Распознавание рукописного текста с помощью LLM: точность, стоимость и результаты реальных тестов
Распознавание рукописных форм — одна из самых сложных задач в автоматизации документооборота. Даже современные AI-модели и LLM часто дают нестабильные результаты, когда сталкиваются с реальными бумажными формами: курсивом, плотным макетом, пересекающимися полями и семантически критичными данными.
В этой статье мы разбираем, как современные языковые модели справляются с рукописными документами на практике. Материал основан на реальном бенчмарке и предназначен для команд, которые внедряют AI-распознавание документов в продакшене, а не в демо-сценариях.
Мы сравнили несколько популярных AI-моделей по точности, скорости и стоимости и сделали выводы, которые помогают выбрать подходящее решение под конкретные бизнес-задачи.
Хотите распознавать рукописные тексты?
Мы создаем ИИ-решения, способные обрабатывать и понимать документы с рукописными текстами. Давайте обсудим именно ваши рукописные тексты!Что такое распознавание рукописных форм и почему это сложно?
Распознавание рукописных форм — это задача извлечения структурированных данных из документов, где информация вписана от руки в заранее определённые поля: имена, даты, адреса, идентификаторы, номера телефонов и подписи.
В отличие от печатного OCR, рукописные формы создают сразу несколько уровней сложности:
- почерк сильно отличается от человека к человеку и даже внутри одного документа;
- символы соединяются, искажаются или пишутся не полностью;
- текст выходит за границы полей и накладывается на элементы шаблона;
- ошибки в критичных полях делают данные непригодными для использования.
Поэтому рукописный OCR остаётся одной из самых проблемных областей документного ИИ.
Могут ли LLM надёжно распознавать рукописный текст?
Большие языковые модели всё чаще используются для обработки рукописных документов — как правило, в составе мультимодальных пайплайнов. На практике они действительно умеют извлекать рукописный текст, но их надёжность напрямую зависит от структуры формы и качества почерка.

Короткий ответ выглядит так:
LLM способны распознавать рукописный текст, но только в пределах жёстких структурных и семантических ограничений.
Основные ошибки возникают не из-за «нечитаемых букв», а из-за сочетания визуальной неоднозначности, сложного макета и строгих бизнес-требований к корректности данных.
Методология бенчмарка
Оцениваемые модели
В финальный бенчмарк вошли семь моделей:
- Azure
- AWS
- Claude Sonnet
- Gemini 2.5 Flash Lite
- GPT-5 Mini
- Grok 4
Датасет и условия тестирования
В бенчмарке использовались 10 реальных бумажных форм, заполненных вручную и отсканированных. Датасет намеренно отражает рабочие условия, а не синтетические примеры.

Формы различались по следующим параметрам:
- плотность и сложность макета;
- стиль почерка (печатный, курсив, смешанный);
- выравнивание строк и интервалы;
- типы данных: имена, даты, адреса, числовые идентификаторы.
Эталонные данные и оценка
Для каждой формы вручную был подготовлен набор эталонных значений (ground truth) для всех рукописных полей.
Оценка проводилась на уровне отдельных полей, а не символов или строк. Такой подход ближе всего к реальным требованиям бизнеса.
Логика подсчёта точности
Использовалась двухэтапная схема:
- автоматическое сравнение без учёта регистра на основе расстояния Левенштейна (порог — 80%);
- ручная семантическая корректировка для критичных полей.
Если ошибка затрагивала имя, дату или идентификатор, результат считался некорректным даже при высоком текстовом сходстве.
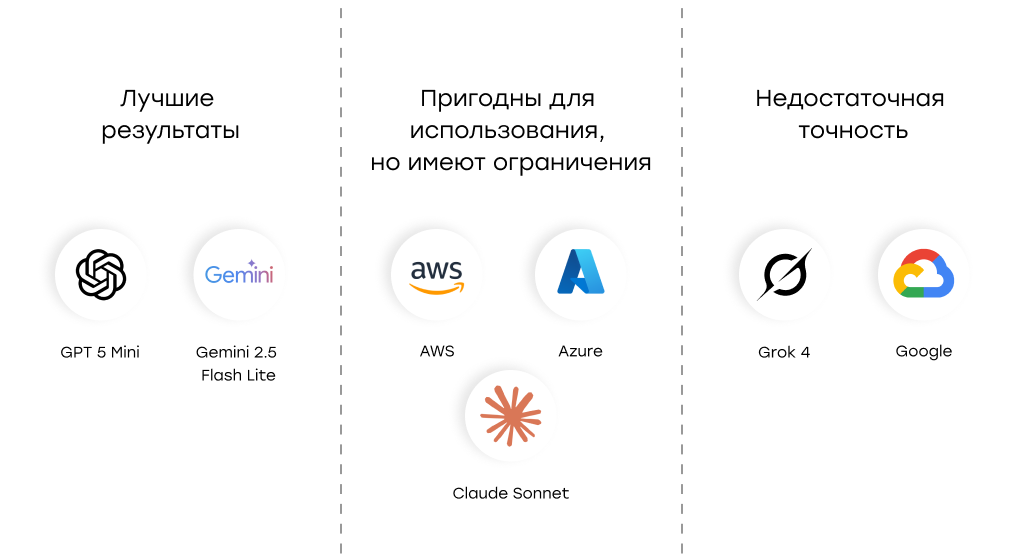
Какая AI-модель лучше подходит для распознавания рукописных форм?
По итогам бенчмарка две модели стабильно превзошли остальные:
- GPT-5 Mini
- Gemini 2.5 Flash Lite
Они показали высокую точность на разных типах форм и стилях почерка.
Средний уровень продемонстрировали Azure, AWS и Claude Sonnet. Худшие результаты показали Google и Grok 4 — их точность оказалась недостаточной для практического использования.
Сравнение точности моделей для рукописного OCR
При сравнении точности важно учитывать, что рукописный OCR нельзя оценивать только по среднему проценту совпадений. В реальных бизнес-сценариях критичны ошибки в отдельных полях: имени, дате, идентификаторе или номере телефона.
Именно поэтому в бенчмарке использовалась оценка на уровне полей с учётом семантической корректности. Модель могла показать высокое текстовое сходство, но всё равно считаться ошибочной, если результат был непригоден для использования без ручной проверки.
Таблица ниже отражает практическую надёжность моделей при работе с реальными рукописными формами.
| Модель | Средняя точность | Сильные стороны | Ограничения |
| GPT-5 Mini | Самая высокая | Стабильна на любых макетах | Медленная, дороже остальных |
| Gemini 2.5 Flash Lite | Почти такая же | Лучшее соотношение цена/качество | Чувствительна к плотным формам |
| Azure | Средняя | Хорошо работает с печатным почерком | Проблемы с курсивом |
| AWS | Средняя | Быстрая обработка | Нестабильное качество |
| Claude Sonnet | Средняя | Иногда справляется со сложными формами | Высокая вариативность |
| Низкая | Простые формы | Ошибки в критичных полях | |
| Grok 4 | Самая низкая | Минимальные | Очень медленная и неточная |
Обдумываете IDP решение?
Мы создаем индивидуальные системы по обработке документов при помощи искусственного интеллекта.
Почему точность рукописного OCR редко превышает 95%?
Во многих презентациях и демо можно увидеть заявления о точности 98–99%, однако на реальных рукописных документах такие значения практически недостижимы. Причина заключается не в "слабости" конкретных моделей, а в природе самих данных.
Рукописные формы сочетают визуальный шум, нестабильный почерк, сложные макеты и высокие требования к смысловой точности. Даже одна небольшая ошибка в имени или дате может полностью обесценить результат распознавания.
Поэтому при переходе от демонстрационных примеров к продакшн-документам фактическая бизнес-точность почти всегда оказывается ниже 95%, даже у лучших моделей.
Даже лучшие модели не смогли стабильно достичь 95%+ бизнес-точности. Это ограничение носит системный характер.
- непредсказуемый шум рукописного текста;
- ошибки сегментации полей;
- визуально похожие символы;
- многострочный и смещённый текст;
- высокая семантическая чувствительность данных.
Скорость и стоимость обработки рукописных форм
При выборе AI-модели для рукописного OCR важно учитывать не только точность, но и операционные параметры: скорость обработки и стоимость при масштабировании.
Разница между моделями становится особенно заметной при больших объёмах документов. Даже небольшое увеличение времени обработки или цены за одну форму может существенно повлиять на итоговую стоимость владения решением.
В таблицах ниже показано, как модели различаются по цене за 1000 форм и среднему времени обработки одной формы, что позволяет оценить реальные компромиссы между скоростью, точностью и бюджетом.
Стоимость обработки 1000 форм
| Модель | Стоимость |
| Gemini 2.5 Flash Lite | $0,368 |
| GPT-5 Mini | $5,062 |
| Azure | $10,000 |
| Claude Sonnet | $18,701 |
| $30,000 | |
| AWS | $65,000 |
Среднее время обработки одной формы
| Модель | Время, сек |
| AWS | 4,8 |
| Gemini 2.5 Flash Lite | 5,5 |
| Azure | 6,6 |
| Claude Sonnet | 15,5 |
| GPT-5 Mini | 32,2 |
| Grok 4 | 129,3 |
Рекомендации по выбору модели
Выбор модели для распознавания рукописных форм должен основываться не на универсальных рейтингах, а на конкретных бизнес-сценариях и допустимом уровне ошибок.

Для процессов, где цена ошибки высока — например, в медицине, юриспруденции или государственном документообороте — приоритетом становится максимальная корректность, даже если это приводит к увеличению стоимости и времени обработки.
В массовых сценариях, где важны скорость и экономичность, разумнее выбирать модели с лучшим соотношением точности и цены, дополняя их пост-обработкой или выборочной проверкой.
| Сценарий | Рекомендуемая модель |
| Медицина, юриспруденция, госсектор | GPT-5 Mini |
| Массовая обработка форм | Gemini 2.5 Flash Lite |
| Простые структурированные формы | Azure или AWS |
| Некритичные процессы | Claude Sonnet |
Заключение
Распознавание рукописных форм остаётся одной из самых сложных задач документного ИИ. Универсального решения не существует.
Реальные бенчмарки показывают, что компактные и экономичные модели могут превосходить более крупные и дорогие решения, а ключевые ограничения связаны со структурой и семантикой документов, а не с качеством распознавания отдельных символов.
Выбор AI-модели должен основываться на реальных данных, допустимом уровне ошибок и бизнес-рисках, а не на маркетинговых обещаниях.
Хотите больше узнать про ИИ-обработку документов?
Мы умеем обрабатывать различные документы при помощи ИИ, какие, узнайте по ссылке.
Заключение
Распознавание рукописных форм остаётся одной из самых сложных задач документного ИИ. Универсального решения не существует.
Реальные бенчмарки показывают, что компактные и экономичные модели могут превосходить более крупные и дорогие решения, а ключевые ограничения связаны со структурой и семантикой документов, а не с качеством распознавания отдельных символов.
Выбор AI-модели должен основываться на реальных данных, допустимом уровне ошибок и бизнес-рисках, а не на маркетинговых обещаниях.
Хотите больше узнать про ИИ-обработку документов?
Мы умеем обрабатывать различные документы при помощи ИИ, какие, узнайте по ссылке.