Какая LLM лучше распознает чертежи? Мы сравнили 6 LLM и узнали ответ
Чертежи, даже выполненные по стандартам ISO или ГОСТ, редко бывают “идеально чистыми”. В одном документе могут соседствовать десятки форматов размеров (линейные, диаметральные, угловые, с односторонними или двусторонними допусками).
Добавьте сюда геометрические допуски, шероховатости, базовые и справочные размеры, и в этом чертеже сможет разобраться только инженер с опытом работы, но таких специалистов не так много. Поэтому автоматизация чертежей – важная задача для бизнеса.
За последние полтора года на рынке появилось поколение мультимодальных LLM, которые умеют работать не только с текстом, но и с графикой, в том числе с инженерными чертежами. Теоретически такие модели могут заменить специализированные OCR-решения и скрипты постобработки. Но как они ведут себя на реальных чертежах с плотной разметкой и сложными допусками? Мы провели исследование, чтобы ответить на этот вопрос.
В исследовании мы сравнили шесть актуальных vision-LLM на одном и том же наборе реальных механических чертежей.
Методология исследования
Тестовый набор
Для исследования мы подготовили набор из 10 реальных механических чертежей. Они различались по плотности аннотаций: от относительно “чистых” с 17 размерами до насыщенных схем с 58 измерениями. Мы сознательно выбрали сложные случаи, чтобы тест отражал условия, близкие к реальному производству.
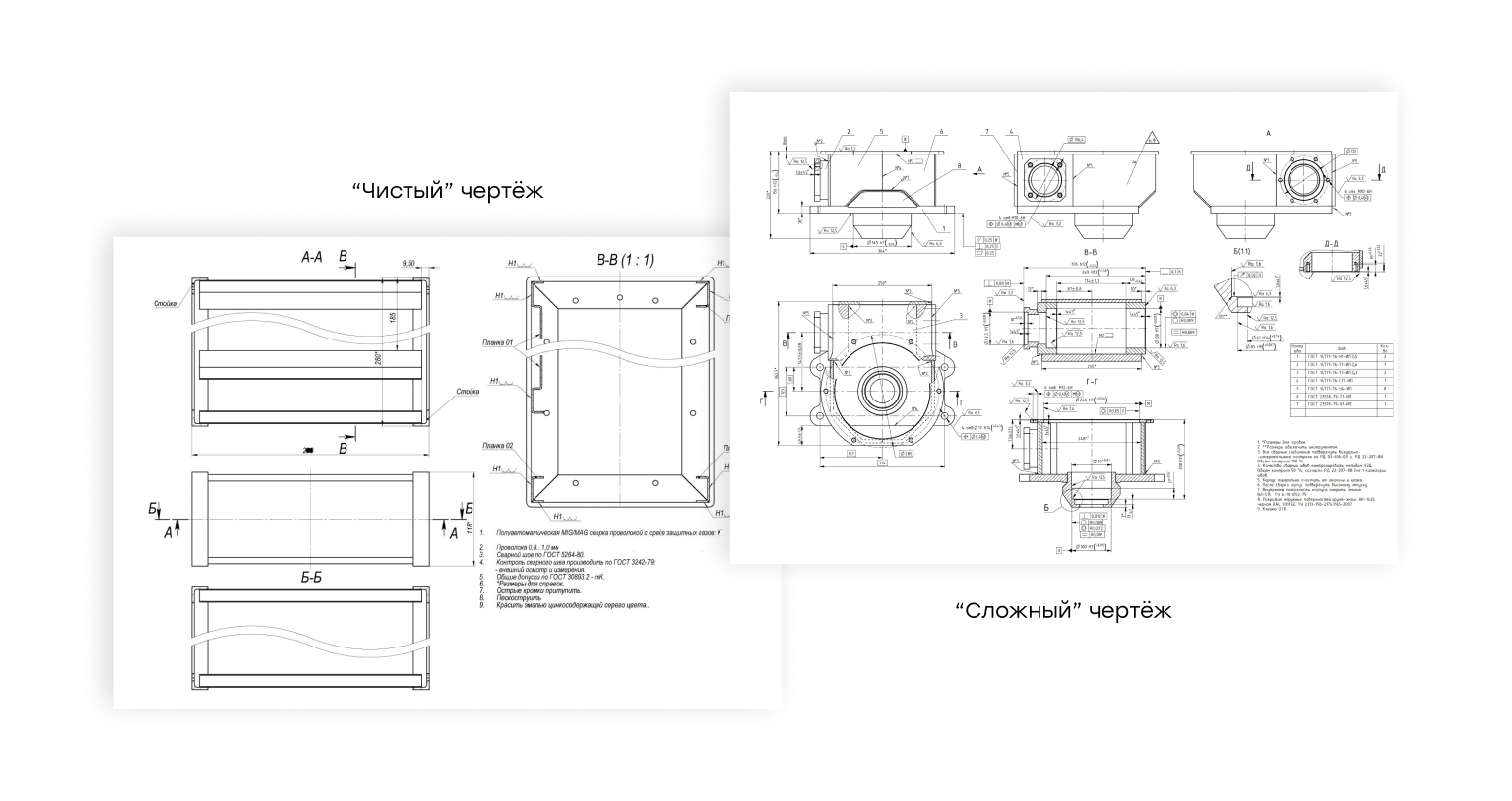
На чертежах встречались все основные типы размеров, которые можно ожидать в промышленной документации:
- Линейные (расстояния, высоты, глубины),
- Радиальные и диаметральные,
- Фаски и углы,
- Геометрические допуски — плоскостность, перпендикулярность, параллельность,
- Шероховатости поверхностей,
- Справочные и базовые размеры,
- Односторонние и двусторонние допуски.
Критерии оценки
Модель должна была извлечь полный набор ключевых полей для каждого размера:
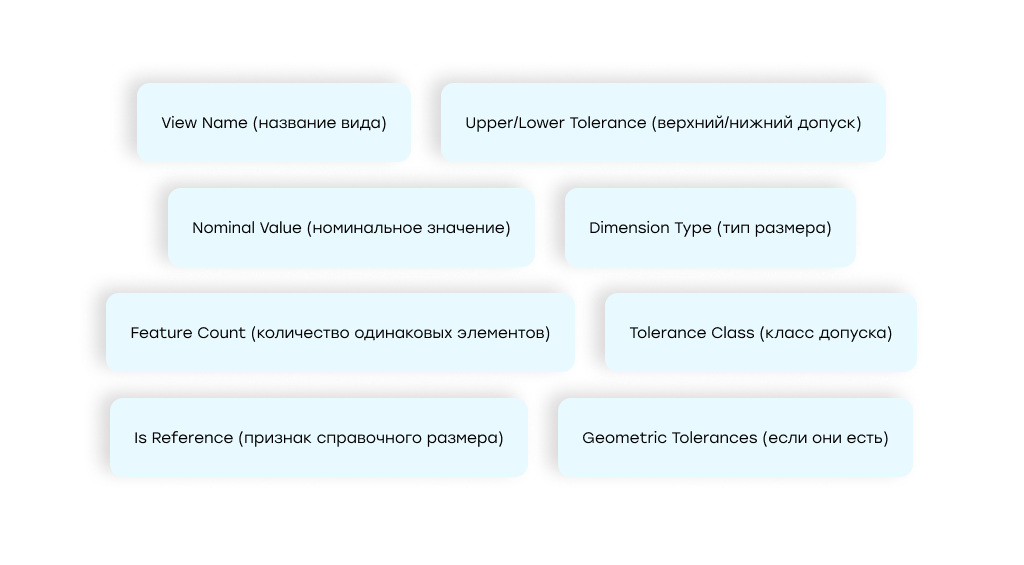
- View Name (название вида),
- Dimension Type (тип размера),
- Nominal Value (номинальное значение),
- Feature Count (количество одинаковых элементов),
- Upper/Lower Tolerance (верхний/нижний допуск),
- Tolerance Class (класс допуска),
- Is Reference (признак справочного размера),
- Geometric Tolerances (если они есть).
Поля вроде Dimension ID или текстовых примечаний мы в итоговую метрику не включали. Ошибки извлечения полей фиксировались, но не влияли на процент точности, поскольку они не мешают однозначно интерпретировать деталь.
Верификация велась вручную: каждая модель обрабатывала чертеж без дообучения, результат сравнивался с «эталонной» разметкой.
Попробуйте наше Демо!
Мы разработали сервис, в котором можно протестировать, как обученная нами AI-модель распознаёт ваши рабочие чертежи.
Что тестировали?
Мы начали с более широкого списка, включая GPT-4o, Grok 2 Vision и Pixtral Large, но ранняя проверка показала: с плотными чертежами справляются только самые мощные мультимодальные LLM, которые на момент исследования считались передовыми в работе с изображениями:

- Gemini 2.5 Flash — быстрая и относительно недорогая модель Google, оптимизированная для мультимодальной обработки.
- Gemini 2.5 Pro — «старший брат» Flash, с расширенными возможностями рассуждений.
- ChatGPT o4 mini — облегчённая версия GPT-4, с поддержкой анализа изображений.
- ChatGPT o3 — генерация GPT с визуальными возможностями.
- Claude Opus 4 — мультимодальный флагман Anthropic, ориентированный на точные ответы.
- Qwen VL Plus — модель Alibaba, сочетающая текстовое и визуальное восприятие.
А был ли ChatGPT 5?
На настоящий момент уже вышла ChatGPT 5, но на момент проведения исследования она еще была выпущена. В ближайшем будущем мы планируем протестировать качество извлечения данных на новых поколениях моделей и на том же наборе документов.
Какой был промт?
PROMPT_TABLE_EXTRACTION = """ Act as a meticulous Quality Control Engineer and Metrology expert. Your task is to perform a complete and exhaustive analysis of the provided multi-sheet engineering blueprint and extract ALL specified information into a single, highly structured JSON object. The output must be a single, well-formed JSON object. The top-level keys of this JSON object should be strings representing the names of the different views, sections, and details from the drawing. Crucially, include the scale and any applicability notes in the view name (e.g., "Section B-B (2.5:1) (2 places)", "Detail M (20:1)"). The value for each view key must be an array of objects. Each object in the array represents a single, complete dimensional callout or specification found within that view. Each dimension object must adhere to the following detailed schema: * id (string or null): The identifier from the drawing, if present (e.g., "DIM44"). Use null if not present. * dimension_type (string): The type of dimension. Must be one of: linear, diameter, radius, angle, chamfer, thread, surface_roughness. * nominal_value (number or string): The primary numerical value of the dimension (e.g., 17, 3.2, M3). * feature_description (string or null): A brief text description of the feature (e.g., "holes", "slots", "septum surface"). * feature_count (integer or null): The number of identical features this dimension applies to (e.g., for "8 отв.", this would be 8). If not specified, use null. * upper_tolerance (number or null): The numerical upper tolerance value (e.g., 0.02). * lower_tolerance (number or null): The numerical lower tolerance value (e.g., -0.02). * tolerance_class (string or null): The alphanumeric tolerance class (e.g., "H7", "F7", "6H"). * is_reference (boolean): Set to true if the dimension is marked as a reference dimension (typically with an asterisk *), false otherwise. * notes (string or null): Any additional notes directly associated with the dimension, such as thread depth (e.g., "depth 7.5-8mm"). * geometric_tolerances (array of objects or null): An array to capture all geometric dimensioning and tolerancing (GD&T) frames associated with this feature. Each object in the array should have: * type (string): The type of geometric control (e.g., position, perpendicularity, parallelism, flatness, total_runout). * value (number): The tolerance value (e.g., 0.05). * datums (array of strings): An array of the datum references (e.g., ["Д", "Г"], ["M"]). * zone_modifier (string or null): Any material condition modifier on the tolerance value, if present (e.g., M for Maximum Material Condition). Additional Instructions: 1. Be Exhaustive: Do not skip any information. Every number, symbol, and note on the drawing is important. 2. View Naming: Be precise with view names. For the main, unlabelled views, use standard names like "Main Front View", "Main Top View". For labeled views, use their labels and add scale/context, like "Section A-A", "View B (2.5:1)". 3. General Notes & Title Block: Create two separate top-level keys: * general_notes: An array of strings containing all numbered or general notes from the drawing. Translate key technical terms if possible but preserve the original text. * title_block: An object containing key information from the title block, such as part_number, part_name, material, mass, and scale. 4. Surface Finish: Global surface finish symbols (like Ra 3.2 (?)) should be captured in general_notes. Local surface finish symbols should be treated as a feature within their respective view. Example of desired JSON structure based on the provided complex drawing: Generated json { "title_block": { "part_name": "Вед. инж.", "material": "АМг6 ГОСТ 4784-2019", "mass": "101.39 г", "scale": "2:1", "part_number": null }, "Main Front View": [ { "id": "DIM11", "dimension_type": "diameter", "nominal_value": 3.2, "feature_description": "holes", "feature_count": 8, "upper_tolerance": null, "lower_tolerance": null, "tolerance_class": null, "is_reference": false, "notes": null, "geometric_tolerances": null }, { "id": "DIM7", "dimension_type": "diameter", "nominal_value": 1.5, "feature_description": "holes", "feature_count": 2, "upper_tolerance": 0.015, "lower_tolerance": 0.006, "tolerance_class": "F7", "is_reference": false, "notes": null, "geometric_tolerances": [ { "type": "position", "value": 0.02, "datums": ["Д", "Л"], "zone_modifier": "M" } ] }, { "id": "DIM4", "dimension_type": "linear", "nominal_value": 5.8, "feature_description": null, "feature_count": null, "upper_tolerance": 0.018, "lower_tolerance": 0, "tolerance_class": null, "is_reference": true, "notes": null, "geometric_tolerances": null } ], "Section B-B (2.5:1) (2 places)": [ { "id": "DIM27", "dimension_type": "thread", "nominal_value": "M3", "feature_description": "threaded holes", "feature_count": 4, "upper_tolerance": null, "lower_tolerance": null, "tolerance_class": "6H", "is_reference": false, "notes": "depth 7.5-8mm", "geometric_tolerances": null } ], "general_notes": [ "1. * Размеры для справок.", "2. Общие допуски по ГОСТ 30893.1: H12, h12, ±IT12/2.", "3. Общие допуски формы и расположения - ГОСТл 30893.2-Н.", "4. Неуказанные размеры согласно CAD модели.", "7. Шероховатость поверхностей внутренних каналов и фланцев — Ra 1,6.", "8. Покрытие Хим. Н9.МЗ.Ср6.", "9. Допускается отсутствие покрытия в резьбовых отверстиях.", "10. Маркировать 02 согласно СТП-3.", "11. Допуск по массе согласно СТП-4.", "Global surface roughness: Ra 3.2" ] } """
Результаты: общий рейтинг
После обработки всех 10 чертежей мы получили достаточно контрастную картину. Лидеры уверенно оторвались от остальных, а слабые модели показали результат, близкий к случайным угадываниям.
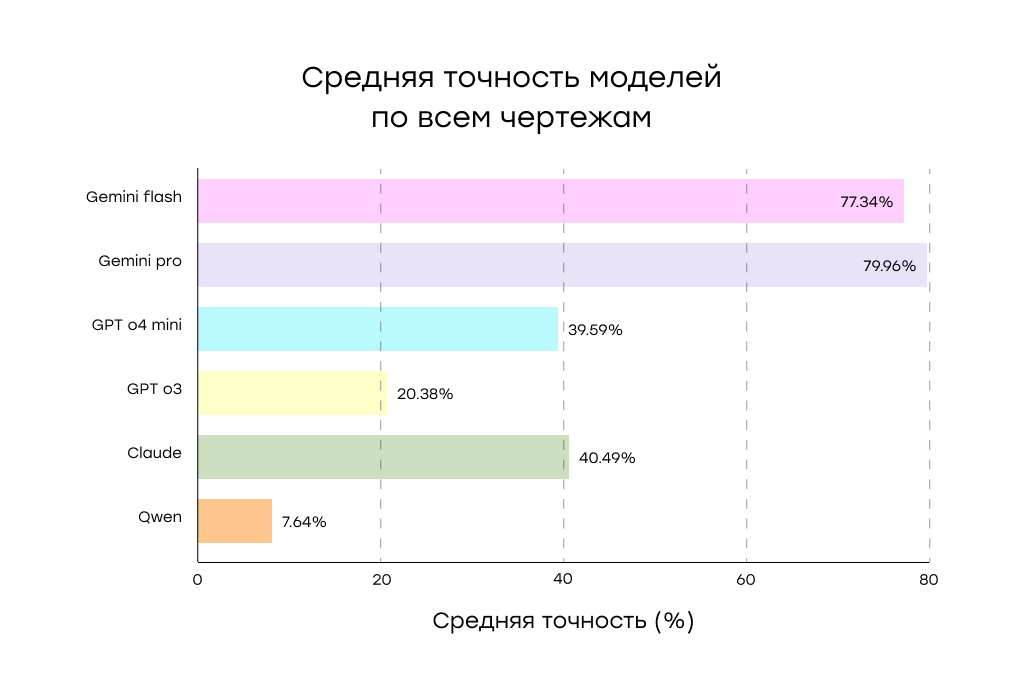
Краткий рейтинг по средней точности извлечения:
- Gemini 2.5 Pro — ~80%
- Gemini 2.5 Flash — ~77%
- Claude Opus 4 — ~40%
- ChatGPT o4 mini — ~39,6%
- ChatGPT o3 — ~20%
- Qwen VL Plus — ~8%
Но мы знаем, как вы любите таблицы, поэтому показываем вам результаты по каждой модели по каждому документу:
| Чертеж | Кол-во измерений | Gemini flash | Gemini pro | Gpt o4 mini | Gpt o3 | Claude | Qwen |
| 1 | 47 | 97,87% | 85,11% | 55,32% | 19,15% | 40,43% | 4,26% |
| 2 | 49 | 95,92% | 95,92% | 40,82% | 24,49% | 38,78% | 14,29% |
| 3 | 58 | 86,21% | 86,21% | 5,17% | 0,00% | 29,31% | 6,90% |
| 4 | 17 | 88,24% | 82,35% | 70,59% | 17,65% | 45,83% | 0,00% |
| 5 | 42 | 40,48% | 97,62% | 33,33% | 26,19% | 69,05% | 9,52% |
| 6 | 48 | 83,33% | 66,67% | 47,92% | 16,67% | 33,33% | 10,42% |
| 7 | 53 | 79,25% | 67,92% | 50,94% | 13,21% | 18,87% | 7,55% |
| 8 | 41 | 60,98% | 60,98% | 17,07% | 12,20% | 34,15% | 2,44% |
| 9 | 29 | 72,41% | 72,41% | 31,03% | 58,62% | 48,28% | 13,79% |
| 10 | 32 | 68,75% | 84,38% | 43,75% | 15,63% | 46,88% | 3,13% |
| Среднее | 77,34% | 79,96% | 39,59% | 20,38% | 40,49% | 7,23% |
Ключевые наблюдения:
- Gemini Pro и Gemini Flash продемонстрировали стабильность даже на сложных чертежах и уверенно извлекали не только линейные размеры, но и допуски.
- Claude и GPT o4 mini чувствовали себя неплохо на “чистых” чертежах, но заметно теряли точность при высокой плотности аннотаций.
- GPT o3 показал базовый уровень — половину размеров не извлек.
- Qwen фактически не справился с задачей, часто пропуская целые проекции или разделы чертежа.
Разбор ошибок
Анализ ошибок показал, что модели “спотыкались” на разных этапах понимания чертежа. И это тоже интересно проанализировать.
Общие сложности для всех моделей
Общие сложности для всех моделей – отдельные геометрические допуски (плоскостность, перпендикулярность, параллельность). Они часто либо пропускались, либо определялись неверно.
Характерные проблемы по моделям
- GPT o3 часто не находила идентификаторы размеров (например, DIM11) или привязывал их к неверным элементам. Это снижает трассируемость и мешает верификации в системах контроля качества.
- Gemini Flash:
- На чертеже №5 точность упала до 40% из-за ошибок в интерпретации формата допусков.
- При одностороннем допуске модель часто “додумывала” второй допуск, которого в оригинале не было.
- Gemini Pro и GPT o4 mini иногда объединяли одинаковые размеры в один пункт, изменяя Feature Count (например, вместо пяти одинаковых отверстий фиксировали одно).
- GPT o4 mini и GPT o3 периодически путали верхний и нижний допуски.
- Qwen VL Plus не делил чертёж на проекции, из-за чего терялись контекстно-зависимые размеры.
- Claude Opus 4 и Qwen иногда относили размер к неправильной проекции или секции в многоракурсных чертежах.
Неожиданные находки
Исследование показало несколько интересных моментов, которые могут быть полезны тем, кто планирует внедрять автоматическую обработку чертежей:
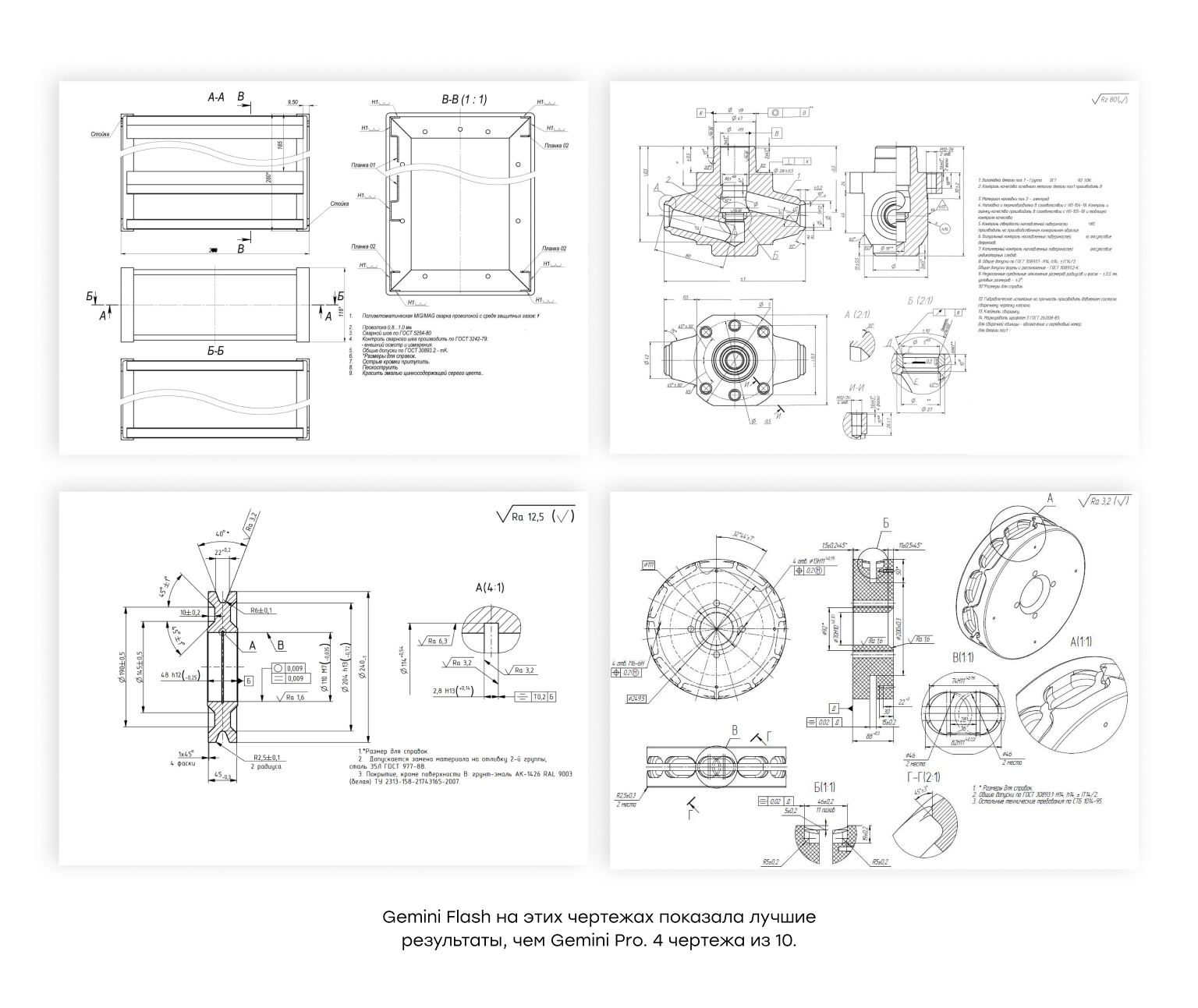
1. “Облегчённая” модель иногда лучше pro-версии Хотя Gemini Pro в среднем показывал лучшую точность, на отдельных чертежах его обгонял Gemini Flash. Скорее всего это говорит о том, что модель с расширенными возможностями рассуждений выдает результат с более высоким уровнем уверенности, в то время как более слабая модель выдает в целом больше результатов, даже с низким уровнем уверенности в них
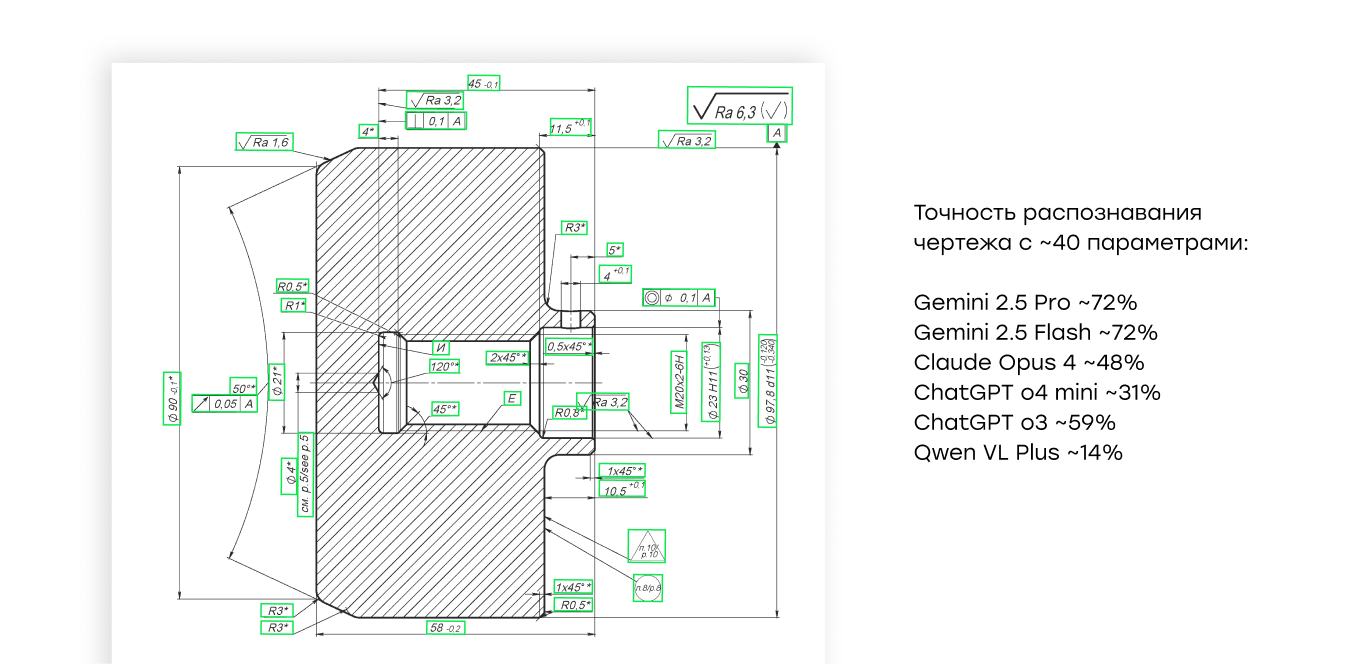
2. Сложность чертежа не всегда коррелирует с результатом Мы ожидали, что чем больше на чертеже размеров и допусков, тем ниже будет точность. Но в реальности многие модели показывали схожий процент извлечения и на «чистых» чертежах, и на документах с высокой плотностью аннотаций. Это значит, что ключевым фактором могут быть не количество размеров, а стиль оформления и единообразие обозначений.
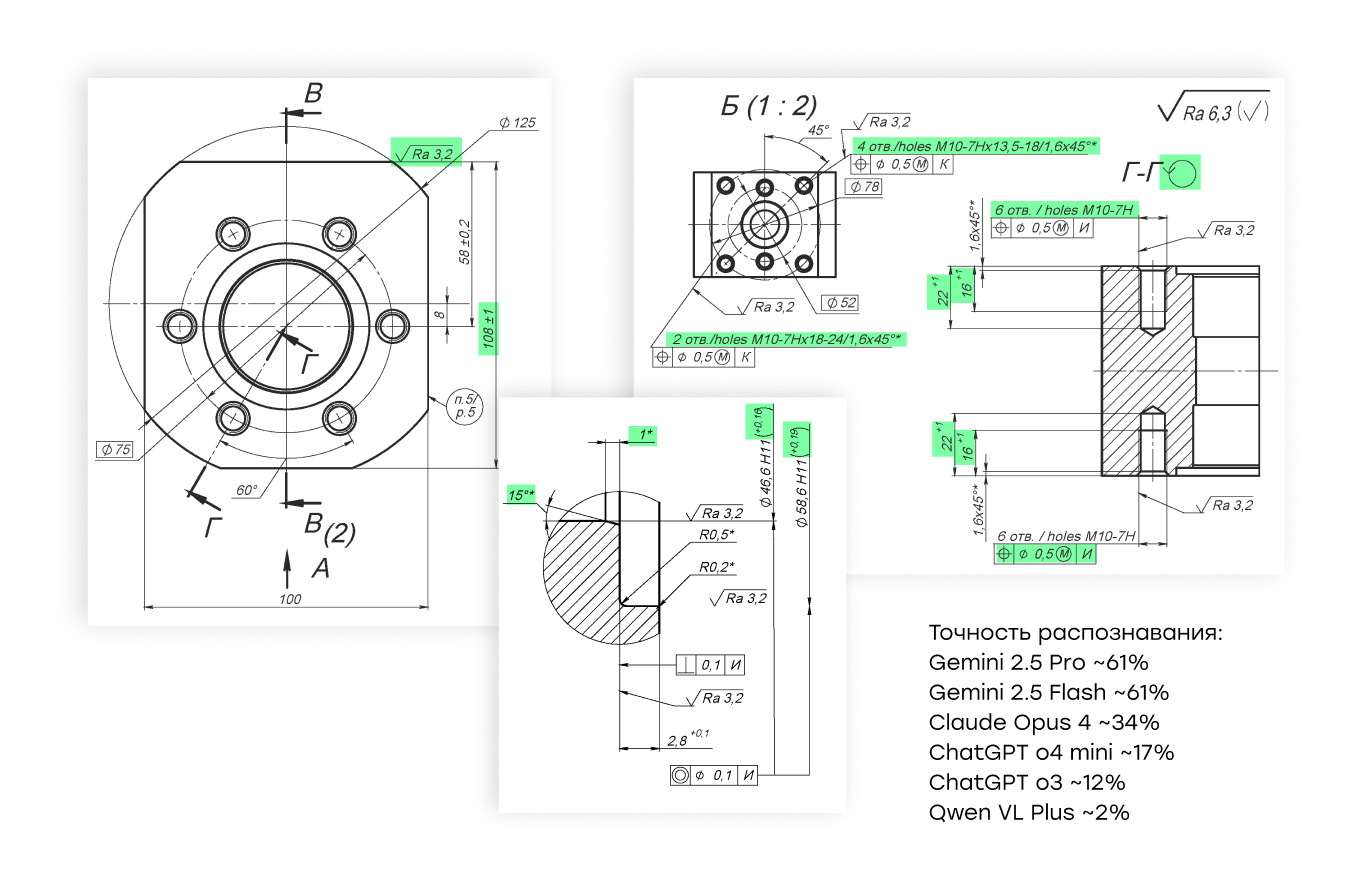
3. Узкие места одинаковы для всех Независимо от архитектуры модели, все испытывали трудности с отдельными геометрическими допусками и нестандартными форматами. Это — зона для кастомизации и настройки пайплайнов, если нужна 100% точность.
Рекомендации по улучшению точности
Поскольку ни одна модель не смогла извлечь все размеры из всех чертежей, мы предлагаем два практических подхода, которые могут заметно повысить качество:
1. Ансамбль моделей
Идея проста – обрабатываем один и тот же чертёж сразу несколькими моделями и объединяем результаты. Совмещение результатов позволяет существенно повысить полноту извлечения без ручного ввода.
Например, Gemini Pro может надёжно вытягивать геометрические допуски, а GPT o4 mini — лучше распознавать линейные размеры с Feature Count.
2. Итеративная прогонка одного чертежа
Даже одна и та же модель может при повторном запуске (с небольшими изменениями в формулировке промпта или параметрах) «увидеть» то, что пропустила раньше.
Собирая результаты нескольких прогонов, можно закрыть многие пропуски, особенно по сложным или плохо читаемым элементам.
Как применять
Оба подхода можно комбинировать:
- Сначала прогонять документ через несколько моделей,
- Затем каждую из них запускать по 2–3 раза с разными настройками.
Да, это увеличивает затраты на обработку, но в случаях, где важна максимальная полнота (например, при формировании производственных спецификаций и карт замеров), это оправдано.
Попробуйте наше Демо!
Мы разработали сервис, в котором можно протестировать, как обученная нами AI-модель распознаёт ваши рабочие чертежи.
Производительность и стоимость
Точность — это не единственный параметр, который важно учитывать при выборе модели. Также роль играют и время обработки, и стоимость на больших объёмах.
Мы сравнили, сколько в среднем занимает распознавание одной страницы чертежа и во сколько обойдётся обработка 1000 страниц (по состоянию на момент теста):
| Модель | Время обработки, сек/стр | Стоимость за 1000 стр. (USD) |
| Gemini 2.5 Flash | 77,5 | 30,5 |
| Gemini 2.5 Pro | 91,4 | 130,4 |
| ChatGPT o4 mini | 41,75 | 24,9 |
| ChatGPT o3 | 163 | 239,2 |
| Claude Opus 4 | 64,8 | 312 |
| Qwen VL Plus | 22 | 1,59 |
Ключевые наблюдения:
- Самая быстрая — Qwen VL Plus (22 сек/стр), но при этом её точность делает применение в реальных сценариях сомнительным.
- Оптимальный баланс точности и цены в нашем тесте был у Gemini Flash — хорошая скорость, высокая точность и низкая стоимость.
- Claude Opus 4 дорогая, но не лидирует по точности — использовать её имеет смысл только там, где важны особые сценарии и высокая надёжность в «чистых» чертежах.
- GPT o3 — самая медленная и не оправдывает свою цену качеством извлечения.
Заключение
Наше тестирование показало, что автоматическое извлечение размеров из инженерных чертежей уже сегодня возможно без дообучения модели, но с оговорками:
- Даже лидеры (Gemini Pro, Gemini Flash) не дают 100% точности,
- Отдельные форматы допусков и нестандартные обозначения по-прежнему вызывают сбои,
- Сложность чертежа сама по себе не всегда влияет на результат — важнее стандартизированность оформления.

А значит:
- Если вам нужна высокая полнота извлечения, стоит сразу закладывать использование ансамбля моделей или итеративной обработки.
- На массовых объёмах лучше выбирать модель с оптимальным балансом точности, скорости и цены — в нашем случае это Gemini Flash.
- Даже при высоких показателях извлечения нужно предусматривать верификацию человеком для критически важных размеров и допусков.
В ближайшей перспективе мультимодальные LLM могут стать реальной альтернативой специализированным системам распознавания чертежей. Но в сценарии “из коробки” их использовать рано. В промышленном использовании нужна интеграция в продуманный пайплайн с контролем качества.
Сегодня мы видим, что мультимодальные модели научились «читать» инженерные чертежи на уровне, достаточном для пилотных проектов. Завтра, с приходом новых поколений LLM, этот уровень будет только расти.
Хотите заказать решение для обработки чертежей?
Напишите нам!
И мы разработаем решение для обработки ваших чертежей!