ИИ наконец научился читать почерк: что изменилось в 2026 году
В 2026 году распознавание почерка перестало быть узкой задачей для айтишников и стало нормальным бизнес-инструментом. Современный ИИ уже не просто «видит буквы», а понимает контекст, восстанавливает пропущенные куски и сразу выдаёт чистый текст, который можно загружать в CRM, BI и рекламные платформы.
Бумажные анкеты, брифы, опросы, регистрационные формы, заметки с мероприятий — всё это теперь автоматически превращается в структурированные цифровые данные. А гибрид OCR + LLM даёт точность 95–99%, что раньше казалось фантастикой.
Для маркетинга это открывает новые сценарии: сбор офлайн-данных без ручного ввода, глубокая аналитика фидбэка, быстрый подъём архивов под исследования и стратегии. Это не очередной AI-хайп, а способ снять рутину с команд и работать с данными быстрее и чище.
Почему распознавание почерка так долго было проблемой
Почерк — хаос. У всех разный стиль, наклон, размер букв, сокращения, пометки на полях. Иногда — смесь алфавитов. Для машин это настоящий визуальный джаз, в котором сложно выделить стабильные паттерны.

Классические OCR-системы умели работать только с аккуратным печатным текстом. Они видели пиксели, но не понимали смысл, поэтому «сыпались» на кривых строках, размытых сканах, слияниях букв и любом отклонении от идеальной формы. Плюс рукописные документы сами по себе часто очень разные: таблицы «уезжают», строки пересекаются с рамками, структура нарушена. Это ещё сильнее усложняло автоматизацию.
В итоге обработка рукописных данных требовала много ручной правки, была дорогой и неточной. Но всё это было пока не появились более мощные AI-подходы.
Прорыв 2026: на сцену выходят LLM
Главным сдвигом в распознавании почерка в 2026 году стало подключение больших языковых моделей. В отличие от классических OCR, которые видят только символы, LLM понимают смысл текста и работают с ним как с полноценным сообщением.
Они угадывают, что автор хотел написать, исправляют ошибки, восстанавливают пропуски, держат контекст и «склеивают» разрозненные фрагменты даже в сложных формах. Благодаря этому вместо сырых символов получается готовый, логичный текст, который можно сразу загружать в системы аналитики и автоматизации.
Когда LLM соединили с современными алгоритмами обработки изображений, точность распознавания выросла до рекордных значений — это стало настоящим технологическим прорывом.
Гибридный подход: OCR + LLM
Ключевое открытие 2026 года — связка OCR и LLM. Они отлично дополняют друг друга.
- OCR быстро вытаскивает символы с изображения, убирает шумы, распознаёт буквы и цифры, но не понимает смысла и не умеет исправлять логические ошибки.
- LLM берёт результат OCR, восстанавливает контекст, исправляет опечатки, «склеивает» обрывки и приводит текст к нормальной структуре, при этом может сразу перевести текст на другой язык.
По сути, OCR делает черновик, а LLM превращает его в готовый, читабельный и корректный текст.
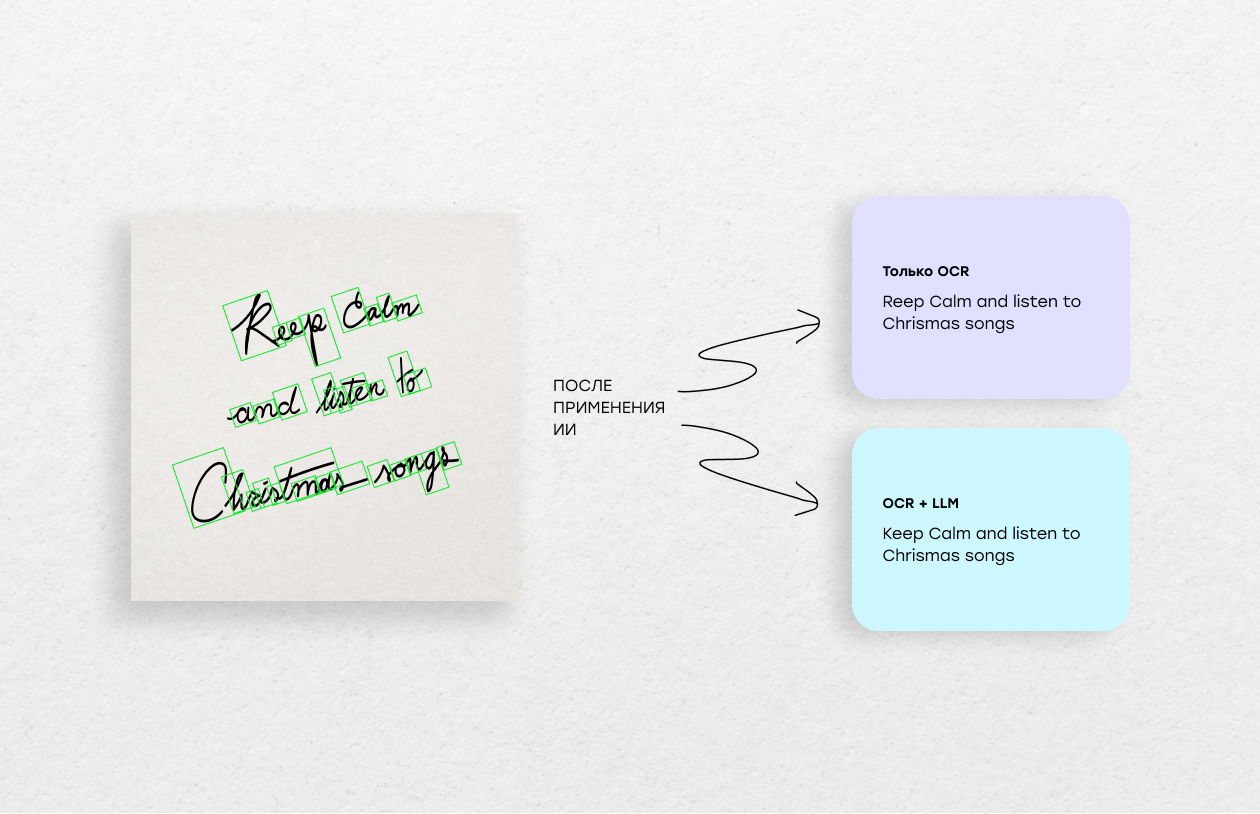
Такой гибрид резко сокращает количество ошибок и позволяет обрабатывать даже самые сложные рукописные формы — без ручной правки и за минимальное время. Для бизнеса это означает быстрое и недорогое превращение любых рукописных документов — анкет, архивов, записок — в чистые цифровые данные, готовые к аналитике и автоматизации.
Обдумываете IDP решение?
Мы создаем индивидуальные системы по обработке документов при помощи искусственного интеллекта.
Наш мини-тест: как LLM справились с рукописным текстом
В рамках исследования протестировали три современных LLM — Gemini 2.5 Pro, GPT‑5 и Claude Sonnet 4.5 — на трёх реально «грязных» рукописных документах: форме регистрации, анкете и медицинском бланке.

Что получилось:
Gemini 2.5 Pro стабильно лидировала: давала 98–99% точности по символам, 99–100% — по корректному извлечению полей, и почти идеальный JSON.
GPT-5 оказался сильнее в семантике и «человечности» текста — он лучше понимал контекст и смысл, хотя иногда путал имена или структуру.
Claude 4.5 давал менее чистый результат: чаще терялись пробелы, пунктуация, были ошибки в полях.

Что это значит для digital-маркетинга и рекламы
Во-первых, рукописные данные больше не надо вручную переносить в Excel: анкеты, регистрации и заявки с офлайн-мероприятий автоматически превращаются в аккуратные цифровые записи, что ускоряет запуск аналитики.
Во-вторых, качество данных заметно растёт: то, что раньше терялось из-за кривого почерка, теперь распознаётся корректно, повышая точность сегментаций и персонализации, а значит, и эффективность кампаний. В-третьих, открывается пространство для новых форм взаимодействия: автозаполнение форм, моментальное сканирование заметок «с полей», быстрые фидбэк-механики на мероприятиях. UX становится проще и живее, а вовлечённость — выше.
Плюс гибридные AI-системы можно запускать локально, без отправки данных в облако, что важно для работы с чувствительной информацией и крупными клиентами. В итоге маркетинг получает инструмент, который делает процесс быстрее, чище и умнее, повышая ROI и качество коммуникаций.
Настоящий must-have 2026 года
В 2026 году распознавание почерка наконец вышло на новый уровень — благодаря связке классического OCR и больших языковых моделей. Теперь даже сложные рукописные документы можно быстро оцифровывать без потери смысла и с минимальными ошибками.
Для digital-маркетинга это значит больше автоматизации, чище данные, точнее аналитику и новые форматы взаимодействия с аудиторией. Гибридные AI-системы превращают хаотичные архивы, анкеты и полевые заметки в ценный цифровой актив, который работает на стратегию и рост ROI.
Распознавание почерка стало не техническим трюком, а полноценным инструментом повышения эффективности и конкурентоспособности брендов.
Ищете партнёра для внедрения ИИ-решений?
Свяжитесь с нами, чтобы начать трансформацию вашего бизнеса.