Как крупный бизнес наводит порядок в данных с помощью n8n и AI
В крупных компаниях проблемы с данными почти никогда не возникают внезапно. Они накапливаются по мере роста бизнеса: появляются новые продукты и направления, подключаются поставщики, выходят новые рынки — и вместе с этим множатся IT-системы.
Каждый шаг по отдельности выглядит рационально: внедрили ещё одну CRM, добавили внешний сервис, сделали интеграцию «временно». Но в какой-то момент источников становится столько, что удерживать единые правила работы с данными уже не получается. Одни и те же сущности начинают по-разному называться в разных системах, форматы расходятся, справочники перестают совпадать.
Важно, что это не следствие плохой дисциплины. Это нормальный эффект роста. Бизнесу нужно двигаться быстро, а логика обработки данных не успевает эволюционировать с той же скоростью. В результате появляются ручные проверки, локальные договорённости между командами и зависимость от «знаний в головах».
Со временем это начинает напрямую влиять на операционную эффективность. Любые изменения стоят всё дороже, автоматизация перестаёт масштабироваться, а качество данных начинает влиять на управленческие решения. И становится ясно: проблема не в объёме данных и не в хранилищах, а в отсутствии управляемой логики их обработки.
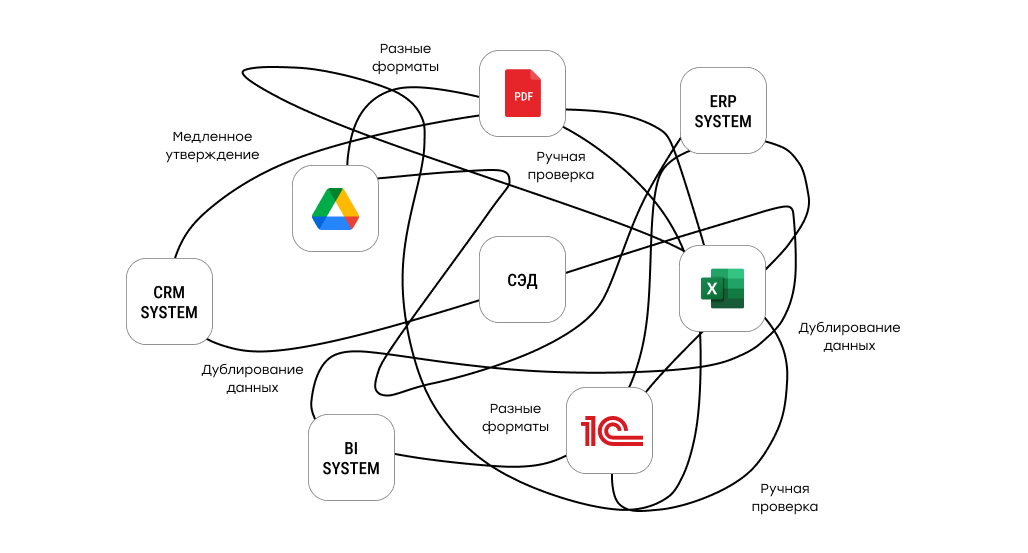
Почему классические подходы перестают работать
Традиционно компании решали проблемы с данными довольно прямолинейно. Где возможно — вводили строгие правила и валидации, где сложно — добавляли ручную проверку. Для автоматизации писали SQL, скрипты и ETL-пайплайны. На старте это действительно работает и даёт быстрый эффект.
Но по мере роста такие решения начинают ломаться. Жёсткие правила плохо переживают вариативность входных данных. Запросы, которые отлично работали на сотнях строк, становятся узким местом на тысячах и десятках тысяч. Любое исключение — новый формат, нестандартное значение, неожиданный поставщик — снова возвращает человека в процесс.
Отдельная боль возникает, когда логика обработки “размазывается” по разным слоям. Часть правил живёт в базе, часть — в интеграциях, часть — в коде сервисов, часть — в регламентах. В такой архитектуре сложно понять, где именно принимается решение и что нужно менять, когда обновляются бизнес-требования.
Попытки решить проблему за счёт более тяжёлых платформ тоже не всегда срабатывают. Такие проекты требуют времени, денег и стабильности требований, а в реальности источники данных продолжают меняться. В итоге классические подходы либо оказываются слишком жёсткими для изменений, либо слишком хрупкими для масштабирования и начинают тормозить бизнес.
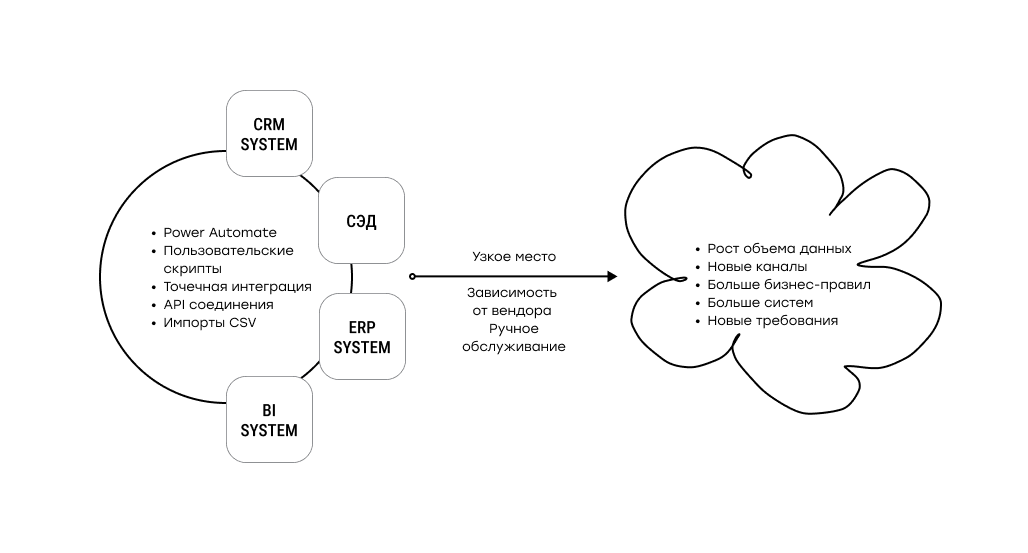
N8N как процессный слой для управления данными
Когда становится ясно, что проблема не в отдельных скриптах и не в хранилищах, фокус смещается на процесс. Данными нужно не просто владеть — ими нужно управлять: понимать, откуда они приходят, какие шаги проходят и где принимаются решения.
В этой роли n8n выступает как процессный слой, который связывает существующие системы между собой. Он не заменяет базы данных, DWH или корпоративные приложения, а выносит логику обработки в единый, наблюдаемый контур. Через него проходят загрузка данных, преобразования, вызовы внешних сервисов, проверки и маршрутизация.
n8n — это инструмент для автоматизации: он помогает связывать разные программы и сервисы в цепочки действий (например, «получить данные → обработать → записать в другую систему») без постоянной ручной работы.
Сценарии собираются в виде схемы из отдельных шагов, где один шаг запускает следующий, поэтому удобно строить процессы из нескольких этапов и подключать много разных источников данных.
Плюсы n8n
- Подходит, когда нужно “подружить” между собой почту, таблицы, мессенджеры, базы данных и внутренние учетные системы в единый процесс.
- Можно установить на свой сервер и держать данные внутри компании, либо пользоваться готовым размещением у поставщика.
- Есть много готовых подключений и заготовок, а для нестандартных задач можно добавлять свои шаги и правила.
Для крупного бизнеса это особенно важно, ведь данные почти всегда проходят через несколько систем, каждая из которых отвечает за свою часть. n8n позволяет описать эту цепочку как единый процесс, не привязываясь к конкретному вендору или стеку, и при этом спокойно работать в on-premises или гибридной инфраструктуре.
Ключевое преимущество — управляемость изменений. Когда появляются новые источники или меняются правила обработки, процесс не приходится пересобирать с нуля. Логика дорабатывается по шагам, оставаясь прозрачной и контролируемой. В результате автоматизация перестаёт быть набором разрозненных решений и становится частью архитектуры.
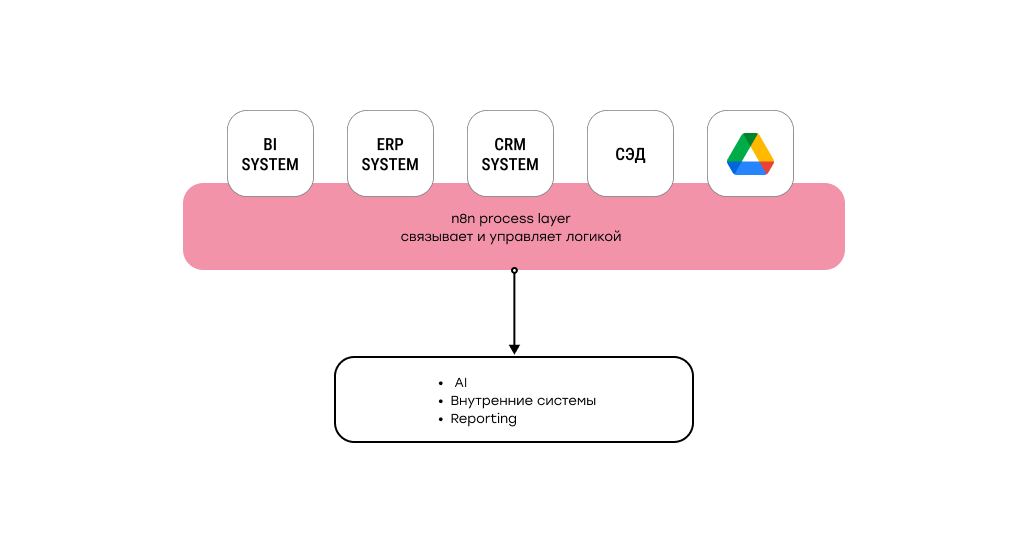
Где в этой архитектуре появляется AI и LLM
Рост объёмов данных почти всегда приводит к одному и тому же ограничению: классические правила перестают работать там, где данные становятся вариативными. Разные формулировки, свободный текст, несогласованные справочники и форматы сложно заранее описать жёсткой логикой.
Именно здесь появляется практическая ценность AI и LLM. Они позволяют работать не со строками и правилами, а со смыслом — классифицировать, сопоставлять и нормализовать данные там, где формальные подходы дают сбой. Но сами по себе модели не решают задачу. Без чёткой логики вокруг них AI быстро превращается в источник нестабильных результатов и неконтролируемых затрат.
В зрелой архитектуре LLM — это не самостоятельный слой, а один из шагов внутри управляемого процесса. n8n позволяет встроить AI именно таким образом: понятно, когда и зачем вызывается модель, какие данные она получает и как используется результат. В итоге AI становится не экспериментом, а рабочим инструментом, встроенным в предсказуемый конвейер обработки данных.
Кейс: как мы оптимизировали конвейер обработки товарных данных на базе n8n
В одном из проектов n8n уже использовался как основной конвейер обработки данных. Клиент — реселлер бытовой электроники, который ежедневно получал прайс-листы от нескольких поставщиков с тысячами товарных позиций. Эти данные нужно было автоматически сопоставлять с внутренним каталогом товаров и складскими остатками.
Проблема была типовой для крупного бизнеса: одинаковые устройства у разных поставщиков описывались по-разному. Менялись формулировки, порядок слов, артикула и дополнительные пометки. Простое сопоставление по строкам переставало работать, а объём ручной проверки рос вместе с каталогом.
Протестируйте автоматизацию поступающих заявок и КП
Мы разработали демо версию на прогрессивной ИИ-модели, чтобы вы увидели, как ИИ может помочь с работой над заявками и коммерческими предложениями.
Со временем существующий пайплайн начал упираться в ограничения. Импорты обрабатывались медленно, LLM давали нестабильные результаты из-за неструктурированных промптов, а каждая позиция запускала отдельный SQL-запрос. При росте объёмов именно база данных стала главным узким местом.
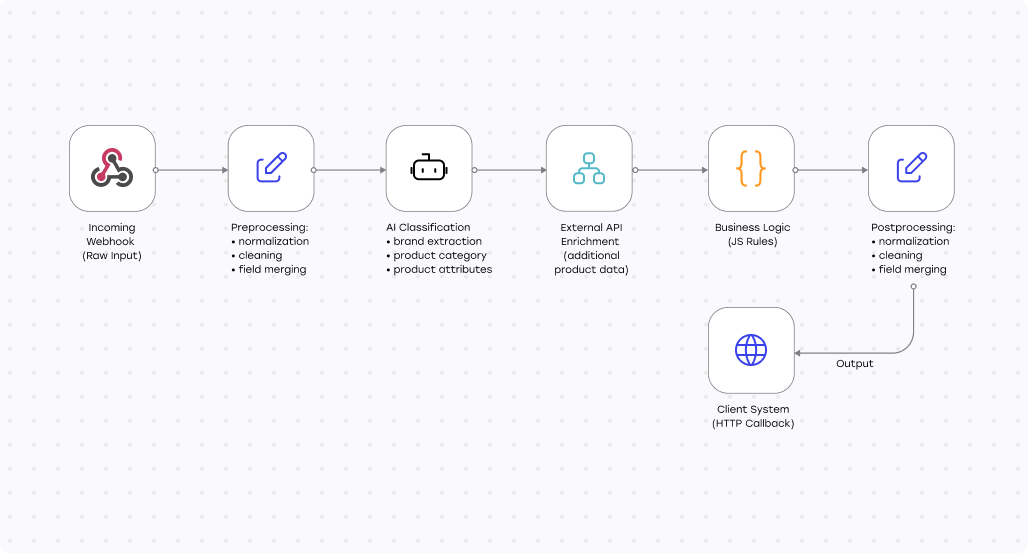
Мы переработали пайплайн, не меняя базовый стек, а усилив его архитектурно. Логику работы с LLM объединили в один структурированный промпт, сократив количество вызовов и повысив стабильность результатов. Сам workflow в n8n упростили, убрав избыточные шаги, которые мешали масштабированию.
Ключевым изменением стал отказ от последовательных SQL-запросов в пользу векторного поиска. Мы внедрили Qdrant и перевели сопоставление товаров в семантическую плоскость. Вместо точных совпадений по строкам система начала подбирать релевантные варианты по смыслу и сравнивать их пакетно.
В результате импорт стал проходить примерно в 2,5 раза быстрее, поиск по базе ускорился в 5–10 раз, а объём ручной проверки заметно сократился. n8n в этой архитектуре выступает не вспомогательным инструментом, а центральным процессным слоем, через который проходит вся логика обработки данных.
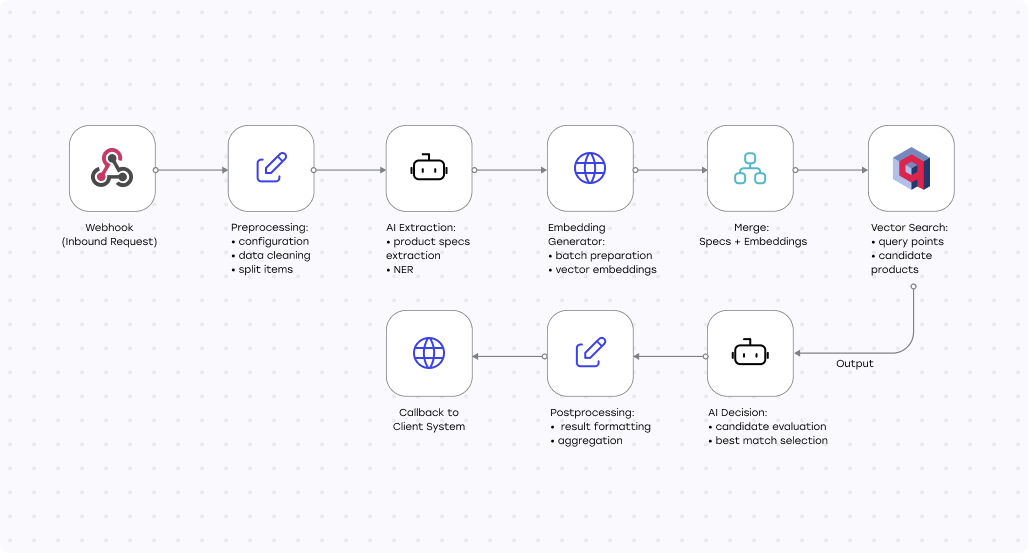
Результаты: что изменилось после оптимизации
После переработки пайплайна система перестала быть узким местом в ежедневной обработке данных. Полный цикл импорта стал проходить примерно в 2,5 раза быстрее и сохранил эту скорость при росте объёмов.
За счёт структурированных промптов и сокращения количества вызовов LLM повысилась стабильность работы AI-части конвейера. Это дало не только ускорение, но и более предсказуемые результаты, что критично для операционных процессов.
Переход к векторному поиску стал ключевым фактором масштабирования. Вместо тысяч последовательных SQL-запросов система начала работать с данными пакетно, подбирая кандидатов по смыслу. Поиск по базе ускорился в 5–10 раз, а точность сопоставления выросла настолько, что объём ручной проверки заметно сократился.
Что этот кейс показывает бизнесу
Этот проект наглядно показывает, что порядок в данных — это не вопрос одного инструмента или технологии. Он достигается за счёт архитектуры, в которой логика обработки данных вынесена в отдельный, управляемый слой.
AI в таком подходе не заменяет систему правил, а дополняет её там, где классические методы не справляются. Встроенный в процесс, он становится предсказуемым и экономически оправданным инструментом, а не экспериментом.
Важно и то, что n8n в этом кейсе выступает не как временное решение, а как устойчивая часть архитектуры. Он позволяет развивать процессы по мере роста бизнеса, не пересобирая систему целиком и не создавая новых узких мест.
Когда n8n становится стратегическим инструментом
Во многих компаниях автоматизация начинается с локальных задач, но со временем превращается в сложную сеть процессов и интеграций. В этот момент становится важно не просто автоматизировать отдельные шаги, а управлять всей логикой целиком.
n8n хорошо подходит для этой роли. Он позволяет вынести бизнес-процессы в отдельный слой, не привязанный к конкретным системам или вендорам. Для международных и распределённых компаний это особенно ценно: изменения в одном контуре не требуют перестройки всей архитектуры.
При таком подходе автоматизация перестаёт быть разовым проектом и становится непрерывным процессом развития — без остановки ключевых операций и без зависимости от жёстких платформенных ограничений.
Заключение
Наведение порядка в данных — это не разовая оптимизация и не внедрение очередной платформы. Это способность компании выстраивать процессы так, чтобы данные оставались управляемыми при росте объёмов, источников и требований к скорости.
Кейс с оптимизацией пайплайна на базе n8n показывает, что даже сложные и нагруженные сценарии можно сделать устойчивыми без тяжёлых монолитных решений. Связка n8n, AI-моделей и современных подходов к поиску данных позволяет превратить разрозненную информацию в рабочий актив.
В условиях, когда данные напрямую влияют на операционную эффективность и скорость принятия решений, такая архитектура становится не техническим выбором, а конкурентным преимуществом бизнеса.
Ищете партнёра для внедрения ИИ-решений?
Свяжитесь с нами, чтобы начать трансформацию вашего бизнеса.