ИИ для таможенных брокеров: ускоренная обработка инвойсов и автоматизация ГТД
Таможенный брокер каждый день имеет дело с десятками инвойсов, контрактов и упаковочных листов, от которых зависит скорость таможенного оформления грузов и отсутствие претензий со стороны таможни.
На практике это означает часы ручной обработки документов, поиска реквизитов и заполнения таможенной декларации (ГТД) по каждой поставке. Автоматизация таможенных брокеров на базе искусственного интеллекта позволяет снять значительную часть этой рутины: ИИ берёт на себя обработку инвойсов и подготовку данных для последующего заполнения ГТД.
Инвойс при этом остается ключевым документом, подтверждающим стоимость и характеристики товара, а любая неточность — в сумме, описании, коде товара или валюте — может привести к дополнительным проверкам, задержке груза и штрафам. На практике брокеры регулярно сталкиваются с ситуациями, когда из‑за одной описки или некорректного пересчета таможня усиливает контроль, доначисляет платежи или требует корректировки документов, что бьет и по срокам, и по репутации участников.
На этом фоне технологии искусственного интеллекта и большие языковые модели (LLM) открывают для брокеров возможность переложить большую часть рутины по работе с инвойсами на ИИ: автоматизировать распознавание, структурирование и проверку данных перед формированием ГТД.
В этой статье мы рассказываем, какие LLM модели лучше всего справляются с задачами брокера и как их можно встроить в повседневный процесс.
Попробуйте наше Демо!
Мы разработали сервис, в котором можно протестировать, как обученная нами AI-модель распознаёт ваши инвойсы и запросы на коммерческие предложения.
Цель и фокус исследования
В рамках исследования проверялась, насколько крупные языковые модели (LLM) подходят для автоматического нахождения «правильной» позиции среди множества похожих товарных записей по неструктурированному тексту запроса или инвойса.
По сути, моделям предлагали задачу, очень похожую на работу декларанта: по описанию товара в документе нужно выбрать корректную строку из базы, чтобы затем использовать её для расчёта стоимости и оформления документов.
Акцент был сделан не на выдуманных примерах, а на реальных промышленных данных: запросы содержали несколько позиций с разной степенью подробности и «шумом» в описаниях, а кандидаты — десятки и сотни близких товаров из каталога. Это позволяет напрямую переносить выводы исследования на задачи разбора товарных строк инвойсов и подготовки ГТД для таможенных брокеров.
Исследуемые модели
- GPT-5
- GPT-5 Nano
- Gemini 2.5 Pro
- Claude Sonnet 4
- Grok 4

Данные и сценарий тестирования
Мы взяли шесть реальных документов с запросами на подбор товаров, каждый из которых содержал несколько запрашиваемых позиций, всего 85 позиций во всех выборках.
Для моделей сценарий выглядел так: на вход подаётся кратко структурированное описание товарной позиции (по сути, то, что брокер видит в строке инвойса) и суженный список возможных соответствий из базы, а на выходе модель должна выдать топ‑5 наиболее подходящих вариантов.
Каждой модели было предоставлено до 500 позиций-кандидатов, отфильтрованных с помощью отдельного процесса поиска. Цель заключалась не в том, чтобы заново изобрести поиск по каталогу, а в том, чтобы оценить, насколько хорошо модели помогают сузить выбор до нужной позиции.

По сути, ИИ решает задачу, с которой ежедневно сталкивается таможенный брокер: по описанию из инвойса найти правильную позицию товара для последующего заполнения ГТД и определения таможенной стоимости.
Метрики и сравнение моделей
Чтобы оценить, насколько хорошо модели справляются с задачей, использовались три метрики, традиционно применяемые в бенчмарках по считыванию и ранжированию инвойсов и финансовых документов: Hit Rate@5, MRR и nDCG@5.
Hit Rate@5 показывает, как часто правильная позиция вообще попадает в топ‑5 рекомендаций, то есть насколько надёжен “короткий” список для ручной проверки.
MRR и nDCG@5 оценивают качество ранжирования: насколько высоко в списке обычно стоит корректный вариант и насколько полезен порядок рекомендаций для пользователя.
Результаты исследования: как себя показала каждая модель
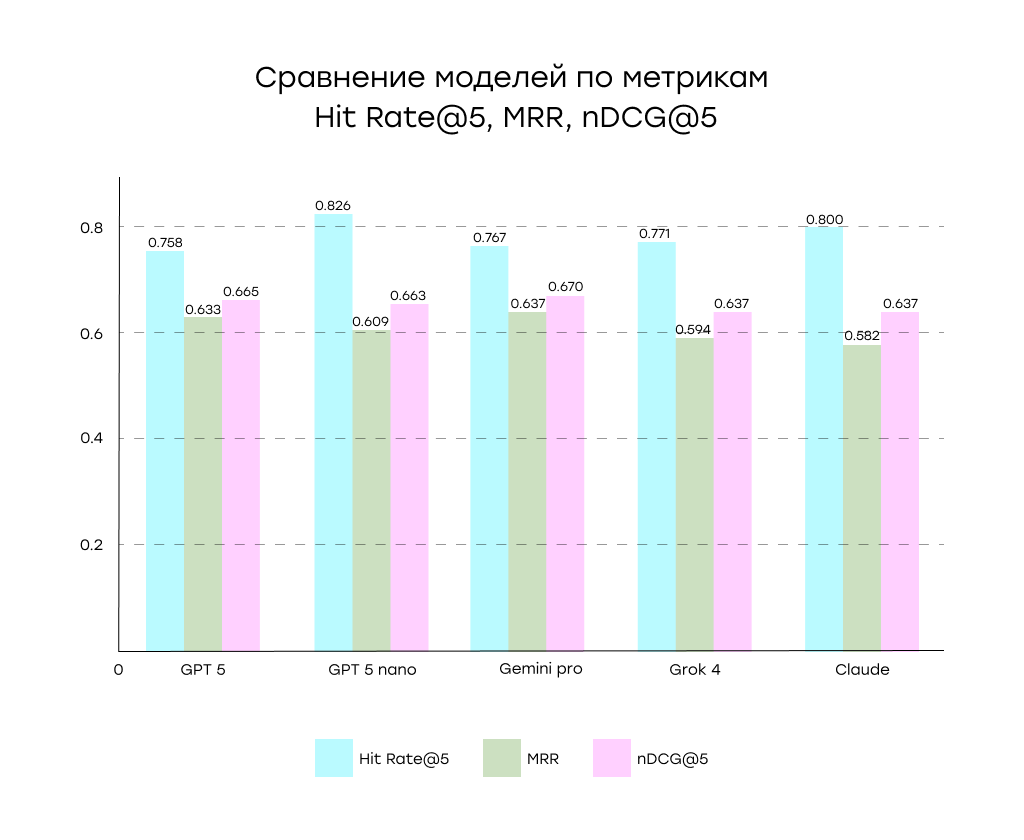
Когда дело доходит до использования ИИ для сопоставления элементов, не все модели ведут себя одинаково. Некоторые лучше справляются с тем, чтобы обеспечить попадание правильного элемента в шорт-лист, другие — с тем, чтобы элемент точно попал в первую позицию. Вот как пять протестированных моделей показали себя по трем ключевым показателям:
| Модель | Hit Rate@5 | MRR | nDCG@5 |
| Gpt 5 | 0.759 | 0.633 | 0.665 |
| Gpt 5 nano | 0.826 | 0.609 | 0.663 |
| Gemini 2.5 pro | 0.767 | 0.637 | 0.670 |
| Grok 4 | 0.771 | 0.594 | 0.637 |
| Claude sonnet 4 | 0.800 | 0.581 | 0.637 |
Анализ показал типичный для подобных задач компромисс: одни модели чаще попадают в топ‑5, но реже ставят правильный вариант на первое место, другие — включают правильный товар чуть реже, зато, когда включают, почти всегда ранжируют его выше конкурентов:

Лучший показатель попадания: GPT-5 Nano показал самый высокий показатель попадания в топ-5. Это идеальный вариант, если ваш процесс выполняется вручную, и вам просто нужно, чтобы правильный ответ попал в шорт-лист.
Лучшее качество ранжирования: Gemini 2.5 Pro показал лучшие результаты как по MRR, так и по nDCG, поместив правильный элемент ближе к началу при его нахождении. Если ваш рабочий процесс основан на доверии к выбору модели, это отличный выбор.
Сбалансированная производительность: GPT-5 продемонстрировал высокую эффективность ранжирования при высоком показателе попадания, что представляет собой эффективный баланс между двумя моделями.
Отличные показатели экономической эффективности: GPT-5 Nano и Grok 4 продемонстрировали отличную производительность при стоимости, составляющей лишь малую долю стоимости более крупных моделей, что делает их привлекательными вариантами для масштабирования.
Практическое применение для таможенных брокеров
С точки зрения таможенного брокера результаты исследования можно «упаковать» в очень приземлённый сценарий: система на базе LLM становится цифровым ассистентом, который разбирает инвойсы, подбирает корректные товарные позиции из вашей номенклатуры и готовит черновики ГТД вместо ручного перебора и ввода.
При этом модель не заменяет эксперта, а сокращает объём операционной рутины, оставляя человеку контрольные функции и сложные кейсы.
1. От инвойса к структурированным данным
На первом этапе система автоматизации обработки инвойсов для таможенных брокеров принимает сканы и PDF‑файлы, распознаёт их с помощью OCR, а затем передаёт текст в LLM. Модель извлекает структурированные данные, необходимые для таможенного оформления: реквизиты продавца и покупателя, валюту, суммы, строки товаров и итоги по документу.
На этом же шаге запускаются проверки, важные для корректного электронного декларирования товаров: сверка сумм, наличие обязательных полей для заполнения ГТД и контроль базовых параметров для расчёта таможенных платежей.
Попробуйте наше Демо!
Мы разработали сервис, в котором можно протестировать, как обученная нами AI-модель распознаёт ваши инвойсы и запросы на коммерческие предложения.
2. Интеллектуальный подбор товарных позиций
Дальше вступает в игру именно тот сценарий, который тестировался в вашем исследовании: для каждой строки инвойса формируется список кандидатов из вашей базы (каталог товаров, master‑данные, ранее оформленные поставки), а LLM доранжирует эти варианты и предлагает брокеру топ‑5 наиболее подходящих позиций.
Это снимает проблему поиска среди множества позиций, когда одно и то же изделие может называться по‑разному у поставщика, в инвойсе и во внутренней системе, но при этом именно правильная связка описания и номенклатуры критична для корректной стоимости и, в перспективе, для подбора кода ТН ВЭД.
Такой режим особенно полезен при больших партиях и длинных инвойсах: вместо ручного поиска по каталогу брокер за несколько кликов утверждает предложенный ИИ вариант или выбирает другой из короткого списка, экономя минуты на каждой строке и часы на партии.
При необходимости можно добавить отдельный модуль классификации, который на основе выбранной позиции подсказывает или уточняет ТН ВЭД, снижая риск ошибочного кодирования.
3. Контур контроля и «обучение на правках»
Ключевой момент для доверия брокеров — прозрачный контроль: каждая рекомендация LLM отображается вместе с объяснимым контекстом (какие слова в описании инвойса и карточки товара стали решающими), а финальное решение всегда остаётся за специалистом.
Исправления брокера не пропадают: система может использовать их как сигнал качества и постепенно подстраиваться под практику конкретной компании, улучшая ранжирование без отдельного дорогостоящего дообучения модели.
Такой “замкнутый цикл” позволяет стартовать с ассистивного сценария (ИИ как подсказчик) и со временем переходить к большей автоматизации. Например, к автоматическому принятию топ‑1 варианта по товарам с устойчивой историей безошибочного выбора. В результате доля полностью автоматических строк в ГТД растёт, а сотрудник переключается на разбор спорных и нестандартных случаев.
4. Интеграция с существующими системами брокера
С практической точки зрения такая LLM‑прослойка встраивается между документооборотом (почта, DMS, ERP, 1С) и системой подготовки деклараций:
на вход она получает инвойсы и доступ к справочникам,
на выходе отдаёт структурированные данные, готовые к загрузке в модуль ГТД.
Это может быть отдельный веб‑сервис, встраиваемый модуль в уже существующий софт брокера или облачная платформа с API — формат выбирается под архитектуру клиента.
Очень важно, как для таможенного брокера, так и для любого бизнеса, что предлагаемое нами решение, не требует менять основные бизнес‑процессы:
пользователи продолжают работать в знакомых системах, но получают умного помощника, который закрывает самую затратную по времени часть работы с инвойсами.
Именно такой приземлённый сценарий «от инвойса к готовому черновику ГТД с помощью LLM» лучше всего раскрывает практическую ценность вашего исследования для целевой аудитории статьи.
Ищете партнёра для внедрения ИИ-решений?
Свяжитесь с нами, чтобы начать трансформацию вашего бизнеса.
Заключение
ИИ в таможенном брокерстве уже стал реальным инструментом, который помогает быстрее разбирать документы, снижать количество ошибок и обрабатывать больше грузов тем же штатом.
Наше исследование LLM показывает, что такие системы способны не просто распознавать инвойсы, а осознанно подбирать правильные товарные позиции и формировать основу для ГТД, оставляя брокеру роль эксперта, а не оператора по вводу данных.
За счёт автоматизации ГТД и ключевых операций по обработке инвойсов один таможенный брокер может оформлять больше грузов без расширения штата. Время на подготовку таможенной декларации сокращается за счёт того, что ИИ сам подбирает товарные позиции и готовит черновики документов, а специалисту остаётся проверить и утвердить результат.
Это уменьшает количество ошибок при таможенном оформлении и снижает риски доначислений, связанных с некорректной таможенной стоимостью или неверно выбранным кодом ТН ВЭД.