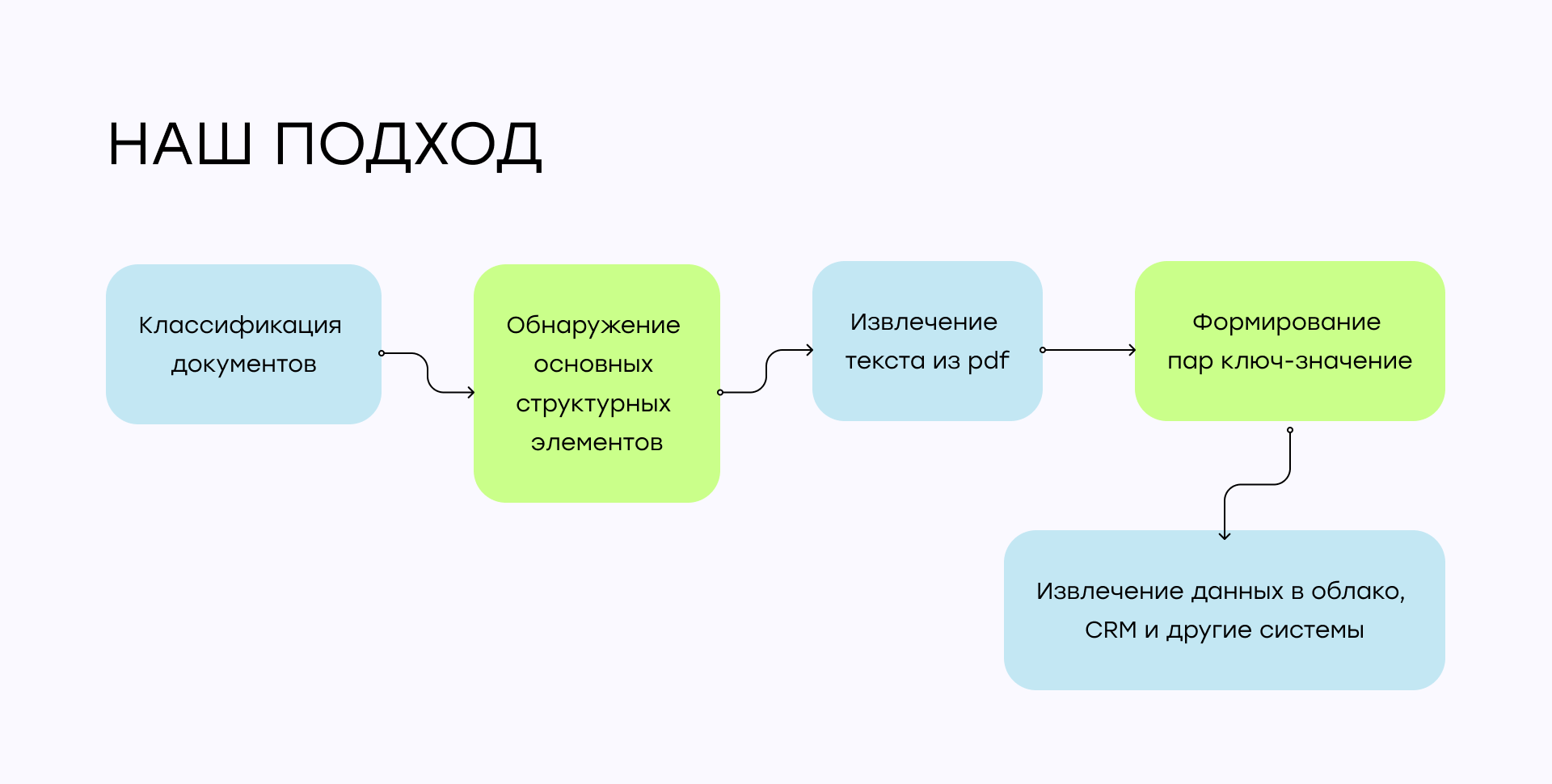
Наш подход к интеллектуальной обработке документов при помощи ИИ
Как компания, разрабатывающая системы компьютерного зрения и обладающая большим опытом в области интеллектуальной обработки документов, мы разработали множество систем для обработки структурированных и неструктурированных документов. Мы работали с различными моделями компьютерного зрения, инструментами извлечения и обработки текста, а также языковыми моделями для создания мощных цифровых систем IDP.
Каждый проект по обработке документов с помощью ИИ требует поиска наилучшего подхода к разработке, включая тестирование различных ИИ-моделей и инструментов обработки документов, существуют подходы, которые универсально хорошо работают для определенных типов документов.
В данной статье мы мы опишем процесс разработки ИИ-системы для обработки pdf-документов с применением GdPicture и OpenCV:
Обдумываете IDP решение?
Мы создаем индивидуальные системы по обработке документов при помощи искусственного интеллекта.
Классификация типов документов
Классификация типов документов с помощью GdPicture и OpenCV — важнейший шаг в процессе обработки документов. Этот процесс включает в себя идентификацию и классификацию различных типов документов на основе их визуальных характеристик и структуры содержимого. Как это происходит?

Шаг 1
Сначала документы подвергаются предварительной обработке для повышения качества изображения и удаления шумов, что обеспечивает оптимальные условия для анализа документов искусственным интеллектом.
Шаг 2
Затем используются методы извлечения признаков для выделения соответствующих визуальных характеристик из изображений документов. GdPicture и OpenCV предоставляют собой ряд инструментов и алгоритмов для извлечения признаков, позволяя настраивать подход в зависимости от уникальных характеристик наборов данных документов.
Обычно здесь происходит предобработка текста, которая переводит текст на естественном языке в формат удобный для дальнейшей работы. Предобработка состоит из различных этапов, которые могут отличаться в зависимости от задачи и реализации. Мы часто применяем следующие этапы:
- Токенизация текста;
- Удаление стоп-слов;
- Лемматизация текста;
- Векторизация текста;
- Извлечение признаков.
Шаг 3
После извлечения визуальных признаков модели машинного обучения обучаются классифицировать документы по заданным категориям или классам. Алгоритмы контролируемого обучения, такие как машины опорных векторов (SVM), случайные леса или свёрточные нейронные сети (CNN), могут быть обучены на наборах данных с метками, содержащих примеры различных типов документов.
Шаг 4
После обучения модели классификации её можно применить к новым изображениям документов, чтобы автоматически отнести их к соответствующим типам. GdPicture и OpenCV предоставляют API и библиотеки, которые облегчают интеграцию обученных моделей в рабочие процессы обработки документов.
Обнаружение основных структурных элементов
Обнаружение структурных элементов, также известных как примитивы, с помощью OpenCV, является фундаментальной задачей в интеллектуальных процессах обработки документов. Структурные элементы включают в себя такие компоненты, как абзацы, заголовки, таблицы и изображения, которые обеспечивают базовую структуру документа.
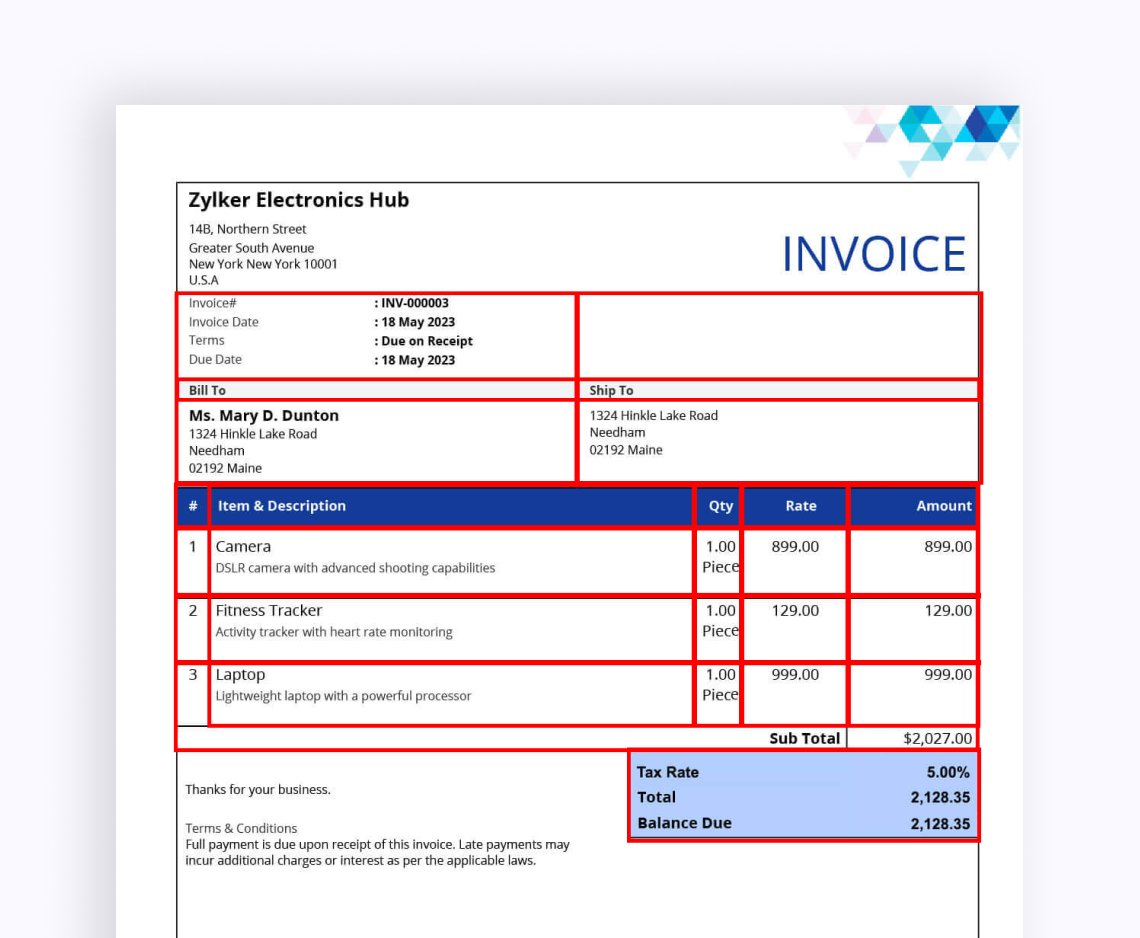
Вот шаги, необходимые для обнаружения примитивов в pdf-документе:

- Изображения документов подвергаются предварительной обработке для повышения качества изображения и удаления шумов, что обеспечивает оптимальные условия для обнаружения элементов.
Методы обнаружения контуров используются для идентификации и выделения областей интереса на изображениях документов. Контуры представляют собой границы объектов или структурных элементов на изображении, таких как текстовые блоки, линии и фигуры. - OpenCV предоставляет различные алгоритмы обнаружения контуров, такие как детектор краев Канни и функция findContours, которые могут быть использованы для идентификации и извлечения контуров из изображений документов.
- Затем можно применить дополнительные методы фильтрации и обработки для дальнейшего уточнения извлеченных структурных элементов. Например, алгоритмы аппроксимации контуров могут использоваться для упрощения сложных контуров, а анализ иерархии контуров может применяться для выявления иерархических отношений между структурными элементами, такими как вложенные текстовые блоки в параграфах или таблицы в документах.
- Наконец, структурные элементы классифицируются и маркируются на основе их визуальных характеристик и структуры содержания. Для этого могут использоваться методы машинного обучения для обучения моделей, способных классифицировать структурные элементы по заранее определенным категориям, таким как абзацы, заголовки, таблицы и изображения.
- Извлечение текста из pdf
Извлечение текста из pdf
Извлечение текста из pdf-документов — одна из основных задач в рабочих процессах обработки документов.
Два распространенных подхода к извлечению текста из pdf-документов включают использование GdPicture с текстовыми слоями и AWS Textract для документов без текстовых слоев. Каждый подход имеет свои преимущества в зависимости от характеристик обрабатываемых pdf-файлов.
Pdf-документы с текстовым слоем
С помощью GdPicture извлечение текста из pdf-документов, содержащих текстовый слой, является простым процессом. Pdf-файлы с текстовым слоем сохраняют оригинальное текстовое содержимое и форматирование, что облегчает точное извлечение текста.
GdPicture является надежным инструментом со своим API для разбора pdf-файлов. GdPicture позволяет извлекать текст с высокой точностью, сохраняя при этом форматирование, например шрифты, стили и макеты. Такой подход идеально подходит для документов, в которых сохранение форматирования текста и целостности макета очень важно, например для договоров, отчетов и юридических документов.
Документы в формате pdf без текстового слоя
Другая ситуация, когда мы имеем документы в pdf формате без текстового слоя. Распознавание и выгрузка данных из таких документов сопряжены с дополнительными трудностями, поскольку такие файлы содержат изображения текста, а не текстовое содержимое, по которому можно вести поиск. Но и в такой ситуации есть решение.
AWS Textract решает эту проблему, используя технологию оптического распознавания символов (OCR) для анализа изображений и точного извлечения текста. Textract может обнаруживать и извлекать текст из изображений, отсканированных документов и pdf-файлов без текстовых слоев. Такой подход особенно полезен для обработки отсканированных документов, рукописного текста и изображений, встроенных в pdf-файлы.
Хотите больше узнать про ИИ-обработку документов?
Мы умеем обрабатывать различные документы при помощи ИИ, какие, узнайте по ссылке.
Формирование пар ключ-значение
Формирование пар ключ-значение с помощью пользовательского парсера подразумевает систематический подход к извлечению структурированных элементов данных из документов, в частности форм, опросов и других структурированных документов.
Этот процесс необходим для автоматизации задач извлечения данных и оптимизации рабочих процессов обработки документов:

Поскольку на этом этапе примитивы уже извлечены, макет документа становится понятным и идентифицируемым. Извлечение текста с помощью GdPicture или AWS Textract также позволяет получить содержимое документа.
Чтобы перейти к сопоставлению ключей и значений, необходимо создать парсер, адаптированный под конкретную структуру и макет документа, используя Python, Java или C#, а также библиотеки или фреймворки для обработки документов: например, Apache pdfBox, Tesseract OCR или OpenCV.
После развертывания парсер извлекает пары ключ-значение, например имя поля и поле ввода, например "Имя — Бобби Смит".
Пользовательский парсер предназначен для разбора документов, определения ключевых полей данных и соответствующих им значений и извлечения их в структурированные форматы данных, такие как JSON, XML или CSV.

Извлечение данных в облако, CRM и другие системы
Процесс извлечения данных подразумевает передачу извлеченных из документов данных в внутренние системы, где они могут храниться, анализироваться и использоваться для разных целей, например, для принятия решений.
Для извлечения данных в облачное хранилище можно воспользоваться облачными сервисами обработки документов, такими как Amazon S3, Google Cloud Storage или Microsoft Azure Blob Storage.
Эти сервисы предлагают безопасные и масштабируемые решения для хранения извлеченных данных в облаке. Извлеченные данные можно перенести в облачное хранилище с помощью API, SDK или инструментов интеграции, предоставляемых поставщиками облачных хранилищ, что обеспечивает бесшовную интеграцию с рабочими процессами обработки документов.
Инструменты интеграции CRM или API, предоставляемые поставщиками CRM, такими как Salesforce, HubSpot или Microsoft Dynamics, могут помочь интегрировать извлеченные данные в выбранную CRM. Эти инструменты позволяют организациям передавать извлеченные данные непосредственно в базы данных CRM, где они могут использоваться для обновления записей о клиентах, отслеживания взаимодействий и автоматизации процессов продаж и маркетинга.
Для извлечения данных в существующие программные системы можно использовать инструменты интеграции, API или собственные интеграционные решения, разработанные с учетом их специфических требований.
Нишевый опыт в интеллектуальной обработке документов
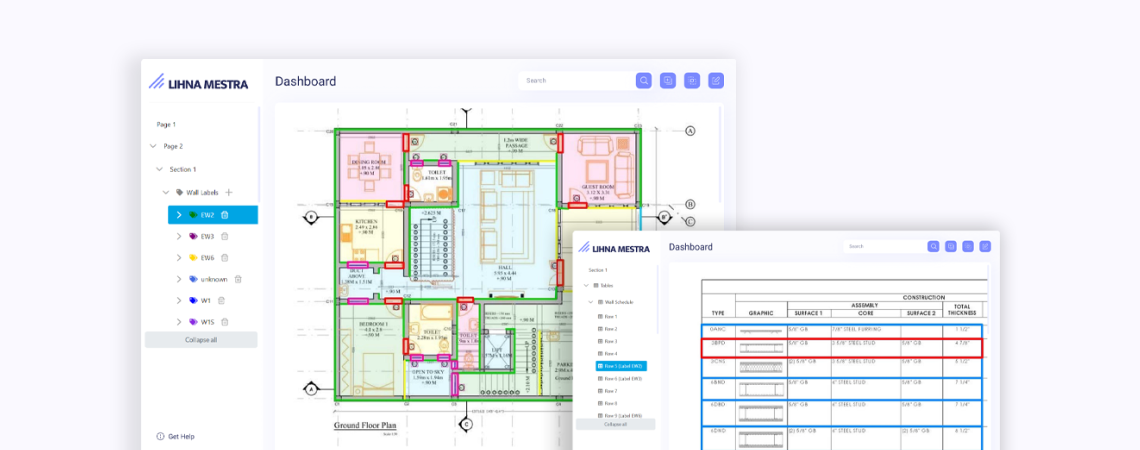
Система распознавания технических чертежей
Технические чертежи — одни из самых сложных для обработки видов документов. Несмотря на то что их структура в целом однородна, сами чертежи зачастую разные и сложные. Именно в таких случаях интеллектуальная обработка документов действительно помогает извлекать и оцифровывать данные даже из самых сложных документов и экономить время персонала на ручном труде.
Для нашего клиента мы разработали систему обработки технических чертежей на основе искусственного интеллекта, включая обнаружение объектов и извлечение сложных электронных таблиц.
Система способна в режиме реального времени определять помещения, стены, окна и двери, определять тип и масштаб технических чертежей, а также автоматически генерировать оглавление, облегчая навигацию по большим многостраничным документам.
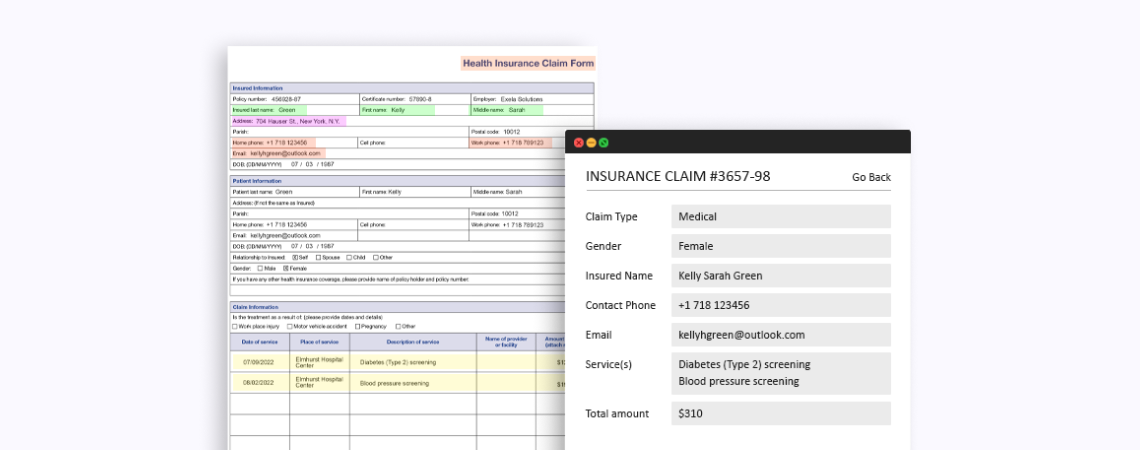
SaaS-приложение для извлечения данных из страховых претензий
Процесс ручного извлечения необходимой информации из страховых документов отнимает много времени и чреват ошибками, поэтому наш клиент решил внедрить систему автоматической обработки документов, чтобы сократить объем работы и повысить качество занесенных данных в CRM систему.
Мы создали приложение для извлечения данных из страховых претензий на основе искусственного интеллекта, которое определяет структуру документов и извлекает необходимые данные за считанные минуты. Наше приложение извлекает информацию из претензий и подготавливает их к дальнейшей обработке.
Почему стоит выбрать Технологику для разработки системы интеллектуальной обработки документов?
- Технологика с 2003 года работает на рынке разработки ПО и накопила большой опыт работы с самыми разными клиентами.
- В штате компании более чем 70 высококвалифицированных инженеров-программистов с большим опытом разработки сложного программного обеспечения как для стартапов, так и для международных компаний.
- Глубокая экспертиза в современных технологиях искусственного интеллекта и подходах к разработке систем, таких как data science, машинное обучение, OpenCV, Python, Tesseract и многие другие.
- Технологика является золотым сертифицированным партнером Microsoft. Технологика зарекомендовала себя как надежный партнер по аутсорсингу ИИ, имея отличный послужной список в области разработки ИИ и ML, подкрепленный обширным портфолио успешных проектов.
Обдумываете IDP решение?
Мы создаем индивидуальные системы по обработке документов при помощи искусственного интеллекта.