Лучшие ИИ-решения для обработки документов: GdPicture, OpenCV, Amazon Textract и другие
Извлечение данных из документов с помощью искусственного интеллекта помогает компаниям экономить время на рутинных операциях и иметь оптимальный штат сотрудников.
В современном мире, построенном на данных, организации накапливают огромные объёмы информации, позволяющие принимать важные решения и делать выводы. Около 80% от этого объема представляют собой неструктурированные данные, в которых отсутствует формат и упорядоченность.
ИИ позволяет компаниям автоматизировать извлечение ценных сведений как из структурированных, так и из неструктурированных документов.
Алгоритмы машинного обучения и методы обработки естественного языка позволяют просеивать огромные объемы документов, с удивительной точностью выявляя закономерности, сущности и взаимосвязи. И этим надо пользоваться!
Обдумываете IDP решение?
Мы создаем индивидуальные системы по обработке документов при помощи искусственного интеллекта.
Какие бывают данные?
Если вкратце, то данные бывают структурированные и неструктурированные.

Также выделяется третий, промежуточный тип — частично структурированные данные. Такие данные находятся между структурированными и неструктурированными данными. Они могут иметь приблизительную схему, соответствующую различным форматам и меняющимся требованиям.
Нечёткая схема документов обеспечивает определённую гибкость структуры данных, сохраняя при этом общую организацию. Распространёнными примерами таких данных являются форматы XML, JSON и CSV.
Извлечение неструктурированных данных
В отличие от структурированных данных, которые соответствуют заранее определенным форматам или схемам, неструктурированные данные не имеют чёткой организации, что делает их сложными для извлечения информации вручную.
Отдельной проблемой является сбор неструктурированных данных. Вследствие большого объёма, разнообразия и сложности информации, это сложно делать. Для этого процесса необходимы извлечение данных из различных источников, например, при помощи API.
После сбора таких данных необходимо эффективно хранить и затем обработать эти данные. Для того, чтобы справиться со сложностью и объемами неструктурированных данных, компании должны вкладываться в современные решения.
Тем не менее, извлечение информации из неструктурированных данных представляет собой важнейшую вещь в сфере управления информацией: просеивая огромные объемы данных, можно обнаружить значимую для бизнеса информацию. Такими данными могут быть, например, электронные письма, новостные статьи, юридические документы и научные работы.
Газеты
Примером неструктурированных данных являются газетные статьи. Они часто содержат смесь текстового контента, изображений и метаданных, что затрудняет извлечение нужной информации вручную.
Используя ИИ-методы извлечения данных, можно автоматически анализировать газеты, извлекая такие важные сведения, как заголовки, даты публикаций, имена авторов и персонажей, содержание статей для цифрового архивирования и исследовательских целей.
Юридические документы
Юридические документы представляют собой еще один пример неструктурированных данных, которые можно эффективно анализировать, применяя технологии извлечения данных на основе ИИ. Юридические документы, такие как контракты, соглашения и судебные документы, часто содержат плотный, сложный язык и замысловатое форматирование.
Из судебных документов можно извлекать ключевые положения, пункты и даты, имена судей, подсудимых и ответчиков — доставать такие данные вручную может быть трудоемко и чревато ошибками. Лучше автоматизировать этот процесс, тем самым упрощая управление договорами и соблюдение требований.

Это лишь некоторые из примеров неструктурированных данных. С развитием цифрового мира могут возникать новые форматы, а уже имеющиеся форматы могут адаптироваться для включения в них новых неструктурированных типов данных.
Извлечение структурированных данных
Структурированные данные имеют заранее определенную структуру, что облегчает их извлечение и анализ. Примерами структурированных документов являются формы, счета, квитанции, опросы и контракты, каждый из которых содержит ценные элементы данных, которые можно извлечь с помощью технологий, основанных на искусственном интеллекте.
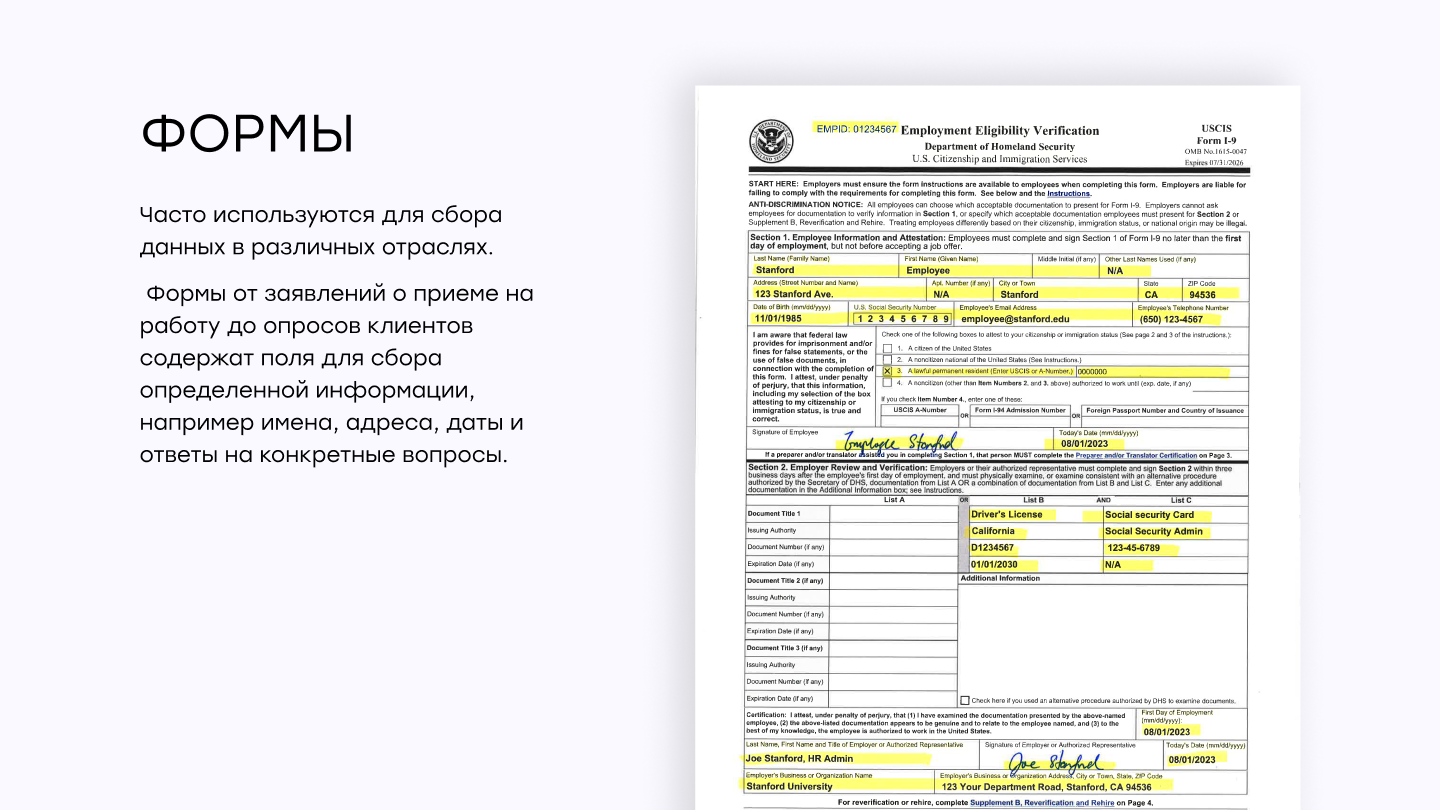
Формы
Формы представляют собой один из наиболее распространенных типов структурированных документов, часто используемых для сбора данных в различных отраслях. Формы от заявлений о приеме на работу до опросов клиентов содержат поля для сбора определенной информации, например имена, адреса, даты и ответы на конкретные вопросы.
Искусственный интеллект умеет определять поля и извлекать из них данные с высокой точностью. Такая возможность упрощает процессы ввода данных в сторонние базы данных, сокращает количество ошибок и повышает точность, что в конечном итоге повышает эффективность работы организации.
Счета-фактуры
Счета-фактуры и квитанции — еще один пример структурированных документов, которые хорошо поддаются ИИ-методам извлечения данных. Эти документы, как правило, содержат важную информацию, такую как детали счетов, статьи, условия оплаты и суммы налогов, которые необходимо точно извлекать для целей бухгалтерского учета и финансового анализа.
С помощью таких ИИ-инструментов извлечения данных, как GD Picture и OpenCV, организации могут автоматизировать процесс извлечения ключевых данных о счетах и квитанциях, что способствует ускорению обработки счетов, отслеживанию расходов и составлению финансовой отчетности.

Обработка сложных структур, таблиц, рукописного текста, изображений и графиков
Обработка сложных структур, таблиц, рукописного текста, изображений и графиков представляет собой серьезную проблему при извлечении данных, поскольку для точного извлечения и определения часто требуются специальные методы.
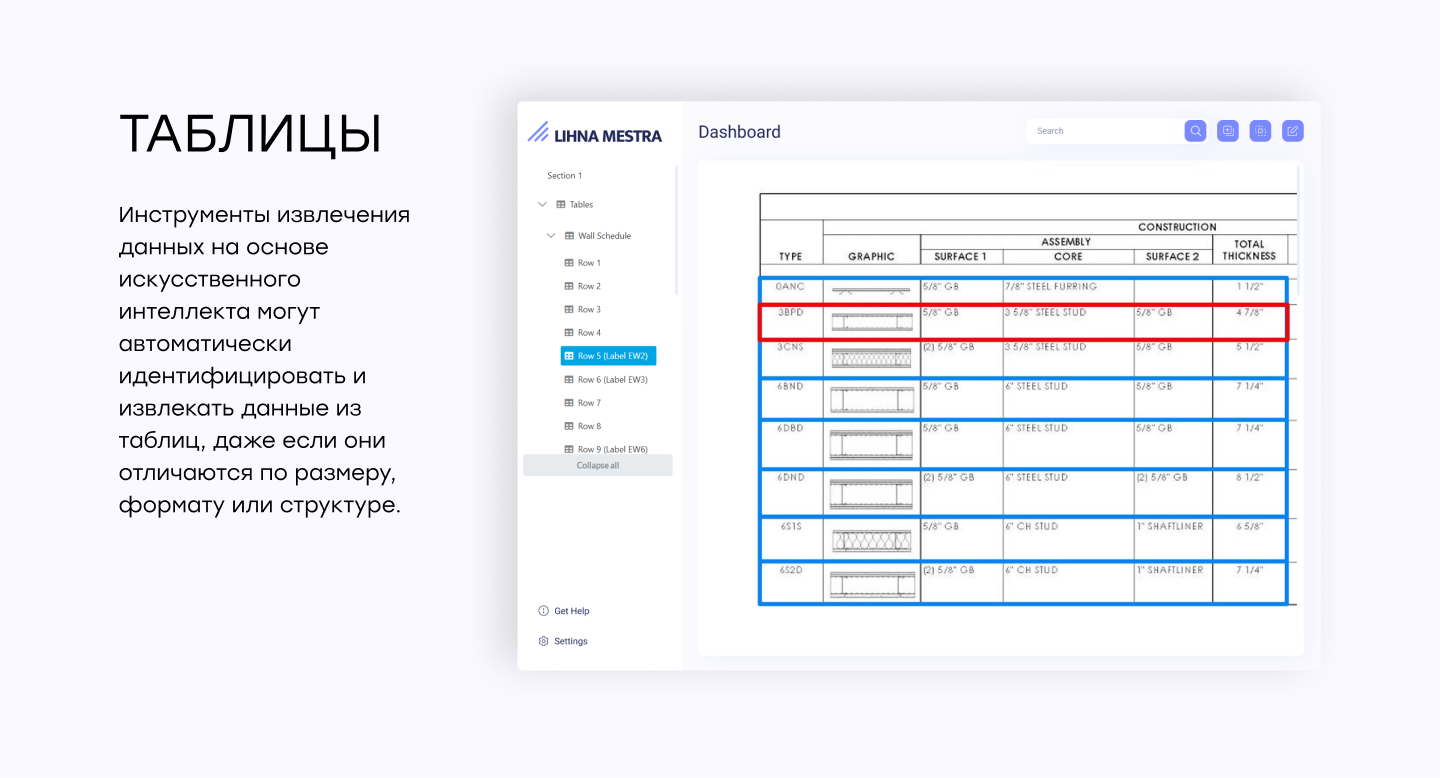
Таблицы
Таблицы часто встречаются в таких документах, как финансовые отчеты, научные статьи и электронные таблицы, и часто содержат важные данные, расположенные в строках и столбцах. Инструменты извлечения данных на основе искусственного интеллекта могут автоматически идентифицировать и извлекать данные из таблиц, даже если они отличаются по размеру, формату или структуре.
Используя такие методы, как оптическое распознавание символов (OCR) и алгоритмы распознавания таблиц, организации могут извлекать структурированные данные из таблиц с высокой точностью.
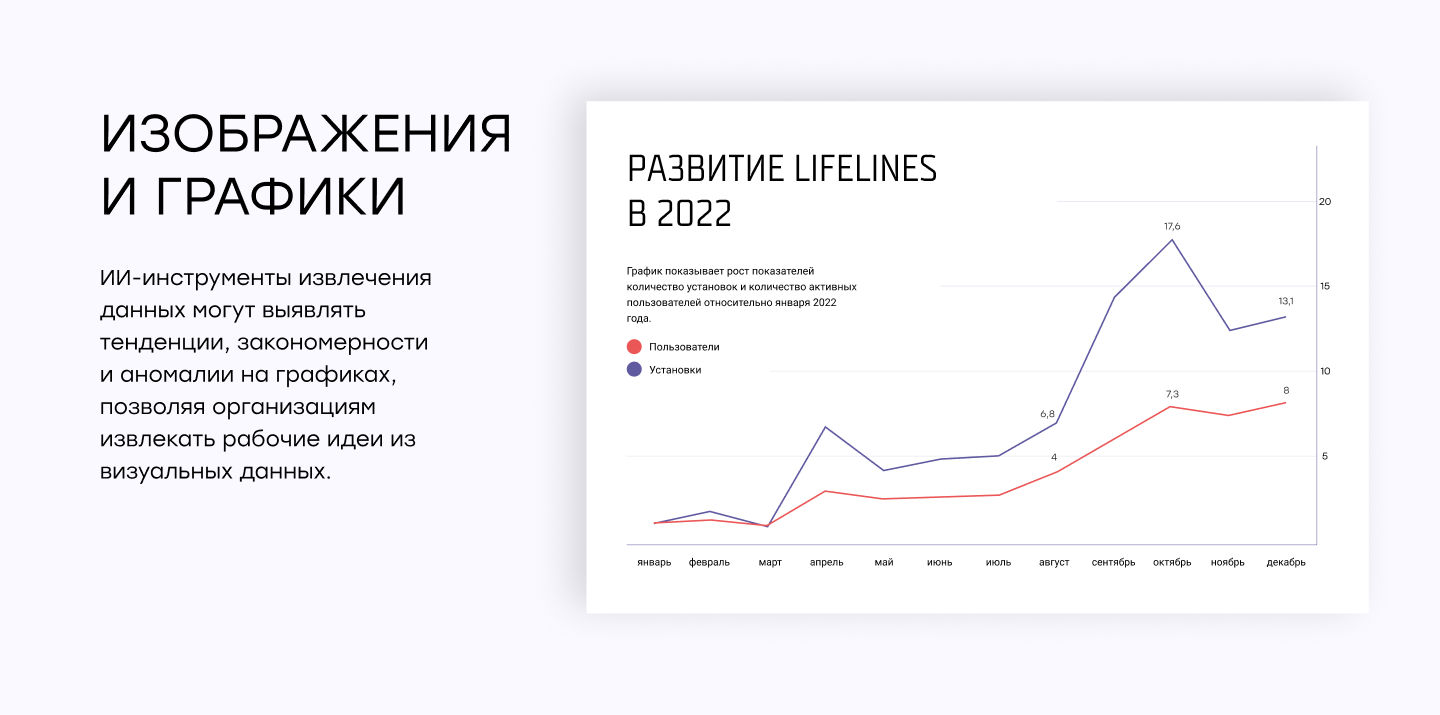
Изображения и графики
Изображения и графики часто используются для передачи сложной информации в таких документах, как презентации, отчеты и исследовательские работы. В то время как традиционные методы извлечения могут не справиться с интерпретацией нетекстового контента, алгоритмы распознавания изображений на основе ИИ могут анализировать изображения и графики, извлекая из них необходимые данные.
Например, инструменты извлечения на основе ИИ могут выявлять тенденции, закономерности и аномалии на графиках, позволяя организациям извлекать рабочие идеи из визуальных данных.
Нужна помощь в оценке AI-решения?
Поможем оценить ваш проект, а также распишем все этапы проекта, чтобы у вас было полное представление о своей задумке!
IDP инструменты извлечения данных из pdf
Самый часто встречаемый формат документов в бизнес-практике — pdf. В этом формате присылают счета-фактуры, резюме, годовые и квартальные отчеты. Большинство популярных редакторов документов умеет сохранять докумнты в pdf, поскольку это защищает их от редактирования.
Поэтому сегодня мы рассмотрим инструменты для извлечения данных из pdf-файлов. IDP инструменты используют сочетание таких технологий, как оптическое распознавание символов (OCR), обработку естественного языка (NLP) и алгоритмы машинного обучения. pdf-файлы могут быть при этом как структурированными, так и неструктурированными.
iText
iText — это мощная библиотека для манипулирования и извлечения данных из pdf-файлов, которая позволяет пользователям программно анализировать, изменять и извлекать данные из pdf-документов. С помощью iText организации могут автоматизировать процесс извлечения текста, изображений и метаданных из pdf.
Одним из недостатков iText является его стоимость: по сравнению с другими инструментами для интеллектуальной обработки документов, лицензия на распространение iText является самой дорогой в этом списке. В зависимости от бюджета проекта, стоимость лицензирования может существенно повлиять на общую стоимость разработки.
GdPicture
GdPicture — еще один универсальный инструмент для извлечения данных из pdf, предлагающий широкий спектр функций для обработки документов и распознавания изображений. С помощью GdPicture разработчики могут с легкостью извлекать текст, изображения, таблицы и другие элементы из pdf-документов.
Мы обнаружили, что GdPicture является наиболее сбалансированным решением, когда речь идет о точности распознавания и стоимости лицензирования. Стоит отметить, что базовая версия GdPicture может работать только с pdf-документами с текстовым слоем, поэтому для документов без текстового слоя вам придется либо перейти на другую версию GdPicture, либо использовать другие инструменты для извлечения данных.
Pdfplumber
Pdfplumber — это библиотека Python, специально разработанная для задач извлечения данных из pdf-файлов, которая предлагает широкие возможности для разбора и извлечения текстовых и табличных данных.
По нашему опыту, Pdfplumber, будучи полностью бесплатным, является наименее точным из всех инструментов в нашем списке. Мы не рекомендуем использовать Pdfplumber в проектах, где важна высокая точность.
OpenCV
OpenCV — это популярная библиотека компьютерного зрения, которая также может быть использована для задач извлечения данных из pdf, в частности для извлечения изображений, графиков и примитивов (основных структурных элементов документа, таких как вертикальные и горизонтальные линии, поля и т. д.).
OpenCV — очень мощный инструмент в руках опытного ML-разработчика. OpenCV может решать сложные задачи по поиску и извлечению данных, обнаружению примитивов, извлечению и обнаружению как печатного, так и рукописного текста.
Azure Form Recognizer
Azure Form Recognizer — это облачный инструмент, предлагаемый Microsoft Azure для извлечения структурированных данных из pdf-форм и документов. Используя модели машинного обучения, Azure Form Recognizer может автоматически определять и извлекать ключевые поля данных из pdf-файлов.
Azure Form Recognizer лучше всего работает с налоговыми формами США, но может работать и с другими типами документов. Однако если вам нужно извлечь данные из неструктурированных документов или документов, отличных от налоговых форм, мы рекомендуем использовать другие инструменты для достижения более высокой точности распознавания.
MLPClassifier
MLPClassifier — это алгоритм машинного обучения, обычно используемый для задач классификации текста, включая извлечение данных из pdf. Обучая модели MLPClassifier на маркированных pdf-данных, организации могут разрабатывать индивидуальные решения для извлечения определенных типов информации из pdf-документов, таких как анализ настроения, распознавание сущностей или категоризация документов.
Amazon Textract
Amazon Textract — это полностью управляемый сервис OCR, предоставляемый Amazon Web Services (AWS), предназначенный для извлечения текста, таблиц и форм из отсканированных документов, включая pdf-файлы. Amazon Textract — отличный выбор для обработки структурированных документов, особенно pdf-файлов без текстового слоя.
Этот инструмент отлично подходит для выполнения первого шага интеллектуальной обработки pdf-документов без текстового слоя — извлечения текста. А дальше уже можно подключать другие инструменты.
GPT-4 и ChatGPT
Наконец, GPT-4 и GPT-3, а также ChatGPT — вариант GPT, специально разработанный для разговорного ИИ, также могут быть использованы для задач извлечения данных из pdf. Популярная модель OpenAI отлично подходит для семантического поиска и интеллектуальной обработки документов, которая включает в себя постобработку извлеченных данных.
Выводы
Для каждой задачи и типа данных нужно подбирать свои инструменты анализа данных. Где-то может хватить бесплатной библиотеки, а где-то придётся вложиться в лицензированное ПО, которое может многое.
Технологика уже не первый год разрабатывает системы компьютерного зрения для своих клиентов. Мы накопили большой опыт в области интеллектуальной обработки документов и разработали множество систем для обработки структурированных и неструктурированных документов. И знаем, какие инструменты и где можно применять.
Мы работали с различными моделями компьютерного зрения, инструментами извлечения и обработки текста, а также языковыми моделями для создания мощных цифровых систем IDP.
Наш опыт поможет любой компании — от стартапа до международной корпорации.