LLM vs. почерк: практическое сравнение GPT-5, Gemini и Claude в задачах OCR
Распознавание рукописного текста — задача, которая остаётся болезненной даже в 2025 году. Именно это не позволяет оцифровать многие архивы и документы, а также является камнем преткновения в разной бизнес деятельности.
OCR-движки вроде Azure Document Intelligence, Google Vision или ABBYY уже давно научились безошибочно читать печатные формы, но всё рушится, когда на сцену выходит человек с ручкой.
Почерк — это хаос, в котором буквы скачут, строки уползают, а "5M" внезапно превращается в "5 PM", если повезёт. И если обычный OCR видит только буквы и пиксели, LLM видит смысл.
Производители заявляют, что модели вроде GPT-5, Gemini 2.5 Pro и Claude Sonnet 4.5 способны не просто распознать текст, а догадаться, что автор имел в виду: исправить пунктуацию, восстановить сокращения, даже понять, что стоит за пометками на полях.
Звучит красиво. Но работает ли это на реальных документах, а не в демо-видео с идеально отсканированными формами? Чтобы ответить, мы провели исследование и сравнили, как три топ-LLM обрабатывают рукописные и смешанные документы — с точки зрения точности, структурной консистентности и понимания контекста.
Методология
Что мы тестировали
Чтобы не скатиться в синтетические бенчмарки, мы взяли три реальных документа, типичных для корпоративных сценариев, где OCR-ошибки могут стоить времени и денег:
- Формуляр мероприятия в Музей трамваев (Event Form to Streetcar Museum)
- Анкета для фотооархива (Photo Submission Form "Johnny – King of Sausages")
- Форма для смены в медицинском учреждении (Medical Change of Shift Huddle Form)
Каждый документ имеет свои особенности и сложности для OCR и LLM:
- Формуляр в Музей трамваев – смешанные шрифты, наложения текста, пересекающиеся строки и неоднозначные цифры
- Анкета для фотооархива – курсив, капс, подписи, апострофы и артефакты от скана старой бумаги
- Форма для смены в больнице – несколько почерков, медицинские сокращения, пересекающиеся сетки таблиц

Как мы тестировали
Для чистоты эксперимента:
- Все три документа поданы в неизменном виде, без предварительной очистки изображений.
- Каждая модель получала один и тот же ввод (скан) и задачу: извлечь данные в структурированном JSON.
- Оценка велась вручную и по метрикам:
- CA (Character Accuracy) – сколько символов распознано корректно
- FA (Field Accuracy) – сколько полей правильно извлечено
- SA (Semantic Accuracy) – насколько правильно понят смысл и контекст
- C (Completeness) – доля извлечённых полей от ожидаемого
- S (Schema Consistency) – единообразие JSON-структуры между документами
Почему три модели?
Для эксперимента были выбраны три модели разных архитектурных подходов:
- Claude Sonnet 4.5 — фокус на интерпретации и языковом рассуждении;
- Gemini 2.5 Pro — структурная точность и стабильность вывода;
- GPT-5 — сильная контекстная и семантическая обработка.

Это позволило оценить не только базовую точность OCR, но и то, как модели восстанавливают смысл, формат и структуру данных после распознавания.
Как справились модели?
1. Формуляр в Музей трамваев (Streetcar Museum Event Form)
Эта форма — старомодный бланк с полями вроде Sponsor, Date of Event, Category, Mailing Address. Часть напечатана, часть вписана вручную — и именно это делает задачу интересной.
Основные сложности:
- строки залезают на границы таблиц;
- одни слова написаны капсом, другие — курсивом;
- рукописные цифры 2 и 5 путаются с буквами S и Z;
- некоторые поля ("Tougs" с обведённым кружком) требуют не просто OCR, а понимания логики формы.

Claude 4.5 справился посредственно: понял суть, но несколько полей спутал, а слова вроде Cultural превратил в мифических существ ("Scolyunte"). Он явно склонен к "творческой интерпретации".
Gemini 2.5 Pro показал почти безупречный результат. Он не только правильно распознал все поля, но и нормализовал их формат: аккуратные даты, выровненные адреса, единый стиль JSON. Даже додался, что "5M" – это "5 PM", и восстановил недостающие запятые.
GPT-5 чуть проиграл по структурной чистоте, но оказался лучшим по естественности текста. Он сладил орфографические неровности и исправил реестр, делая результат ближе к читаемому человеком описанию.
Итог: Gemini впереди, GPT-5 почти дошёл, Claude — стабильный, но не продакшен-уровень.
2. Анкета для фотооархива ("Johnny – King of Sausages" Photo Form)
Форма из городского архива, заполненная синей ручкой поверх выцветших полей. Здесь OCR сталкивается с типичными проблемами старых документов: кривые линии, неровный почерк, пересечение букв с рамками и случайные артефакты сканера.

Claude 4.5 всё понял правильно, но внёс хаос в ключи — где-то snake_case, где-то CAPS, а где-то просто пропустил пустые поля.
Gemini 2.5 Pro снова показал себя лучшей стороны: идеально воспроизвёл текст, сохранил пунктуацию (даже кавычки в "King of Sausages"), выстроил вложенные секции "WHEN / WHERE / WHO" и сдал JSON, который можно прямо загружать в базу.
GPT-5 показал сильное понимание контекста: фраза "Extremely busy but managed well" была не просто прочитана, а осмыслена как unit status. Но часть имён он перепутал ("Mac" вместо "Max") — классическая жертва OCR.
Итог: Gemini вновь впереди, GPT-5 почти дошёл, Claude — стабильный, но не продакшен-уровень.
3. Форма для смены в больнице (Change of Shift Huddle)
Форма с дежурства — таблица, где вписаны имена, числа, состояния пациентов и кодовые заметки вроде "MRSA developing in a patient" или "Wiping down the surfaces".
Такие документы — кошмар для любого OCR: сетка таблицы помает структуру, буквы сливаются, а почерки отличаются настолько, что кажется — это разные языки.
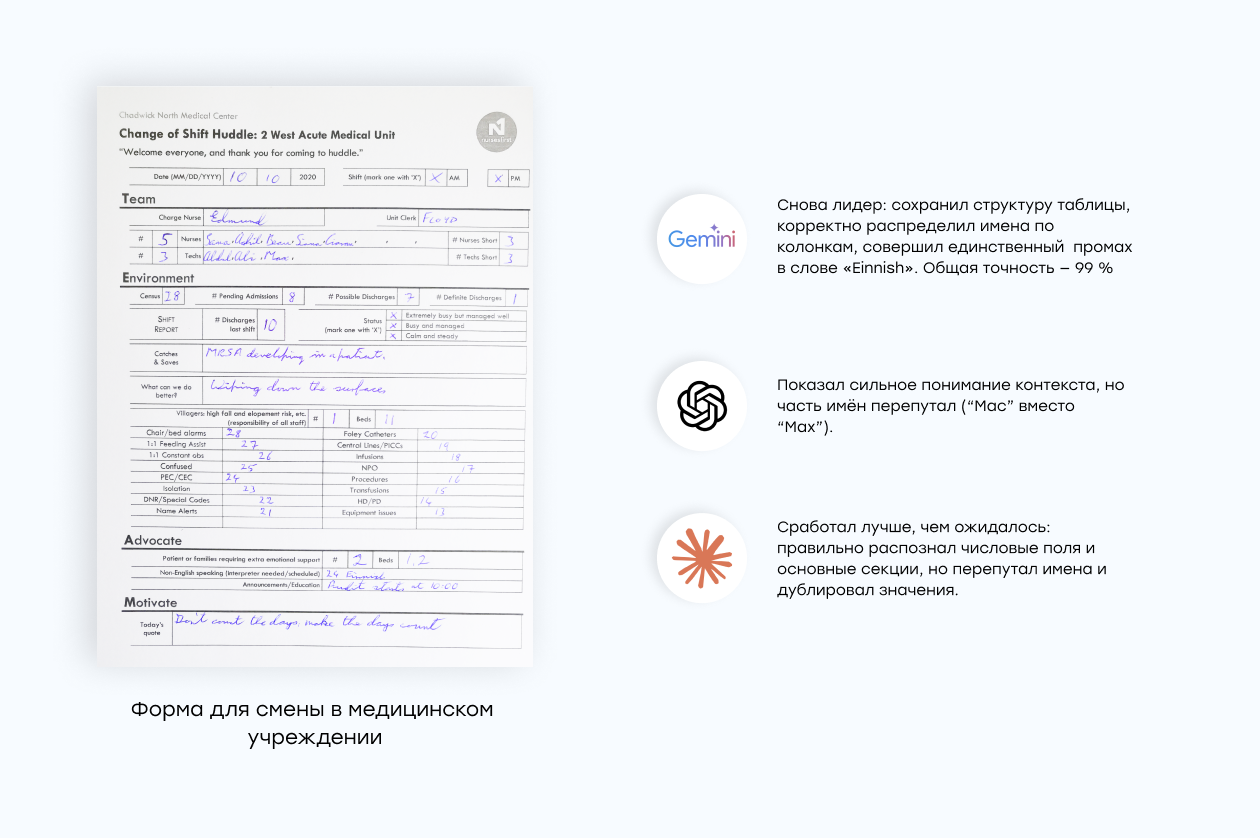
Claude 4.5 сработал лучше, чем ожидалось: правильно распознал числовые поля и основные секции (Team, Advocate, Motivate), но перепутал имена и местами пропустил пустые поля.
Gemini 2.5 Pro снова лидер: он сохранил структуру таблицы, корректно распределил имена по колонкам, а странное "Einnish" (OCR-ошибка) — единственный заметный промах. При этом общая точность полей — 99 %.
GPT-5 показал сильное понимание контекста: фраза "Extremely busy but managed well" была не просто прочитана, а осмыслена как unit status. Но часть имён он перепутал ("Mac" вместо "Max") — классическая жертва OCR.
Итог: Gemini вновь впереди, GPT-5 почти дошёл, Claude — стабильный, но не продакшен-уровень.
Кто победил?
После десятков прогонов трёх LLM по реальным рукописным формам результат оказался довольно однозначным — Gemini 2.5 Pro уверенно вырвалась вперёд по всем формальным метрикам.
| Метрика | Claude Sonnet 4.5 | Gemini 2.5 Pro | GPT-5 | Комментарий |
| Character Accuracy (сколько символов распознано корректно) |
93–97 % | 98–99 % | 97–98 % | Gemini лучше по символам, Claude чаще теряет пробелы и пунктуацию |
| Field Accuracy (сколько полей правильно извлечено) |
90–96 % | 99–100 % | 96–98 % | Gemini безошибочно выстраивает ключи и значения |
| Semantic Accuracy (насколько правильно понят смысл и контекст) |
95–98 % | 99–100 % | 98–99 % | GPT-5 чуть сильнее в логике, но слабее в форме |
| Completeness (доля извлечённых полей от ожидаемого) |
96–100 % | 100 % | 96–100 % | Все трое неплохо, но Gemini стабильно полон |
| Schema Consistency (единообразие JSON-структуры между документами) |
Средняя | Очень высокая | Высокая | JSON у Gemini можно подавать в прод без пост-обработки |
Если коротко:
- Gemini 2.5 Pro показал лучшую комбинацию точности (до 99 %) и структурной стабильности.
- GPT-5 чуть уступает в формализме, но сильнее в семантическом "понимании"
- Claude 4.5 часто ошибается в полях, но умеет красиво пересказывать — что полезно для описательных задач.
Себестоимость и скорость
Мы замеряли не только качество, но и цену и время обработки, потому что в продакшене важно не просто «чтобы красиво», а чтобы дёшево и предсказуемо.
| Модель | Стоимость на документ (USD) | Среднее время обработки | Примечание |
| Claude Sonnet 4.5 | 0.0165 | ~ 75 с | Быстрее, но дороже и менее точен |
| Gemini 2.5 Pro | 0.0080 | ~ 90 с | Оптимальное соотношение цена / качество |
| GPT-5 | 0.0094 | ~ 120 с | Медленнее, но стабильно выдаёт контекстно-богатый результат |
Что это значит:
- Обработка одного рукописного документа в Gemini стоит достаточно дёшево.
- Claude — самое "дорогое вдохновение", но не лучший вариант, если счёт идёт на тысячи страниц.
- GPT-5 — универсал: если нужно чуть больше глубины в понимании текста, разница в 30 секунд может быть оправдана.
А можно ли лучше?
Когда речь идёт о распознавании реальных документов, ни один инструмент в одиночку не идеален. OCR прекрасно видит буквы, но не понимает смысла. LLM — наоборот: понимает смысл, но не знает, где на картинке что написано.
Поэтому оптимальная архитектура гибридная: OCR → LLM → Валидация.
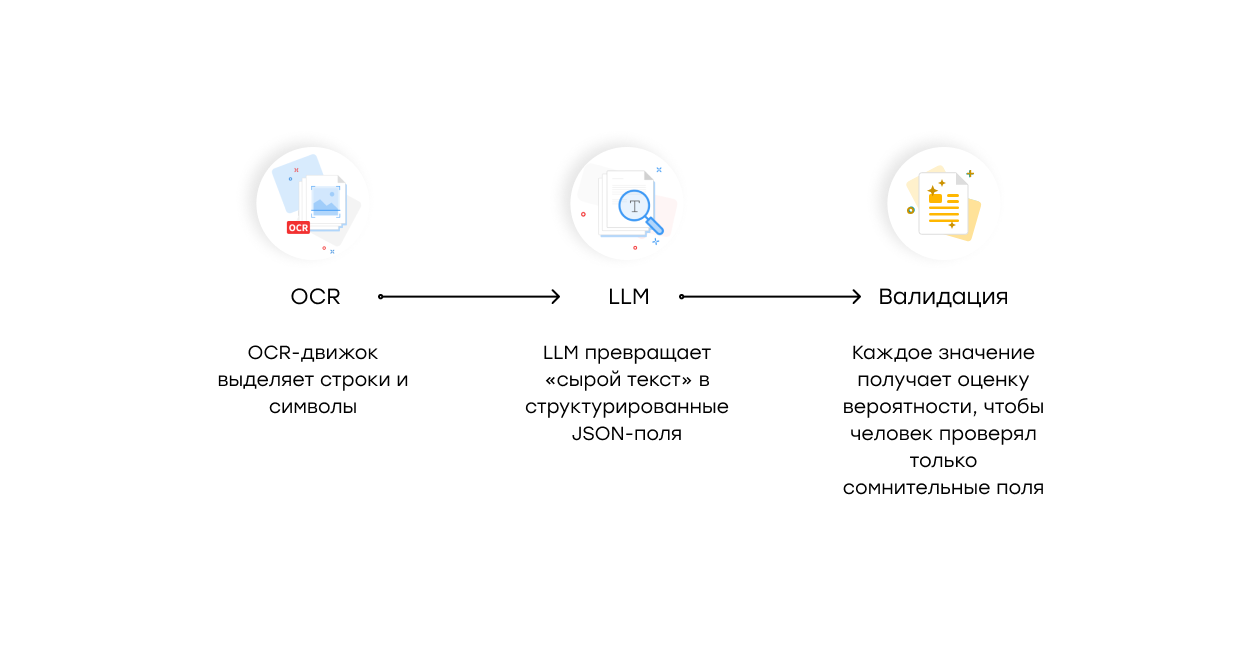
Пример на практике: Azure Document Intelligence + Gemini 2.5 Pro
- Azure DI делает то, что умеет лучше всего — распознаёт текст, возвращает bounding-box координаты и confidence-оценку для каждого слова.
- Gemini 2.5 Pro принимает этот результат и:
- исправляет очевидные OCR-ошибки («5M» → «5 PM», «SBO» → «SBO Card»);
- нормализует формат (даты, капитализацию, пунктуацию);
- собирает данные в чистый JSON;
- при необходимости восстанавливает контекст («Tour» отмечено кружком — значит, выбрано).
- Система валидации проверяет поля с низкой уверенностью Azure и подставляет исправления Gemini.
После того как мы применили этот подход, мы получили лучшие результаты. Вместе эти инструменты формируют систему, где человек нужен только в спорных случаях, а всё остальное идёт автоматически. Вот результаты:
- точность полей выросла с ~84 % (Azure DI в одиночку) до ~99 %;
- ручная проверка сократилась на 90–95 %;
- JSON стал полностью пригоден для загрузки в базу без ручного редактирования.
Хотите распознавать рукописные тексты?
Мы создаем ИИ-решения, способные обрабатывать и понимать документы с рукописными текстами. Давайте обсудим именно ваши рукописные тексты!Что делать, когда облако – не вариант?
Облачные OCR и LLM-платформы вроде Gemini, GPT-5 или Azure Document Intelligence уже обеспечивают почти идеальную точность и масштабируемость.
Но не все компании могут позволить себе отправить документ в облако и дождаться JSON. Иногда это просто запрещено политиками безопасности.
Если данные нельзя выносить в облако, ту же логику можно воспроизвести локально: Внутренний OCR → приватная LLM.
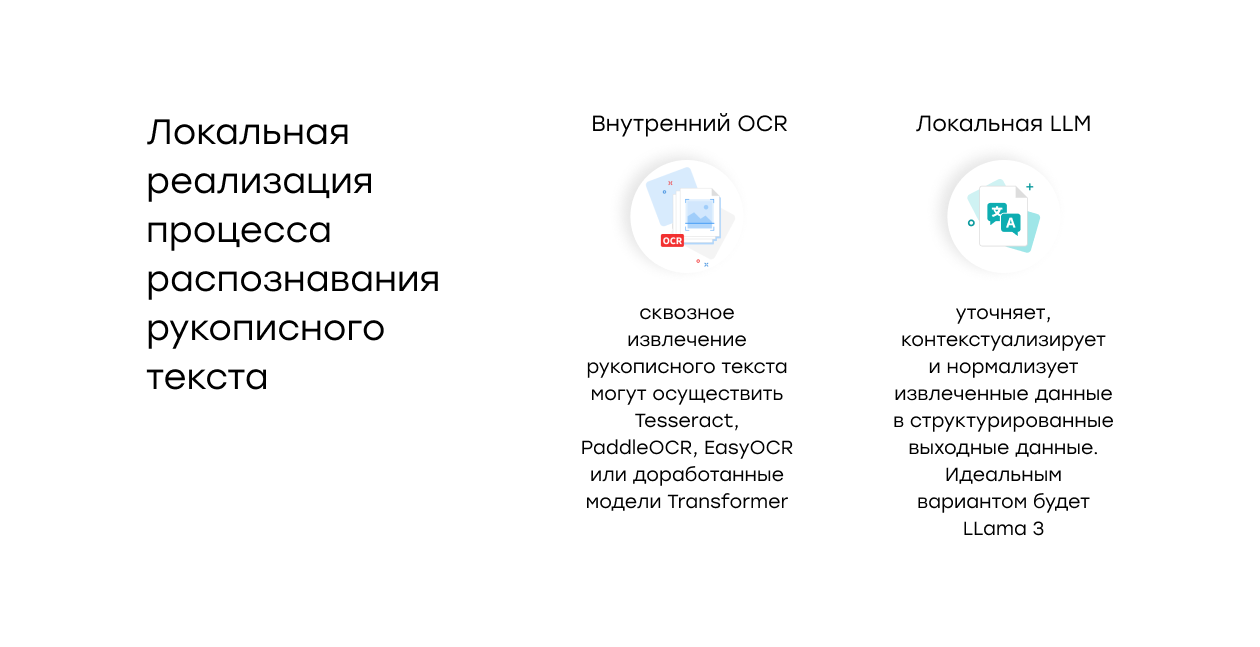
Локальный гибрид может быть идеален для некоторых компаний компаний, поскольку:
- Никакие данные не покидают инфраструктуру организации.
- Модели можно обучать и настраивать на образцах почерка, характерных для конкретной бизнес-темы.
- Работает в отключенных сетях или в средах с высоким уровнем безопасности.
- Единовременная стоимость установки и неограниченное использование.
- Возможность прямой подачи данных во внутренние озера данных или ERP-системы без внешних зависимостей.
Заключение и выводы
LLM действительно умеют читать почерк — не идеально, но с пониманием. И если раньше «распознать рукописную форму» означало час ручной чистки Excel, то теперь это вопрос одной модели и пары API-вызовов.
После трёх десятков тестов, сотен строк JSON и пары нервных шуток про курсив можно сделать несколько уверенных выводов.
- LLM-OCR перестал быть экспериментом. Гибриды вроде Azure DI + Gemini 2.5 Pro уже сегодня обеспечивают до 99 % точности и сокращают ручную проверку на 90–95 %.
- Gemini 2.5 Pro — оптимальный выбор для продакшена. Высокая структурная точность, стабильный JSON и лучшая цена за страницу делают его рабочей лошадкой enterprise-уровня.
- GPT-5 — лидер в понимании контекста. Он «думает» о смысле текста, но требует строгих схем и валидации, если данные идут в базу.
- Claude 4.5 Sonnet — отличный интерпретатор и storyteller, но не всегда детерминирован. Хорош для описательных задач, не для бухгалтерии.
- On-prem OCR — не про экономию, а про суверенность данных. Его выбирают не те, кто хочет сэкономить, а те, кто не может позволить себе облако.

Ищете партнёра для внедрения ИИ-решений?
Свяжитесь с нами, чтобы начать трансформацию вашего бизнеса.