Papers, please! Как устроены сервисы по распознаванию лиц для идентификации клиента и проверки документов
В популярной в свое время игре Papers, please! игрок выполняет роль таможенника, проверяющего документы по все более усложняющимся правилам. Главная игровая механика - проверка документов на соответствие всем нормам, таким как верная дата и место выдачи, соответствие имени и фамилии человека на всех документах, срок действия визы, наличие человека в “черных” списках и тому подобное.
Игра привлекла тысячи пользователей по всему миру самобытным стилем и необычной механикой игры, однако для некоторых людей подобная игра показалась бы настоящим кошмаром, ведь в реальной жизни, на своей реальной работе они занимаются тем же самым.
KYC и кому оно нужно
Аббревиатура KYC означает know your customer и дословно переводится как “знай своего клиента”, означая при этом идентификацию клиента в широком смысле слова. Всесторонняя проверка человека, включая его документы, банковскую историю и даже активность в социальных сетях входит в стандартный набор KYC практик, которые направлены на получение как можно большего количества информации о клиенте для снижения рисков, которые для каждого бизнеса могут быть свои.
Так, сотрудник банка вынужден проверять не только предоставленные клиентом документы, но и “стучаться” в соответствующие инстанции, чтобы узнать, насколько человек добропорядочен и с какой вероятностью он вернет полученные в кредит деньги, и анализировать его поведенческие особенности, например, его деятельность в социальных сетях и выражение лица на встрече.
Менеджеры онлайн сервисов, таких как онлайн-магазины и букинг-сайты, с другой стороны, не имеют потребности в анализе кредитной истории пользователя, но им важно знать, что их клиент не пользуется разными лазейками, например, не регистрируется несколько раз подряд, используя временный email, чтобы воспользоваться акцией, или не регистрирует очередной аккаунт, чтобы оставить негативный отзыв с целью понизить рейтинг сервиса.
Некоторым бизнесам, например, каршерингам и любым uber-like сервисам, важно знать, кто именно пользуется их услугами (или предоставляет их). Яндекс.Такси важно знать, кто именно был за рулем машины, когда та попала в аварию, а Whoosh очень хотелось бы знать кто именно приватизировал их самокат.
Криптобиржи, несмотря на отторжение практически любых постановлений, направленных в их сторону, вынуждены обращаться к KYC практикам для идентификации клиентов из-за местного и глобального правового давления. Например, для регистрации на Binance нужно не только ввести данные о своем имени и дате рождения, но и отправить фото документа, удостоверяющего личность, загрузить селфи и пройти проверку лица с помощью веб-камеры.
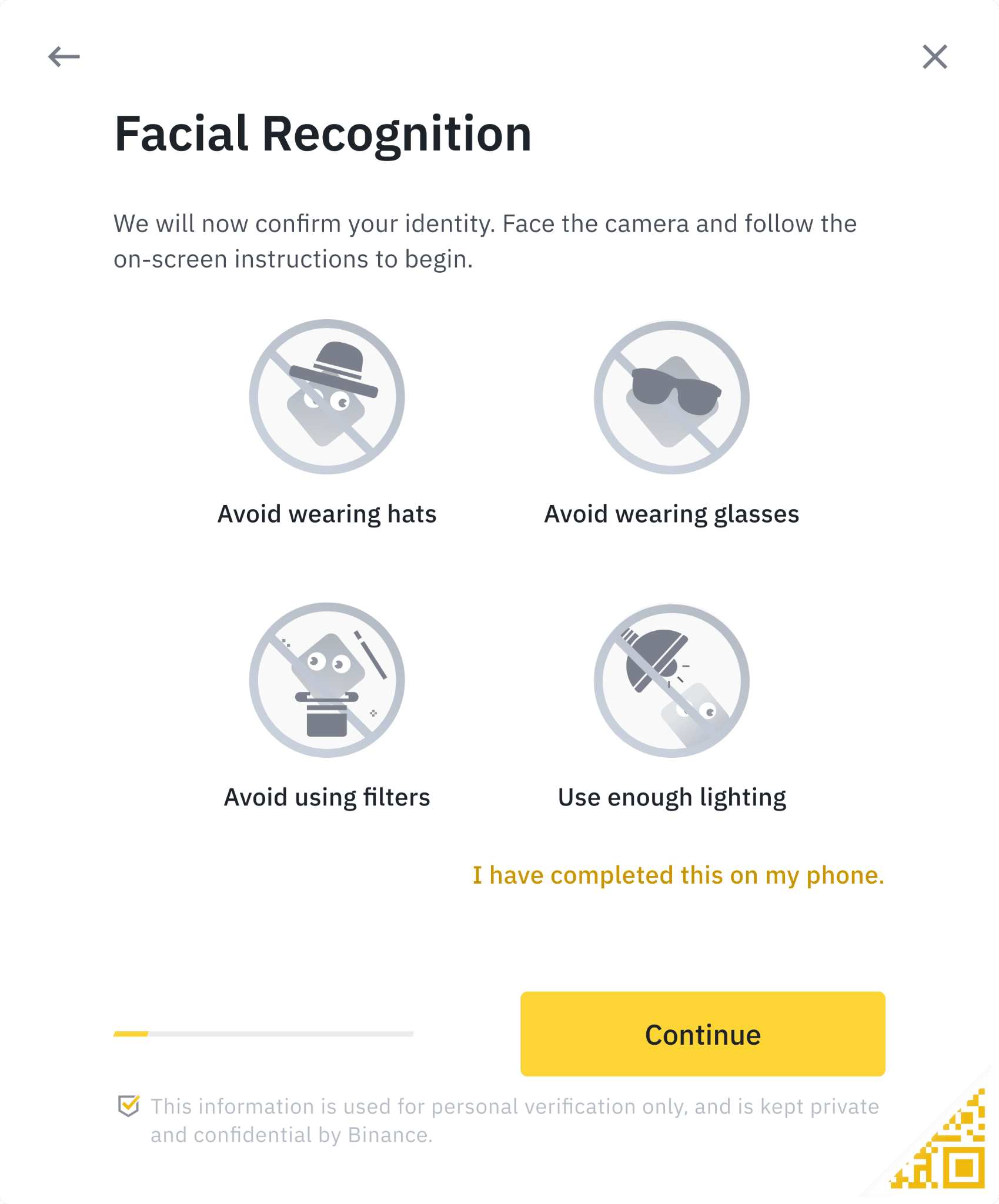
Сайты и приложения для онлайн-знакомств тоже стремятся внедрить как можно больше KYC практик в процесс регистрации аккаунта, чтобы избежать кэтфишинга, ведь это явление может сильно снизить количество пользователей и подорвать репутацию сервиса.
Как это обычно работает
KYC меры, на самом деле, часто имеют очень простой вид, как для клиента, так и для того, кто их реализует. Например, верификация электронной почты через письмо с кодом или номера телефона через sms является самым простым (и самым ненадежным) примером KYC.
Такие меры легко поддаются злоупотреблению - наверное все знают о сервисах временных email-ов, с помощью которых можно бесконечное количество раз регистрироваться в системе (что бывает очень полезно для бесконечного продления бесплатного периода использования сервиса, например).
Подобных мер для бизнесов, дорожащих своей пользовательской базой, недостаточно. Рассмотрим несколько вариантов усложнений проверки пользователя на этапе регистрации.
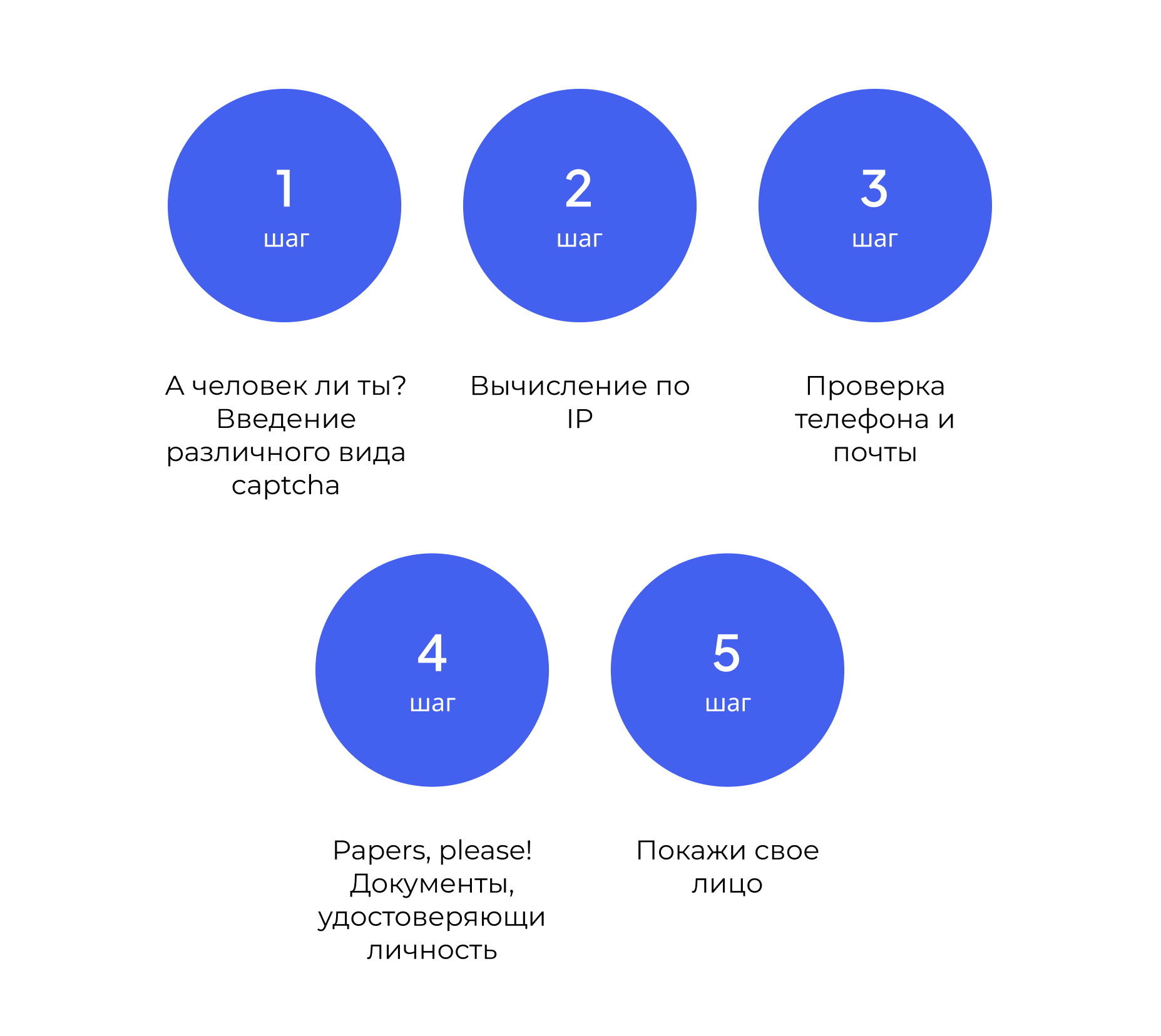
Шаг 1: А человек ли ты?
Самым простым усложнением является внедрение Captcha, что по крайней мере частично решает проблему с массовой регистрацией ботов. Сделать это очень просто, дешево и достаточно эффективно, и результат - снижение количества ботов - виден почти сразу. Однако одной Captcha не решить проблему мультиаккаунтов - ситуации, когда один человек регистрируется в системе несколько раз со злым умыслом.
Шаг 2: Вычисление по IP
Угрозы в интернете, основанные на вычислении обидчика по IP, для многих онлайн-сервисов - реальность. Если разные пользователи регулярно логинятся в ваш сервис с одного и того же IP, это может вызвать сомнение в их добропорядочности и целях использования сервиса. Кроме того, проверяются IP известных VPN сервисов и подключение к сети TOR. После вычисления по IP следует жестокая расправа блокировка аккаунта.
Шаг 3: Проверка телефона и почты
Тут уже речь идет не о проверке доступа пользователя к указанному номеру телефона и адресу почты, а более глубокая проверка данных. Проверяются валидность домена почты, дата создания адреса, связь с аккаунтами в социальных сетях.
Номер телефона тоже может дать довольно много полезных данных, например, оператор сотовой связи, страна, связь с социальными сетями. Так можно вычислить тех, кто создал почту только для регистрации или использует одноразовый телефон.
Шаг 4: Papers, please!
Данный этап усиления проверки значительно увеличивает количество шагов при регистрации для пользователя, но повышает надежность сервиса и значительно снижает количество недобросовестных пользователей внутри него. Человека просят предоставить документ, удостоверяющий личность, и ввести его данные при регистрации.
Проверка валидности подобных данных - дело не самое сложное, ведь как правило данные о действительных и недействительных паспортах доступны онлайн. Энтузиасты могут даже ввести интеграцию с Госуслугами.
Шаг 5: Покажи свое лицо
На предыдущем шаге все еще остается место для лазеек. Ничего не мешает пользователю, забаненному на определенном сервисе, но горячо желающему продолжить им пользоваться, одолжить паспорт у ничего не подозревающей бабушки и ввести ее данные при регистрации второго аккаунта. Данная ситуация крайне неприятна для сервисов, стремящихся сохранить чистоту своей пользовательской базы, в связи с чем существует дополнительный этап - распознавание лица.
Удобнее всего вводить распознавание лица в мобильное приложение. При регистрации пользователь вводит свои паспортные данные, делает фотографию самого паспорта, а затем система просит его немного покривляться перед фронтальной камерой, отвлекая его от процесса распознавания лица, в течение которого выполняется:
Сравнение с фотографией на предоставленном паспорте, чтобы определить действительно ли это паспорт нового пользователя (или бабушка все еще ни о чем не подозревает); Сравнение с базой лиц уже зарегистрированных пользователей, чтобы человек не регистрировался несколько раз, используя разные документы; Проверка на liveness, т.е. проверяется, что перед камерой реальный человек, а не его фото или видео;
Как мы внедрили KYC в мобильное приложение
Тут появляемся мы - разработчики приложение для эффективной и быстрой проверки пользователя во время регистрации с помощью мобильного телефона. Наш клиент поставил перед нами задачу реализовать сложную проверку пользователя с помощью смартфона, и мы справились.
Мы разработали приложение, которое сканирует лицо пользователя и сравнивает его с фотографией на предоставленном документе, будь то паспорт, водительские права или пропуск, а также делает liveness проверку, т.е. проверяет реальность человека перед камерой, предлагая ему выполнить несколько простых жестов: повороты головы и подмигивания. Бонусом приложение сканирует сфотографированный документ и выгружает из него важные данные - имя и фамилия, дата рождения, пол, номер и серия документа.
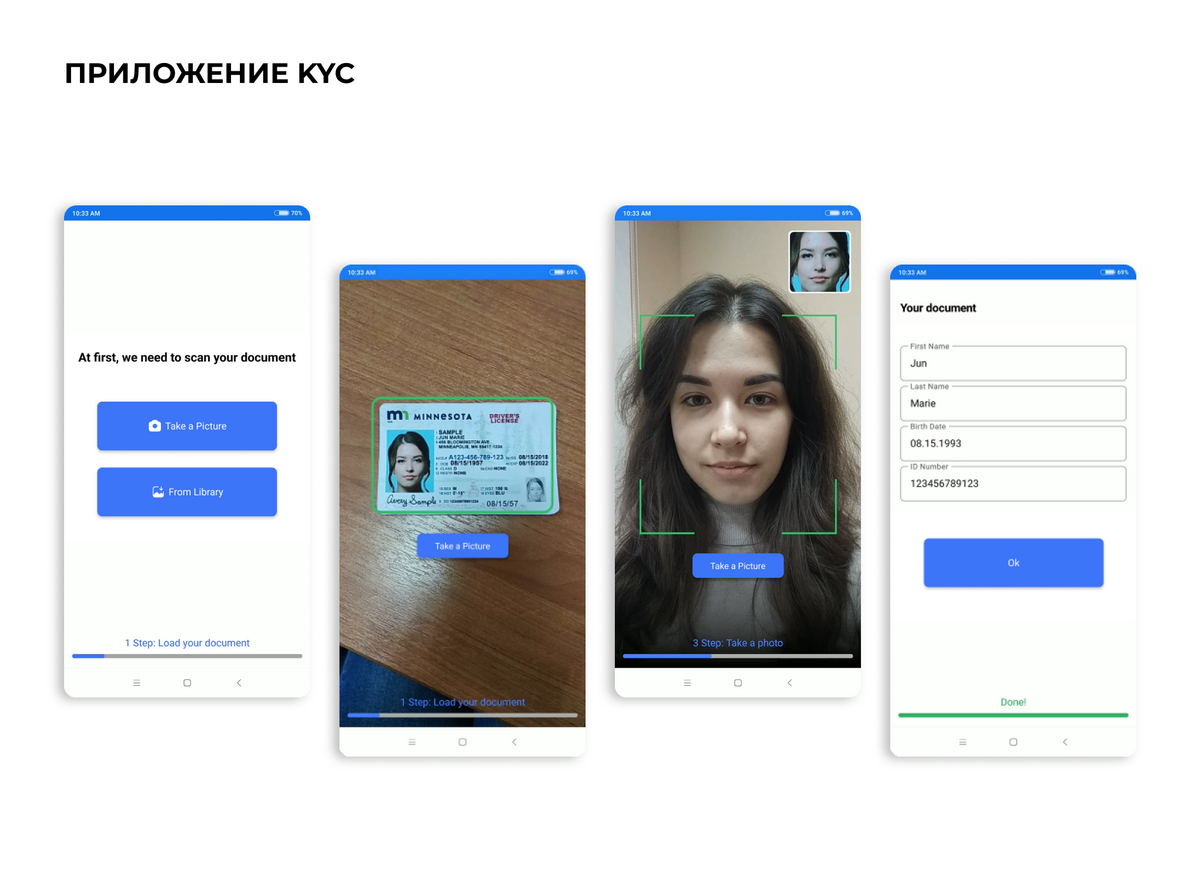
Нашей главной задачей было не просто создать сервис по проверке документов, а суметь реализовать удобное и быстрое приложение, которое бы упрощало процесс регистрации, а не наоборот. Каждый шаг - от фотографирования документа до подтверждения личности - должен быть интуитивно понятным, проходить быстро и без запинок.
Наша задача состояла из двух частей: реализация распознавания паспортов и распознавания лиц.
Распознавание паспортов
Основным инструментом для распознавания документов стал Google Vision API, распознающий текст на любом языке и создающий bounding box вокруг каждого слова. Данный сервис условно бесплатен и позволяет сканировать до 1000 изображений в месяц без оплаты. Гугл мы тренировали на румынских паспортах: именно их почему-то больше всего в интернете.
Для начала, на предоставленном пользователем фото паспорта мы с помощью OpenCV определяем контур паспорта, его “рабочую область”. Данное выделение не всегда может проходить гладко, например, если фото сделано на пестром фоне или рядом есть другие объекты. В таком случае мы находим самый большой контур и считаем, что это и есть паспорт.
Полученное изображение передается Google Vision, который определяет и выделяет отдельно каждое слово. После этого выполняется поиск ключевых слов, которыми в данном случае являются названия полей: “Имя”, “Фамилия”, “Место рождения” и прочее.
В мире ~193 страны, и каждая из них выпускает паспорта с теми данными, которыми захочет. Ключевые слова для каждого вида ID могут быть разными и находиться в разных местах. Для решения нашей задачи было целесообразно (и достаточно) вручную собрать ключевые слова с паспортов тех стран, которые были нам интересны. Однако если бы мы разрабатывали приложение-космополит, то здесь нужно было бы искать другой подход.

Для каждого типа паспорта (в нашем случае тип - это страна) существует конфигурационный файл, в котором заданы:
Ключевые слова, т.е. названия полей
Пробелы и межстрочные интервалы
Немного о пробелах
Думаете, что страны отличаются друг от друга культурой, историей, своим народом? Нет, они отличаются размером пробелов и межстрочных интервалов в паспортах своих граждан. Например, в румынских паспортах пробелы короткие, а в шведских - большие. Размер пробелов важен нам для поиска значения ключевых слов: после того, как находится ключевое слово, система ищет его значение, которое может быть как справа от ключевого слова, так и снизу.

Зная размер пробелов и межстрочных интервалов паспортов определенного типа, мы знаем, насколько нужно отступить вправо или вниз для поиска значения ключевого слова. Размер пробелов и интервалов определяется не абсолютно, а относительно (в зависимости от размера изображения).
Полученные данные выгружаем в формате json “слово - значение”.
Работа с лицом
Вторая часть этого проекта заключалась в разработке модуля по распознаванию и сравнению лиц. Мы решили не изобретать велосипед и использовали обученную модель FaceNet, которая может сравнить две фотографии человеческого лица и сравнить одно ли это лицо или два разных.
С помощью Питона приложение сначала определяет где находится фотография человека на паспорте. После этого FaceNet должна была сравнить фото паспорта с лицом перед фронтальной камерой смартфона и убедиться, что это один и тот же человек.
Однако изначально модель работала неверно и определяла схожесть лиц абсолютно случайно. Решение данной проблемы было достаточно простое - мы максимально близко обрезали лицо с паспорта, и модель заработала как надо.
Алгоритм сравнения лиц работает локально, все расчеты идут на устройстве, а вот алгоритм по определению данных с паспорта отправляется на бэк, где и происходит распознавание.
Человек или фотография
Еще одной важной задачей было суметь определить находится ли перед камерой живой человек, или только его фото или видео с ним. Как правило, для решения этой цели пользователя просят выполнить ряд простых движений лицом в определенной последовательности. Благодаря Google ML Kit данный функционал реализуется довольно быстро и просто; в нашем приложении мы просим пользователя повернуть голову налево и направо, подмигнуть левым и правым глазом, а в конце улыбнуться.

Таким образом, наше приложение знает, что перед ним реальный человек с реальными, а главное своими, документами. А вы можете посмотреть наше демо видео, чтобы убедиться, что само приложение тоже реально:
Результаты
Приложение получилось довольно лаконичным, но быстрым и эффективным: распознавание документа в среднем занимает менее двух секунд, а распознавание лица происходит в режиме реального времени незаметно для пользователя.
Современные сервисы и технологии позволяют довольно быстро и без особых затрат реализовать систему, которая до нуля снизит различные злоупотребления при регистрации.