Как мы научили ИИ подбирать мебель по архитектурным чертежам
Перед вами PDF документ на 30 страниц с десятками архитектурных чертежей (elevation). На каждом кухня, ванная или офис с рядами шкафов. Ваша задача: определить каждый шкаф на чертеже, понять его тип, подсчитать количество дверей и полок, считать размерности и по этим данным найти наиболее подходящие позиции в каталоге мебели, который содержит сотни артикулов.
В мире строительства и дизайна интерьеров эту работу до сих пор делают вручную: специалисты часами листают каталоги, сверяют размеры и характеристики. Строительные компании, дизайн-студии, подрядчики по отделке все они сталкиваются с одной и той же рутиной, которая отнимает десятки человеко-часов на каждый проект.
Мы решили автоматизировать этот процесс и построили систему, которая принимает на вход PDF с архитектурными чертежами и каталог мебели, а на выходе даёт список рекомендаций с точностью 87%.
В этой статье мы расскажем, как проходили путь от наивной веры в всемогущие vLLM до продуманного пайплайна, комбинирующего YOLO детекцию, кластеризацию компьютерного зрения, Gemini для извлечения признаков и трансформеров для семантического поиска по каталогу.
Хотите заказать решение для обработки чертежей?
Напишите нам!
И мы разработаем решение для обработки ваших чертежей!
Наивный подход: скормить всё в LLM
Первая мысль была простой и, как потом оказалось, наивной. Зачем писать сложную систему, если можно отправить изображение чертежа вместе с PDF каталогом прямо в мультимодальную модель? Берём лучшую vLLM, даём ей всё в контекст и получаем результат.
Мы начали с Gemini 2.5 Pro, которая на момент тестирования показывала лучшие результаты в визуальных задачах. Отправляли фото плана и урезанный каталог из 15 страниц, на каждой по 10-16 шкафов. Для простых типов мебели модель справлялась, могла найти и порекомендовать нужный шкаф.
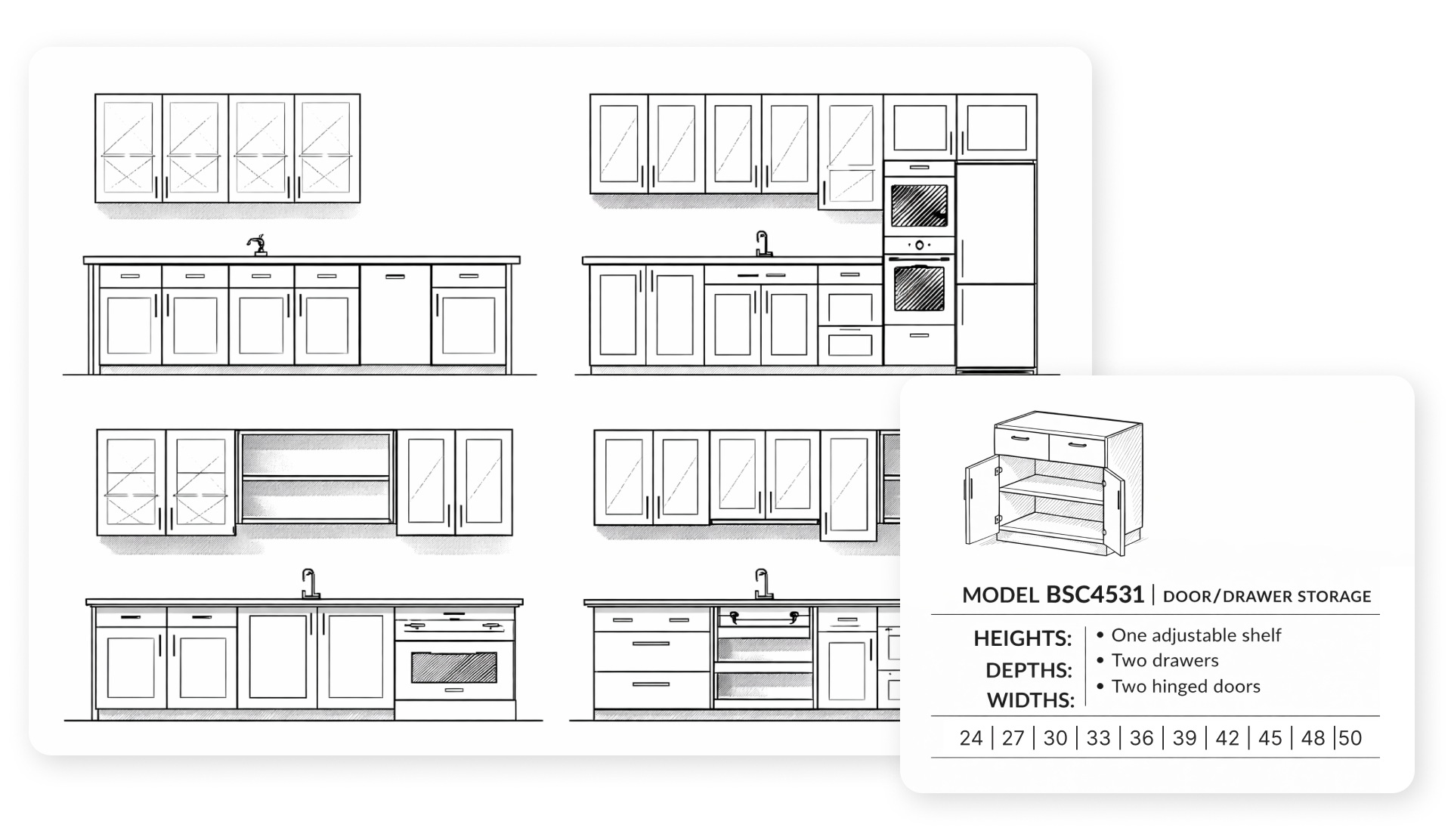
Примеры чертежа кухни: навесные шкафы сверху, напольные - снизу. И пример страницы каталога: Door/Drawer Storage с указанием доступных размеров.
Проблемы начались при масштабировании. Когда каталог вырос с 15 до 120 страниц (порядка 1500 шкафов), модель стала захлебываться объёмом информации. Кроме того, обнаружились фундаментальные несоответствия:
- Несовпадение модальностей: каталог представлен в 3D рендерах, а чертежи в 2D формате. Визуально это совершенно разные представления одного и того же объекта, и модель не всегда находит соответствие между ними.
- Специфика типов шкафов: у каждого типа (выдвижной, навесной, умывальник, полочный) свои особые признаки и правила подбора. Одному промпту невозможно передать все тонкости, и модель не способна удержать эти правила в контексте.
- Ошибки подсчёта: модель систематически ошибалась в подсчёте количества шкафов на плане и галлюцинировала размерности, а это критически важные параметры для подбора.
Следующим шагом было найти лучшую модель, и мы протестировали три ведущие модели на выборке из 20 планов с полным каталогом (120 страниц):
| Модель | Точность | Сильные стороны | Слабые стороны |
| Gemini 2.5 Pro | 34% | Лучше других в анализе изображений | Сбивается в подсчёте, галлюцинирует размеры |
| GPT-5 | 8% | Точнее считает количество шкафов | Не может подобрать по каталогу, отвечает случайно |
| Grok 4 (xAI) | 17% | Среднее между Gemini и GPT | Уступает Gemini в глубине анализа |
Результаты были неутешительными: ни одна из моделей не смогла даже приблизиться к приемлемому качеству. Стало понятно, что задача слишком многогранна для единого end to end решения на базе vLLM.
Однако, прежде чем отказаться от “наивного” подхода, мы попробовали структурировать каталог через RAG (Retrieval-Augmented Generation). Идея была в кодировке каталога таким образом, чтобы модель лучше ориентировалась в нем.
Мы протестировали несколько стратегий индексации PD-каталога, включая чанкирование по страницам и семантическое разбиение. RAG немного улучшил качество поиска по каталогу (до ~40% у Gemini), однако фундаментальные проблемы остались нерешенными: подсчёт количества шкафов, галлюцинации размеров и путаница в типах мебели.
Эти ошибки были на стороне визуального анализа. В итоге мы приняли решение: разделить задачу на специализированные подзадачи и использовать для каждой наиболее подходящий инструмент. Это стало переломным моментом проекта.
Подзадачи и финальная архитектура решения
Проанализировав ошибки и сильные стороны каждого подхода, мы декомпозировали задачу на пять последовательных этапов, каждый из которых решается наиболее подходящим инструментом:
- Этап 1. Детекция шкафов на чертеже
- Этап 2. Кластеризация шкафов
- Этап 3. Извлечение размерностей
- Этап 4. Описание признаков шкафа
- Этап 5. Семантический поиск и ранжирование по каталогу
Этап 1. Детекция шкафов
Первый и самый важный этап – точно обнаружить каждый шкаф на чертеже. Если ошибка случается здесь, она каскадом распространяется на все последующие шаги. А это очень плохо.
Для обучения мы разметили более 5000 оригинальных планов, выделив определенные классы шкафов, благодаря, которым можно будем в будущем отдельно рекомендовать позиции из каталога. Итоговая точность детектора на тестовом датасете составила 96% (mAP@0.5). Это достаточно высокий результат для архитектурных чертежей, учитывая разнообразие стилей.
Самая нетривиальная проблема детекции – вложенные шкафы. На чертежах одни шкафы визуально вложены в другие.
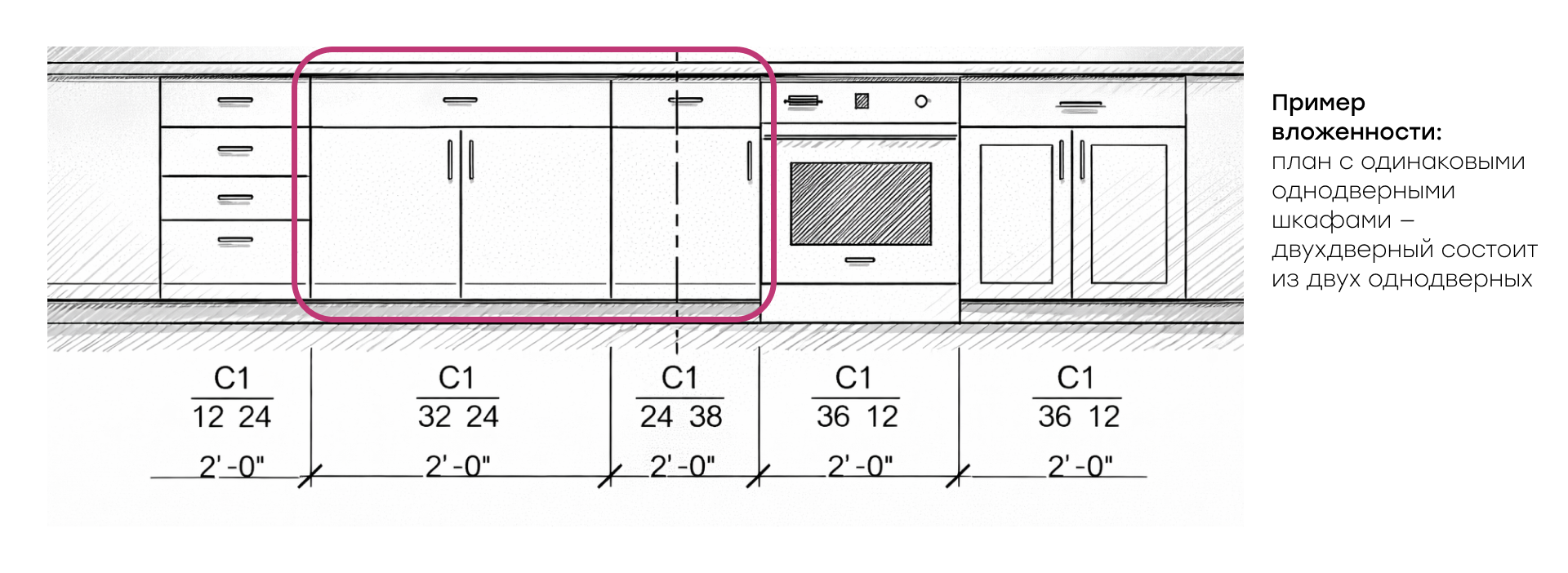
Пример плана с одинаковыми однодверными шкафами — двухдверный состоит из двух однодверных
Например, высокий однодверный шкаф может состоять из навесного шкафа сверху и нижней части, а двухдверный – это два однодверных рядом. И важно, чтобы модель это понимала как отдельный большой шкаф, а не несколько составляющих.
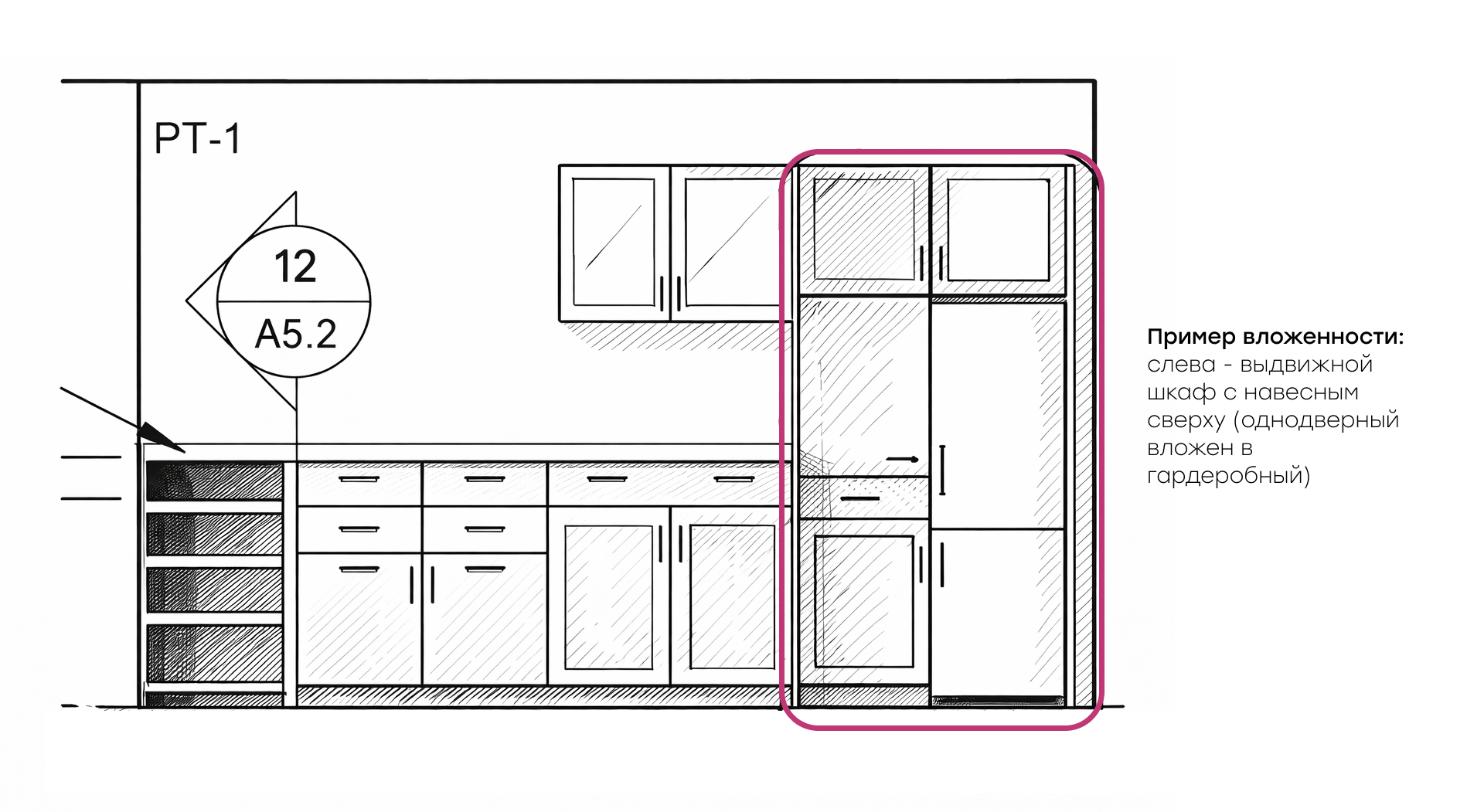
Пример вложенности: слева - выдвижной шкаф с навесным сверху (однодверный вложен в гардеробный)
Мы решили эту проблему введением правил иерархии детектируемых bbox. Алгоритм анализирует перекрытие детекций, строит иерархию типа родитель-потомок и исключает дубликаты. Например, если однодверный шкаф полностью вписан в двухдверный того же класса, то система понимает, что это агрегация из однодверных.
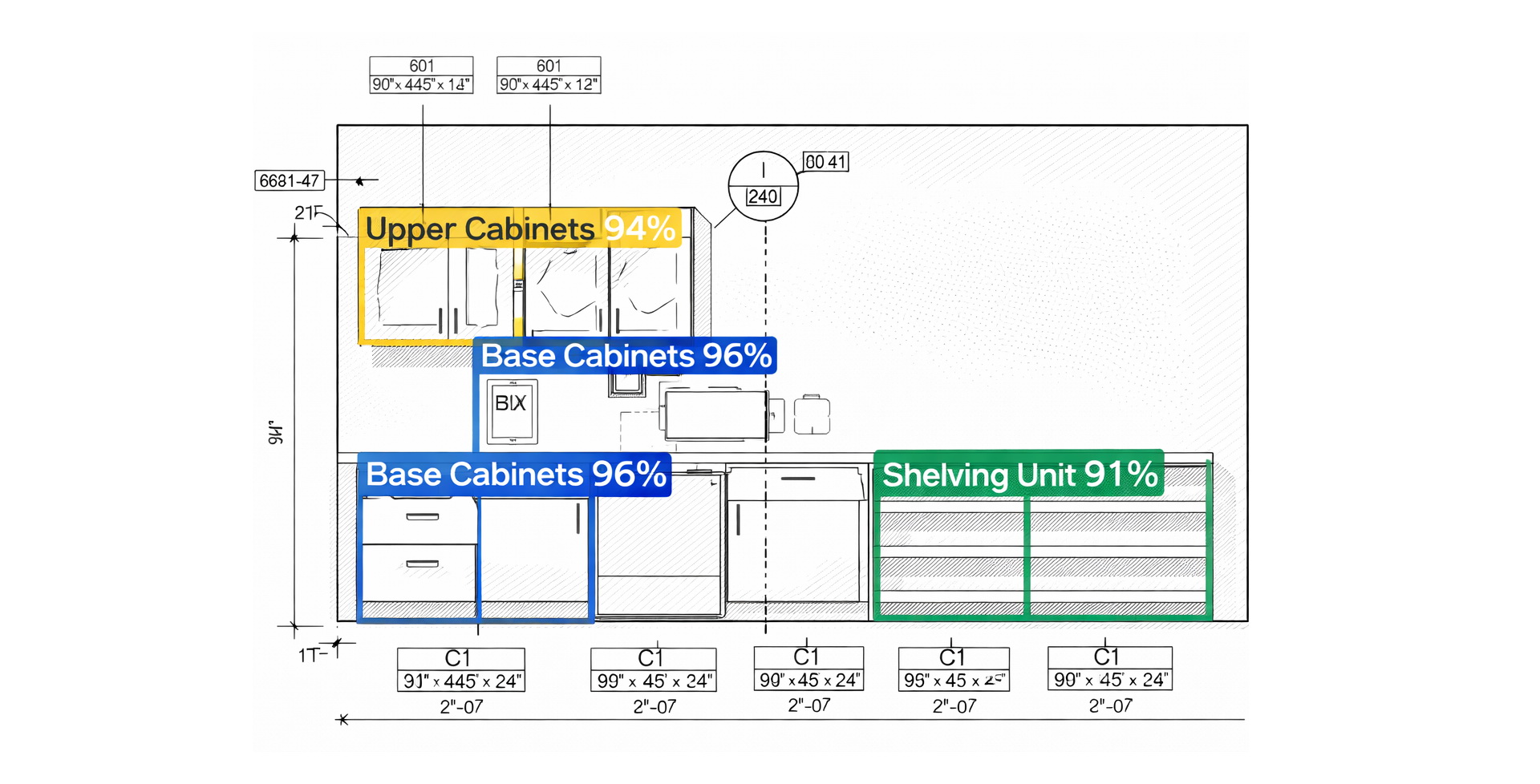
Результат работы детектора
Этап 2. Кластеризация шкафов: два режима
После детекции нужно сгруппировать визуально одинаковые шкафы. Это важный шаг и вот почему:
- Во-первых, это позволяет точно подсчитать количество одинаковых шкафов.
- Во-вторых, если два шкафа визуально идентичны, достаточно описать один и назначить общий результат подбора – это уменьшает количество работы.
Мы реализовали два подхода, выбор между которыми зависит от класса детекции:
- Алгоритм вычисляет ключевые точки для каждого шкафа, строит матрицу попарных расстояний по которым и проводит группирования классов. Такой подход хорошо работает для шкафов с явными текстурными признаками, такими как ручки, паттерны дверей.
- Алгоритм нормализует шкаф и рассчитывает попарное расстояние схожести. Такой алгоритм отлично справляется с геометрическими паттернами шкафов.
Попробуйте наше Демо!
Мы разработали сервис, в котором можно протестировать, как обученная нами AI-модель распознаёт ваши рабочие чертежи.
Этап 3. Извлечение размерностей
Размерности шкафов – один из ключевых параметров для подбора по каталогу. Но на чертежах размеры указываются разными способами: выносные линии, dimension codes (например, ZW 34|24|36, где числа кодируют Height|Depth|Width), а иногда отдельные надписи.

Поэтому вместо этого мы используем vLLM: отправляем кроп шкафа вместе с полным изображением плана, и модель должна найти этот шкаф на плане и считать его размерности.
На расширенном тестировании в 100 планов: Gemini 2.5 Pro давал точность 81%, а с выходом Gemini 3 точность выросла до 87%. Этот скачок стал важным бустом для всей системы.
Этап 4. Описание признаков шкафа и подготовка каталога
4.1 Описание признаков
Этот этап – сердце системы. От того, насколько точно описан каждый шкаф, зависит качество подбора. Мы формируем для каждого шкафа структурированный JSON с чётко определённым набором признаков, специфичных для его класса.
Каждый класс шкафов имеет свой промпт, который учитывает именно те признаки, которые релевантны для данного типа. Например, у навесного шкафа проверяется наличие остекления, а у умывальника этот признак игнорируется. Промпт содержит детальные инструкции по визуальному анализу чертежа: как отличить дверь от полки и т.п.
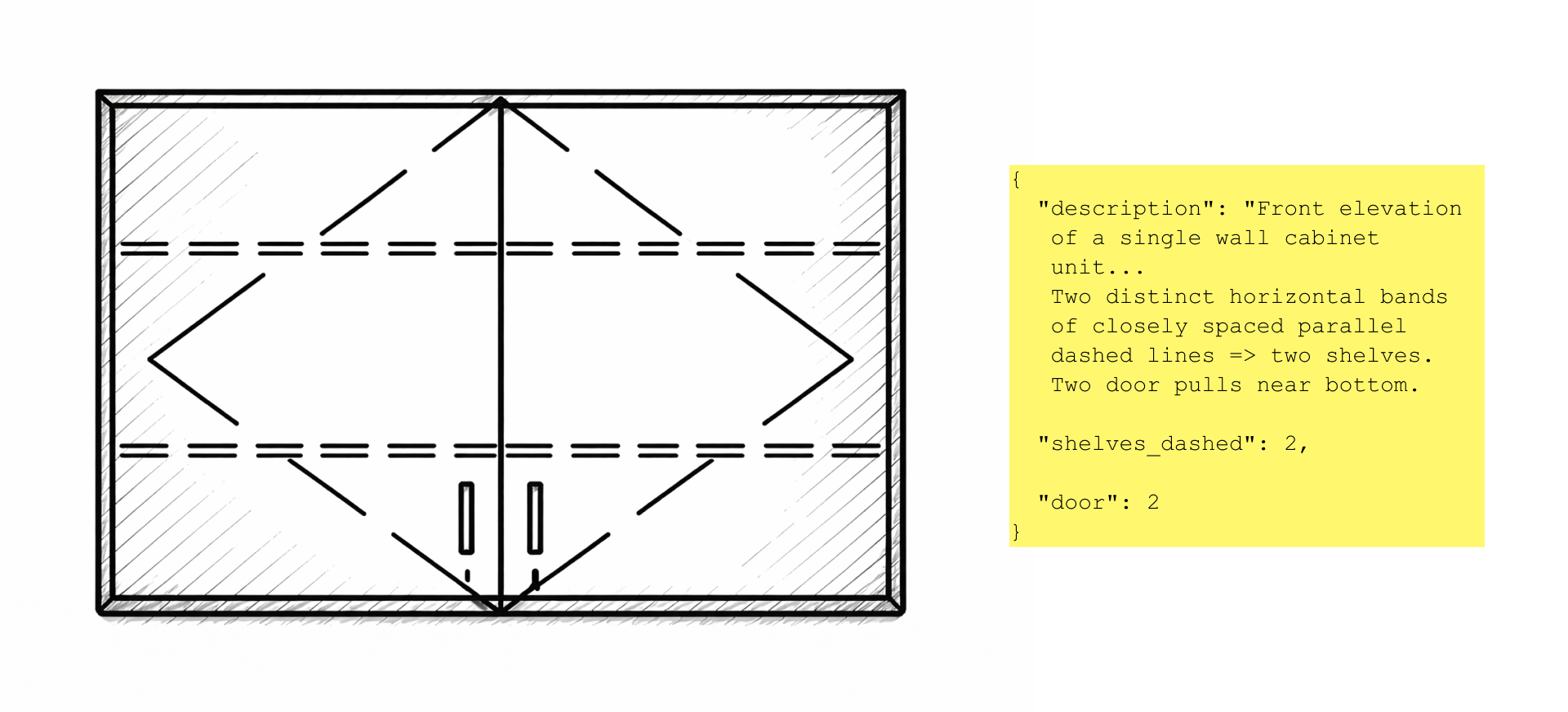
Кроп одного шкафчика из чертежа и JSON описание к нему
Мы сравнили три модели для задачи описания признаков:
| Модель | Точность рекомендации | Характерные ошибки |
| GPT-5 | 62% | Ошибки в подсчете дверей и полок, краткие описания |
| Gemini 2.5 Pro | 75% | Качественные описания, но ошибки в остеклении и полках |
| Gemini 3 | 88% | Минимум ошибок, точный подсчёт признаков |
Переход на Gemini 3 дал самый существенный прирост в качестве детекции всей системы. Модель делает точное описание, не ошибается в подсчете признаков и генерирует достаточно детальные описания для последующего семантического поиска.
4.2 Подготовка каталога
Параллельно с обработкой чертежей мы подготовили каталог мебели в машиночитаемом формате. Каждый артикул каталога описан в JSON с тем же набором признаков, что и шкафы на чертежах.
Для описания 3D рендеров каталога мы использовали GPT-5, которая генерирует полное текстовое описание каждого артикула и выделяет его признаки. Каталог хранится как набор JSON файлов, каждый из которых описывает один артикул.
Мы выбрали именно текстовые признаки, потому что при тестировании на визуальном сходстве многие шкафы схожи и отличаются только количеством полок, остеклением и т.п. и ни одна модель эмбеддер не сможет так точно отличить 2 шкафа по эмбеддингам. В текстовом же формате мы можем указать все особенности каждого шкафа.
Этап 5. Рекомендательная система
Рекомендательный блок – финальный и самый сложный этап пайплайна. Для каждого шкафа система находит топ 3 наиболее подходящих артикулов из каталога.
Процесс состоит из трёх фаз:
- Фильтрация. Для каждого класса шкафов определяется набор ограничений, специфичных для этого типа, например для навесных полок это количество выдвижных ящиков. Фильтрация реализована через три прохода с постепенным ослаблением ограничений. Это позволило нам точно найти альтернативу в каталоге, даже если не было точно подходящего шкафа
- Проверка размеров. Кандидаты, прошедшие фильтрацию, проверяются на совпадение размеров. Если ни один кандидат не прошел по размерам, используется ретрай безразмерной фильтрации.
- Ранжирование. Оставшиеся кандидаты ранжируются по композитному скору:

Формула композитного скора, где semantic – это сходство эмбеддингов описания шкафа и описания артикула каталога, lexical – лексическое совпадение описаний, size – скор близости размеров, если нет точного, w1,w2,w3 – весовые константы, которые подбираются вручную.
Результаты
Итоговая точность всей системы на расширенном тестовом наборе:
| Метрика | Значение |
| Детекция шкафов | 96% |
| Извлечение размерностей | 87% |
| Описание признаков | 88% |
| Точность рекомендации | 87% |
По сравнению с изначальным подходом, где всё делалось в LLM (максимум 34% у Gemini 2.5 Pro), финальная система даёт 87% точности – прирост более чем в 2.5 раза. При этом система обрабатывает документ за 5-7 минут, что на порядок быстрее ручной работы.
Заключение
- LLM пока не всесилен. Несмотря на впечатляющие демо компаний, мультимодальные модели пока не справляются с комплексными задачами, требующими одновременно подсчёта объектов, считывания размеров, классификации и поиска по большому каталогу. Разделение на специализированные этапы дало кратный прирост качества.
- Специфичные правила критически важны. Без специфичных фильтров и правил вложенности универсальный матчинг работал бы значительно хуже. Знание предметной области невозможно заменить одними нейросетями.
- Gemini 3 – заметный прорыв для визуальных задач. Переход с Gemini 2.5 Pro на Gemini 3 дал прирост в 6–13%на разных этапах. Качество визуального анализа архитектурных чертежей выросло существенно.
Хотите заказать решение для обработки чертежей?
Напишите нам!
И мы разработаем решение для обработки ваших чертежей!