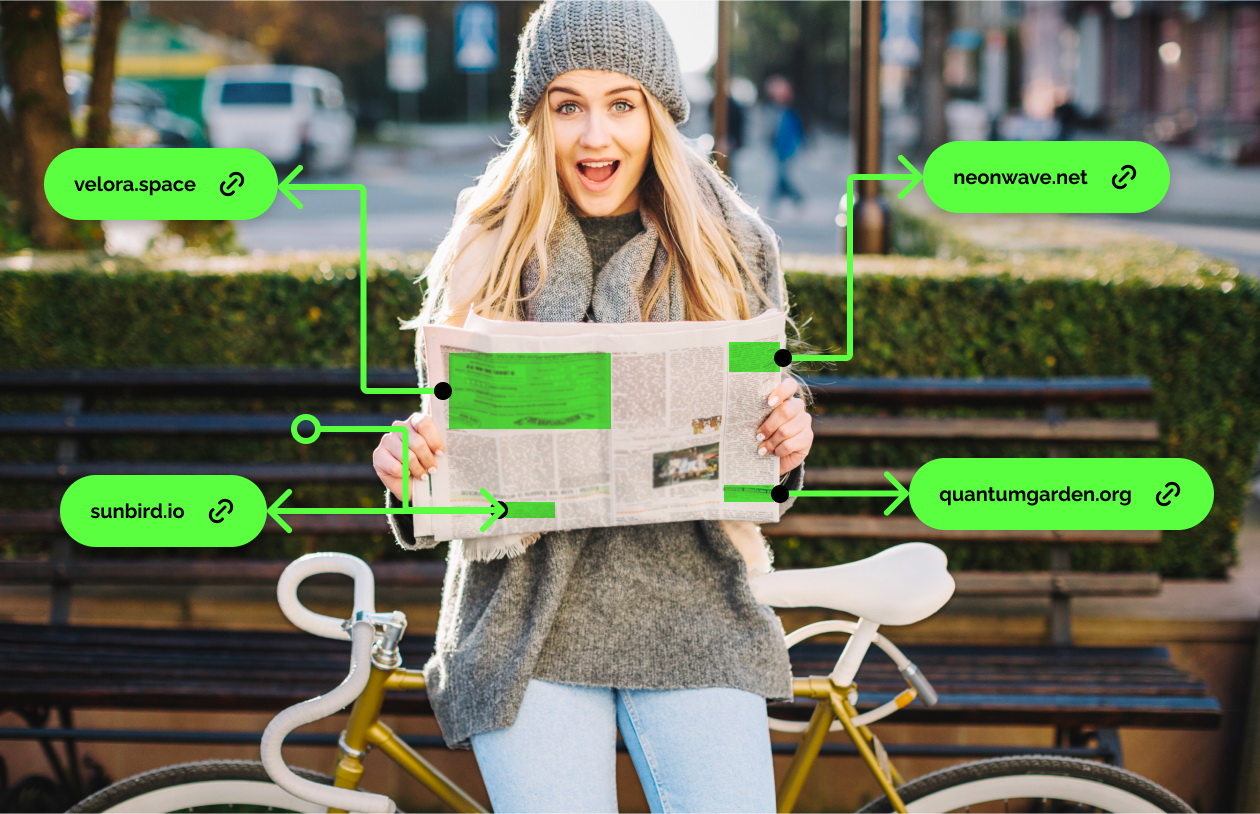
Ключевой вызов
Главная сложность для издателей — превратить статичный PDF в настоящий digital-канал быстро и без лишних затрат. Обычно рекламные макеты в электронных газетах отлично оформлены, но их нельзя сделать кликабельными, невозможно отследить эффективность рекламы и проанализировать вовлечённость аудитории.
Переход к интерактиву вручную связан с большими трудозатратами: на каждом выпуске приходится вручную выделять рекламные блоки, находить и встраивать ссылки, размечать зоны для кликов. Для регулярных изданий такой процесс становится слишком невыполнимым.
Нужно технологичное решение, которое позволит легко и массово добавить интерактив и аналитику в привычные PDF-газеты. Для решения этой задачи мы предложили применять искусственный интеллект.
Как ИИ может оживить газеты?
Всё начинается с того, что нейросеть учится отличать новости от рекламы. Зачем это нужно? Чтобы по каждой рекламе можно было узнать, кто её разместил и что именно предлагает, сопоставить с базой рекламодателей, а потом — быстро прописать ссылки прямо в PDF.

Алгоритм выглядит следующим:
- Для начала надо понять, где в газете новостные статьи, а где – рекламные блоки.
- Рекламные блоки необходимо распознать, чтобы понимать, какой рекламодатель и рекламное сообщение.
- И вот уже после того, как у нас есть на руках распознанные рекламные блоки, можно массово прописать рекламные ссылки по всем ним, сопоставляя тексты на рекламных блоках с базой рекламодателей по выпуску.
Самой сложной задачей из этого пайплайна считается распознавание газет – отделение различных по смыслу блоков друг от друга. Отсутствие стандартизации, случайная структура статей, обилие заголовков, подзаголовков и изображений делают точное распознавание газет сложной задачей.
У нас в Технологике было множество проектов по оцифровке западных и азиатских газет, где мы изучили не менее десятка подходов к распознаванию газетных статей. Здесь вкратце про три подхода: от самого простого и экономичного до самого точного и более дорогого.

Подход #1: в основе GPT-4o
Это самый простой и бюджетный подход, здесь мы применяем мультимодальную AI-модель от OpenAI GPT-4o.
Сначала с помощью OCR и Azure Document Intelligence извлекается текст и его координаты, чтобы восстановить структуру разворота. Далее текст автоматически сегментируется GPT-4o: модель определяет границы между статьями по семантическим признакам и делит страницу на публикации.
Такой метод быстро внедряется и дешев в реализации, но точность распознавания границ статей составляет около 85–90%, даже если имеются сканы газет высокого качества. Поэтому этот подход подходит для MVP и экспериментальных проектов, где высокая детализация не критична. Для задач, требующих почти идеальной разметки, вроде рекламных блоков, необходимы более сложные решения.
Подход #2: модель сегментации
Второй подход строится на детальном выделении текстовых и графических блоков на странице с помощью современной модели сегментации (например, YOLOv8-seg).
После сегментации для каждого блока извлекается текст, а затем для текста и изображений рассчитываются семантические вектора. Блоки группируются в статьи алгоритмами кластеризации — учитывается не только смысл, но и положение элементов на странице.
В результате для каждой найденной статьи и рекламного блока сохраняется изображение, полный текст и комбинированный вектор встраивания. Такой подход обеспечивает высокую точность и структурирование контента газеты.
Подход #3: модель сегментации мгновенного обнаружения
Третий подход предполагает применение предварительно обученной модели, способной сразу выделять на газетной странице целые статьи и рекламные блоки в единые объекты. Но это требует наличия большого размеченного датасета, на котором такую модель можно обучить.
После обнаружения статей для каждой извлекается полный текст и рассчитывается семантический вектор. В результате мы получаем максимально точное обнаружение границ статей и рекламных блоков.
Что дальше?
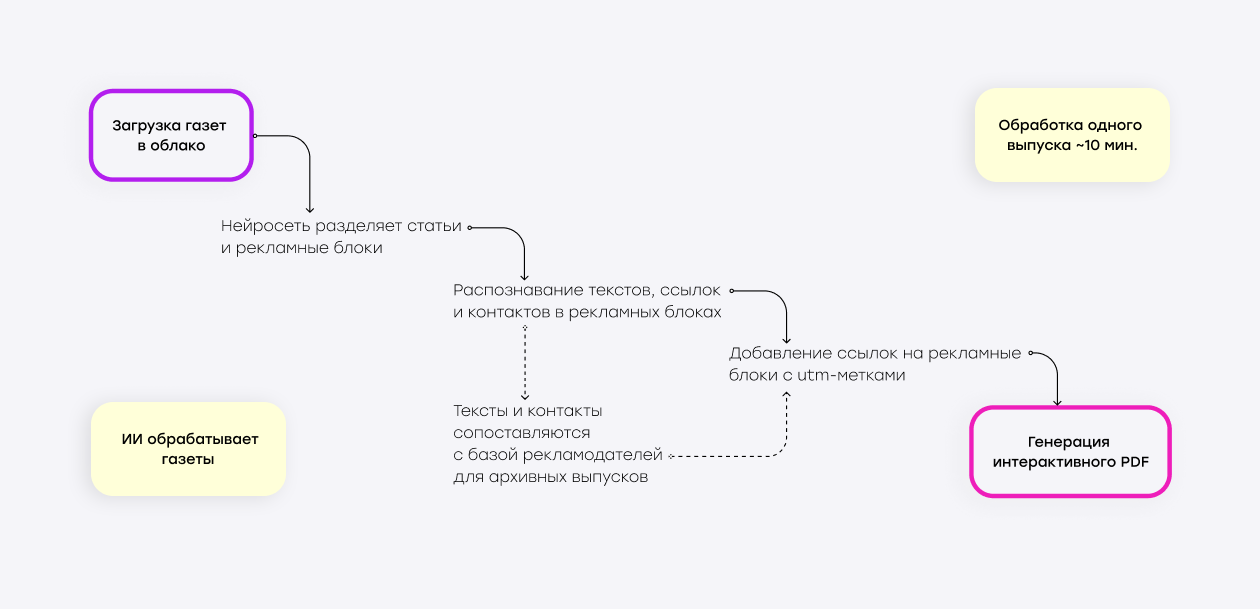
Полный алгоритм получается следующим:
- Загрузка газет в облако.
- Автоматическая сегментация страниц – с помощью нейросетей определяется рекламные блоки на каждой странице, вне зависимости от оформления дизайна и макета.
- Распознавание текстов, ссылок и контактов в рекламных блоках – языковые модели анализируют рекламный контент внутри каждого блока, распознают ссылки, номера телефонов и email-адреса.
- Всё найденное автоматически преобразуется в кликабельные элементы, если газета современная.
- Если речь про архивные газеты, то найденные блоки сопоставляются с базой рекламодателей и их рекламными объявлениями по каждому выпуску. А если такой базы нет, то можно заново продать рекламные места, предварительно связавшись с представителями брендов.
- Добавление интерактивных зон – на все рекламные блоки накладываются невидимые кликабельные области с прописанными utm-метками о каждом выпуске. Теперь пользователь может одним кликом перейти на сайт рекламодателя, а рекламодатель – отследить эффективность канала коммуникации.
- Генерация интерактивного PDF.
При таком подходе редакция получает дополнительный доход в виде новых рекламных мест, при этом затрачивая минимум ручного труда. Обработка выпуска занимает считанные минуты, отсутствуют ошибки в разметке и в ссылках.

Редакция получает инструмент, который делает её продукт привлекательнее и удобнее для читателей, а рекламные возможности — более гибкими, понятными и измеримыми.
Перспективы применения
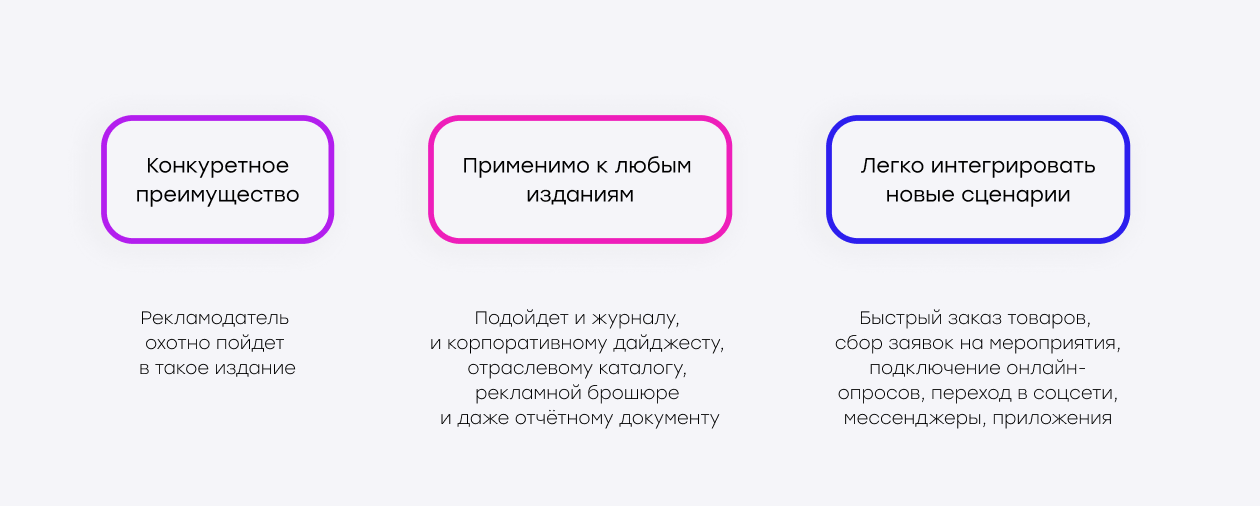
Автоматизация рекламы в PDF-изданиях открывает для редакций и рекламодателей гораздо более широкие горизонты, чем просто переход к digital-формату газет.
Это конкурентное преимущество. Ведь в условиях обостряющейся борьбы за рекламные бюджеты редакция или digital-агентство, предлагающее такие форматы, оказывается на шаг впереди. Рекламодателю становится проще принимать решение разместиться именно в таком издании.
Технологию можно легко интегрировать не только в газеты, но и в журналы, корпоративные дайджесты, отраслевые каталоги, рекламные брошюры и даже отчётные документы. Любой регулярный выпуск, где есть рекламные или информационные зоны, можно сделать интерактивным буквально “по щелчку”.
В такое решение можно легко добавить новые интерактивные сценарии: быстрый заказ товаров прямо из PDF, сбор заявок на мероприятия, подключение онлайн-опросов, встраивание ссылок на соцсети, мессенджеры, приложения.
Всё это превращает привычные PDF-документы в мощный и гибкий инструмент коммуникации, который может развиваться вместе с рынком и задачами бизнеса.
Будущее уже наступило
Время статичных PDF-изданий уходит. Их место занимает живой, гибкий канал, где реклама работает на результат, а читатели получают максимальное удобство. Описанный нами подход позволяет внедрить современные digital-функции быстро, без головной боли и вложений в собственные IT-команды.
Превратите ваше печатное издание PDF-формата в живой digital-канал уже сегодня.
Мы обучим ии-модель под ваше издание для автоматического распознавания рекламных блоков и добавления на них ссылок с UTM-метками.