Как мы протестировали AI-модели на извлечение данных из счетов: победитель удивил
Обработка счетов — важная и рутинная часть документооборота, которую всё чаще доверяют AI-моделям. Мы провели практическое исследование и сравнили, как с этой задачей справляются разные решения: от популярных open-source моделей до коммерческих API.
Исследование включало несколько этапов: мы собрали разнообразный датасет из реальных счетов, привели его к единому формату, определили метрики и протестировали 7 популярных на наш взгляд моделей, чтобы понять:
- Кто лучше справляется с извлечением данных?
- Насколько точны LLM «из коробки»?
- Стоит ли платить больше за детали?
В этой статье изложим краткие выводы, графики и наши рекомендации для тех, кто выбирает AI для invoice-процессинга.
Хотите больше узнать про ИИ-обработку документов?
Мы умеем обрабатывать различные документы при помощи ИИ, какие, узнайте по ссылке.
Что и как мы тестировали
Датасет
Датасет состоял из 20 реальных счетов-фактур разного формата и “возраста” (от 2006 до 2020 года), это были:
- Оцифрованные PDF и сканы с низким разрешением,
- Документы с нестандартной структурой (обернутый текст, подпункты, пропущенные суммы),
- Счета на английском языке, но с разной версткой и плотностью текста.
Извлекаемые данные
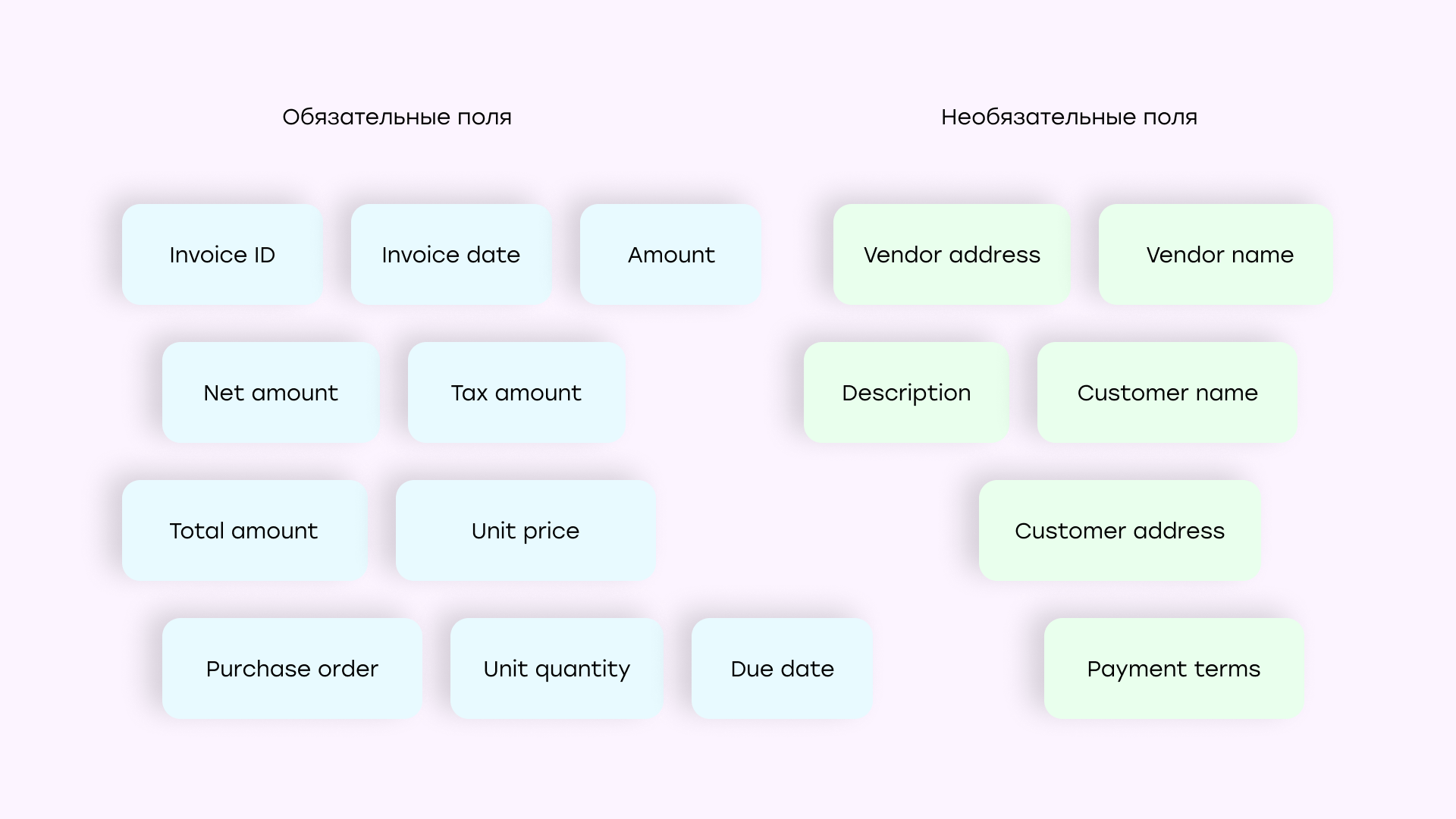
Извлекали 16 полей, таких как даты, суммы, имена, адреса и данные по позициям (описание, количество, цена, сумма). Поскольку каждое решение могло по-своему называть каждое поле, мы придумали формат названий и следовать этому формату, чтобы все результаты были единообразны.
AI-модели

Мы сравнивали 7 решений:
- Amazon Analyze Expense (AWS)
- Azure AI Document Intelligence
- Google Document AI (Invoice Parser)
- GPT-4o API — ввод текста с помощью стороннего OCR (gptt)
- GPT-4o API — ввод изображения (gpti)
- Gemini 2.0 Pro
- Deepseek v3 (через текст + OCR)
Метрики
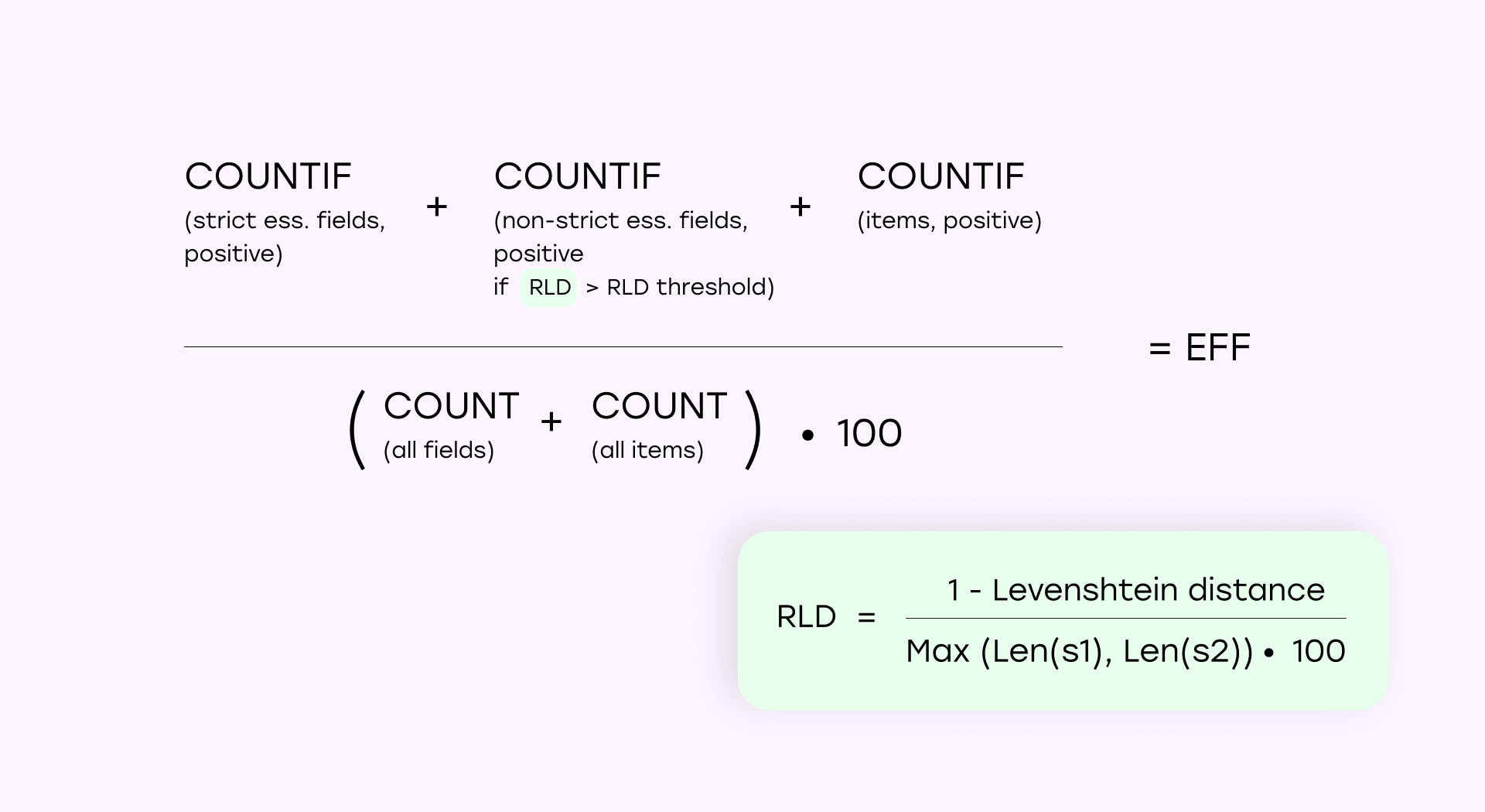
Для каждой модели мы рассчитывали показатель Eff (%) — взвешенная метрика эффективности для количественной оценки точности извлечения. Эта метрика объединяет:
- Строго обязательные поля: точные совпадения (например, идентификатор счета-фактуры, даты).
- Нестрогие обязательные поля: частичное совпадение допускается, если сходство (Относительное расстояние Левенштейна RLD, %) превышает пороговое значение.
- Позиции из счета-фактуры: оцениваются как правильные только в том случае, если все атрибуты элемента извлечены точно.
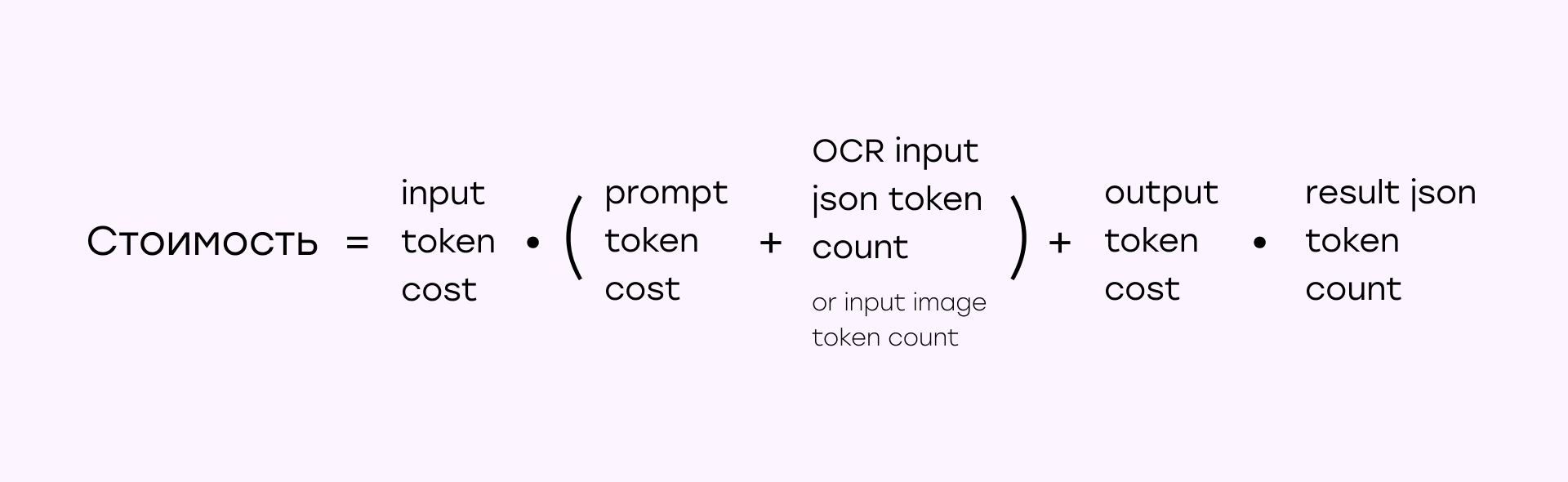
Методология расчета затрат
Расчет затрат на услуги искусственного интеллекта рассчитывались по факту, с учетом:
- Затрат на основе токенов (вход/выход) для текстовых моделей.
- Стоимости обработки изображений для моделей с поддержкой технического зрения (GPT-4o/Gemini).
Основные выводы
Мы не просто так разбили содержимое счетов на несколько категорий: обязательные поля, необязательные поля и позиции из счетов-фактур. Потому что модели “сыпались” в основном на позициях из счетов фактур.
Вот, обобщенные результаты распознавания счетов. В лидерах - AWS, в проигравших Google - данная модель не сумела разбить позиции на отдельные сущности, все выгрузила единой строкой.

Но если мы выгрузим только основные поля, не рассматривая результаты по позициям из счетов-фактур, то результаты будут совсем иными. Здесь лучше всех себя показал Deepseek, а хуже всех - снова Google.

1. Gemini — лидер по точности и структуре
Модель от Google DeepMind (Gemini 2.0 Pro) показала лучшую точность по всем метрикам. Она корректно извлекала как базовые поля (дата, сумма, реквизиты), так и вложенные товарные позиции.
Преимущества:
- Четкая структура JSON: без лишнего текста и форматирования.
- Устойчивость к многострочным описаниям: даже если описание товара разбито переносами, модель сохраняет смысл.
- Точное извлечение чисел: без округлений и подмен (в отличие от GPT).
Особенность: Gemini требует более длинных промптов, но при правильной формулировке возвращает данные в табличной структуре, близкой к бухгалтерским системам.
2. GPT-4o хорош, но не без слабых мест
Вариант GPT-4o с текстовым вводом через OCR (например, AWS Textract) показал достойную точность. Однако при использовании изображений (ввод в виде PDF или скана) модель иногда:
- Путает числовые значения, особенно когда цифры идут подряд (например, сумма и налог),
- Округляет дробные значения,
- Вставляет домыслы, если не уверена (например, генерирует поле, которого нет в счете).
Тем не менее, GPT можно использовать эффективно при:
- ручной постобработке,
- ясных шаблонах счетов,
- явных ограничениях в промптах (например, «не додумывай, если поле отсутствует»).
3. Google Document AI не подходит для извлечения позиций
Проблема модели в том, что она возвращает неструктурированный текст для табличных блоков: строка с описанием, количеством и ценой объединяется в одну длинную строку. Это исключает автоматическую постобработку или интеграцию в бухгалтерский софт.
Google не поддерживает:
- разбиение на поля description / quantity / unit price / amount,
- форматы JSON или XML для табличных данных.
Вывод: использовать Google Document AI можно только для простых счетов, где нужны общие суммы и реквизиты.
4. AWS и Azure стабильны, но не гибки
Классические API от AWS и Microsoft:
- Надежны при извлечении фиксированных полей,
- Работают даже с низким разрешением и плохо отсканированными PDF,
- Быстро обрабатывают поточные документы в корпоративных системах.
Но у них есть ограничения:
- Azure не справляется с многословными описаниями (например, в одном случае выдало только фамилию вместо полного имени),
- AWS пропускает позиции, если поля quantity или amount отсутствуют — даже если остальная информация есть.
5. Deepseek — экспериментальный и нестабильный
Модель Deepseek v3 показала наихудшую точность среди всех решений. Характерные проблемы:
- Ошибки при извлечении чисел (например, 1.000 → 1000),
- Пропуски полей без видимых причин,
- Плохая совместимость с многострочным текстом и «грязными» сканами.
Тем не менее, Deepseek может быть интересен как недорогой open-source вариант для задач, где качество вторично.
Протестируйте автоматизацию поступающих заявок и КП
Мы разработали демо версию на прогрессивной ИИ-модели, чтобы вы увидели, как ИИ может помочь с работой над заявками и коммерческими предложениями.
6. Качество изображений влияет слабо
Мы проверяли поведение моделей на сканах 150–200 DPI. Почти все решения, кроме Deepseek, выдержали тест:
- AWS, Azure, GPT, Gemini корректно извлекали данные даже при плохом контрасте или сжатии,
- Проблемы возникали только в крайних случаях: например, Deepseek принял запятую за точку и исказил сумму.
Получается, что современные модели достаточно устойчивы к качеству входных изображений.
7. Нестандартные счета ломают все модели
Мы исключили 2 образца из анализа, потому что у них не было явных полей суммы или количества в товарных строках, а также были вложенные подпункты без обозначения уровней и табуляции.
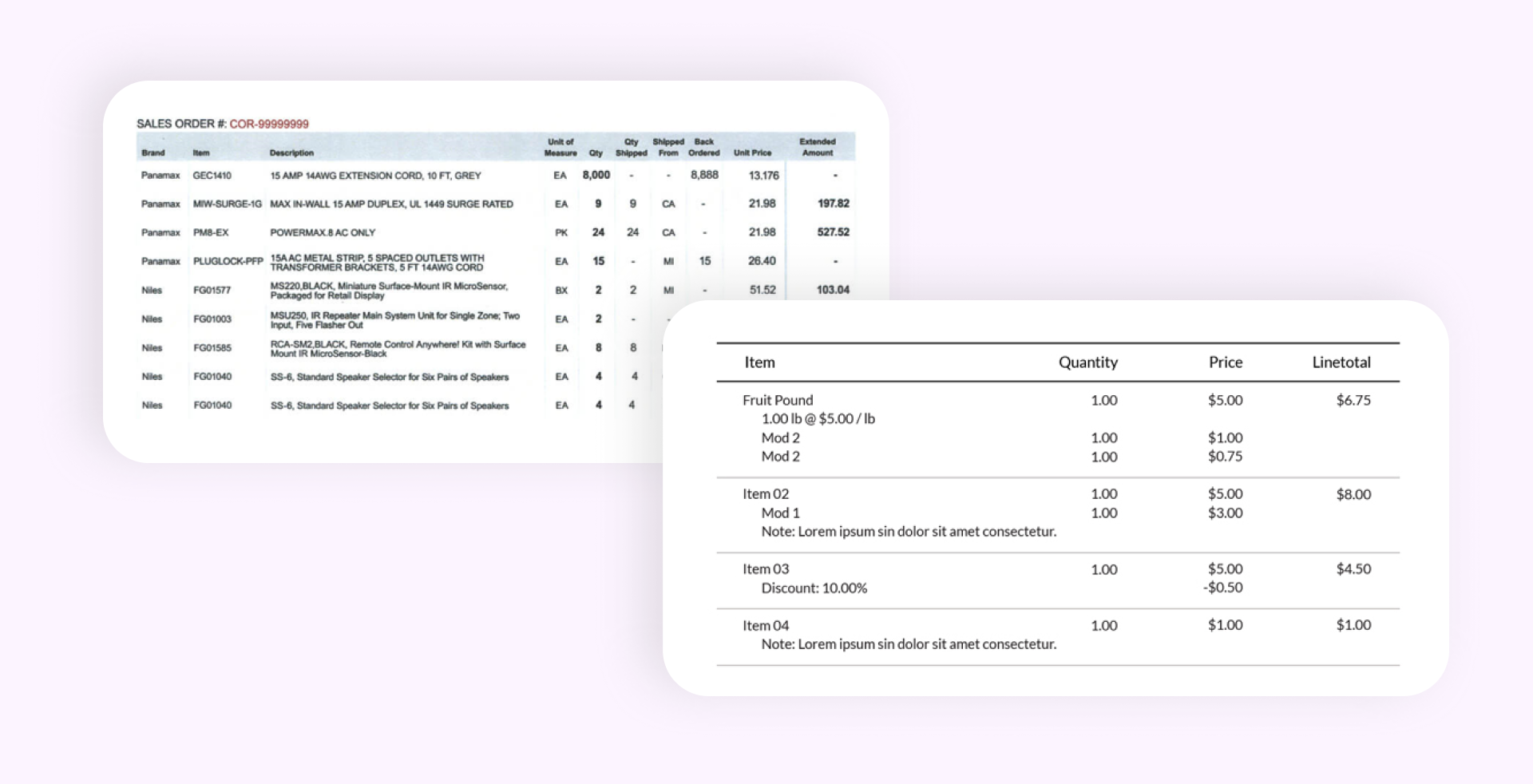
Ни одна модель (даже Gemini) не смогла корректно восстановить структуру таких документов. Это означает, что:
- AI-модели всё ещё плохо справляются с кастомными форматами счетов,
- Без подготовки и тонкой настройки — особенно на своём датасете — их нельзя сразу запускать в production.
Cравнение стоимости
| Сервис | Стоимость | Стоимость одной страницы (в среднем) |
| AWS | $10 / 1000 страниц 1 | $0.01 |
| Azure AI Document Intelligence | $10 / 1000 страниц | $0.01 |
| Google Document AI (Invoice Parser) | $10 / 1000 страниц | $0.01 |
| GPTT: текст GPT-4o | $2,50 / 1M входных жетонов, $10,00 / 1M выходных жетонов 2 | $0.021 |
| GPTI: Только GPT-4o | $2,50 / 1M входных токенов, $10,00 / 1M выходных токенов | $0.0087 |
| Gemini 2.0 Pro | $1.25, ввод подсказок ≤ 128k токенов $2.50, входные подсказки > 128k токенов $5.00, выходные подсказки ≤ 128k токенов $10.00, выходные подсказки > 128k токенов |
$0.0045 |
| API Deepseek v3 | $10 / 1000 страниц + $0,27 / 1M входных токенов, $1,10 / 1M выходных токенов | $0.011 |
Примечания:
- $8 / 1000 страниц после одного миллиона в месяц
- Дополнительные $10 за 1000 страниц при использовании модели распознавания текста
Наши рекомендации и выводы

- Если важно максимально точное извлечение стандартных полей по стабильной цене — используйте Deepseek или AWS.
- Если требуется извлекать позиции товаров в структурированном виде — лучший выбор Gemini, к тому же достаточно дешевое решение.
- Если нужен компромисс между качеством, гибкостью и ценой — GPT-4o (текстовый ввод с OCR).
- Если работаете со стабильными шаблонами — Azure подойдёт как надёжное решение.
- Не используйте Google Document AI, если вам нужна структурированная разбивка по товарам.
Обдумываете IDP решение?
Мы создаем индивидуальные системы по обработке документов при помощи искусственного интеллекта.