Сравнение сервисов для анализа документов AWS Textract, Azure Document Intelligence и нашего подхода от Технологики
Бизнес все чаще и чаще предпочитают отдать искусственному интеллекту извлечение данных из документов: при таком подходе меньше ошибок и выше скорость обработки документов. И все чаще звучит вопрос — каким решением пользоваться и к какому подрядчику пойти за оказанием услуги?
Мы сделали сравнительный обзор двух популярных решений от лидеров рынка по обработке документов — AWS Textract, Microsoft Azure Document Intelligence и нашего подхода к извлечению данных из документов. Сравнивали решения по нескольким основаниям: по производительности, по результатам извлечения значений из форм, а также по стоимости.
Надеемся, что данная статья будет полезна руководителям компаний, которые уже задумались о применении ИИ для массовой обработки документов.
Хотите больше узнать про ИИ-обработку документов?
Мы умеем обрабатывать различные документы при помощи ИИ, какие, узнайте по ссылке.
Методология
В статье мы рассматриваем работу популярных западных сервисов AWS и Azure на примере англоязычного налогового документа Intuit ProSeries Tax Organizer.
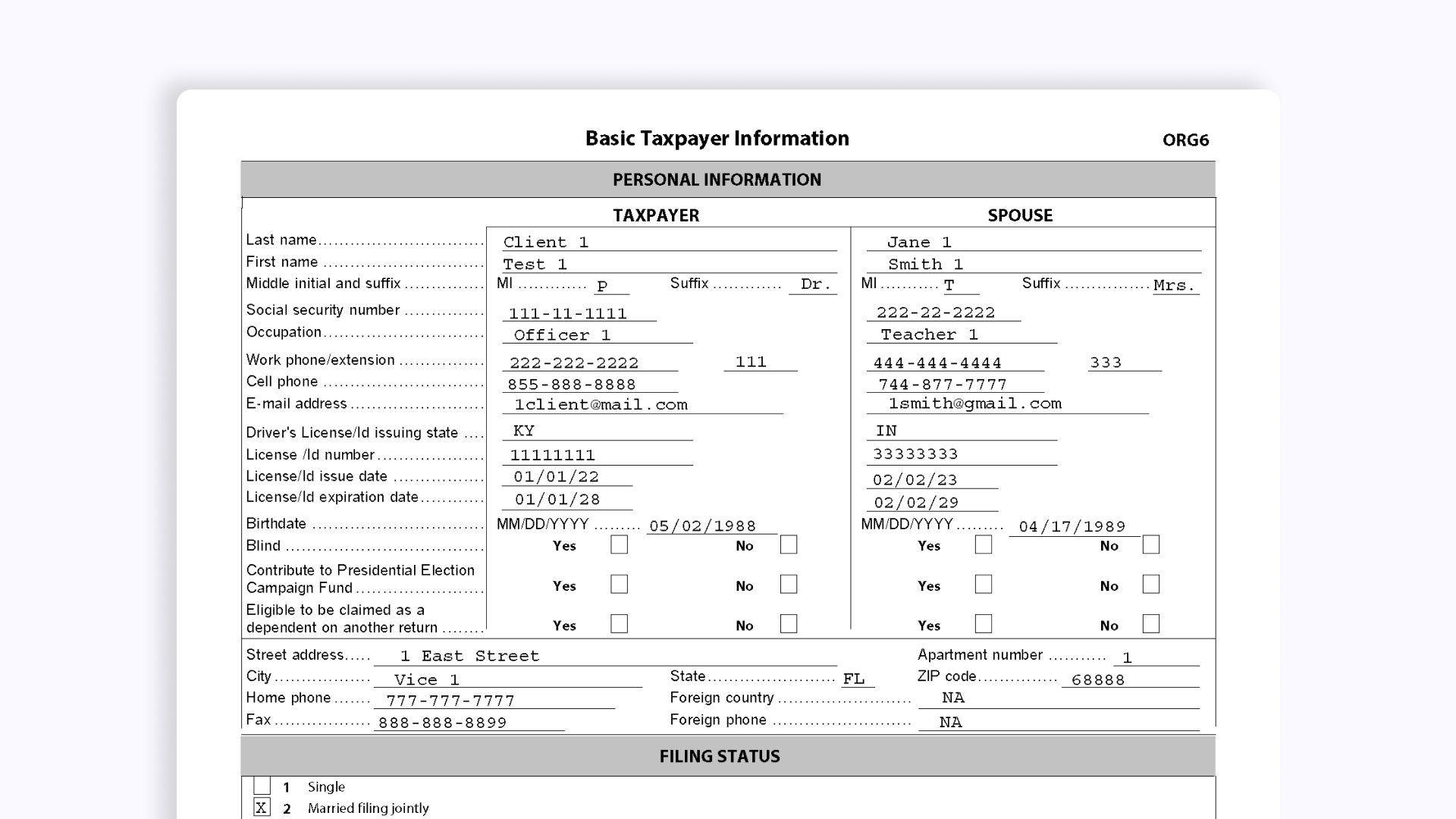
Такие документы содержат структурированные данные: внутри есть поля, ключи и связанные с ними значения. Для человека такая структура обычно понятна и читаема.
OCR-инструменты умеют извлекать текст непосредственно из изображения, благодаря чему можно получить общее представление о содержании документа. Но этого недостаточно, если дальше нужно сопоставлять ключи со значениями и выгружать данные в клиентские системы.
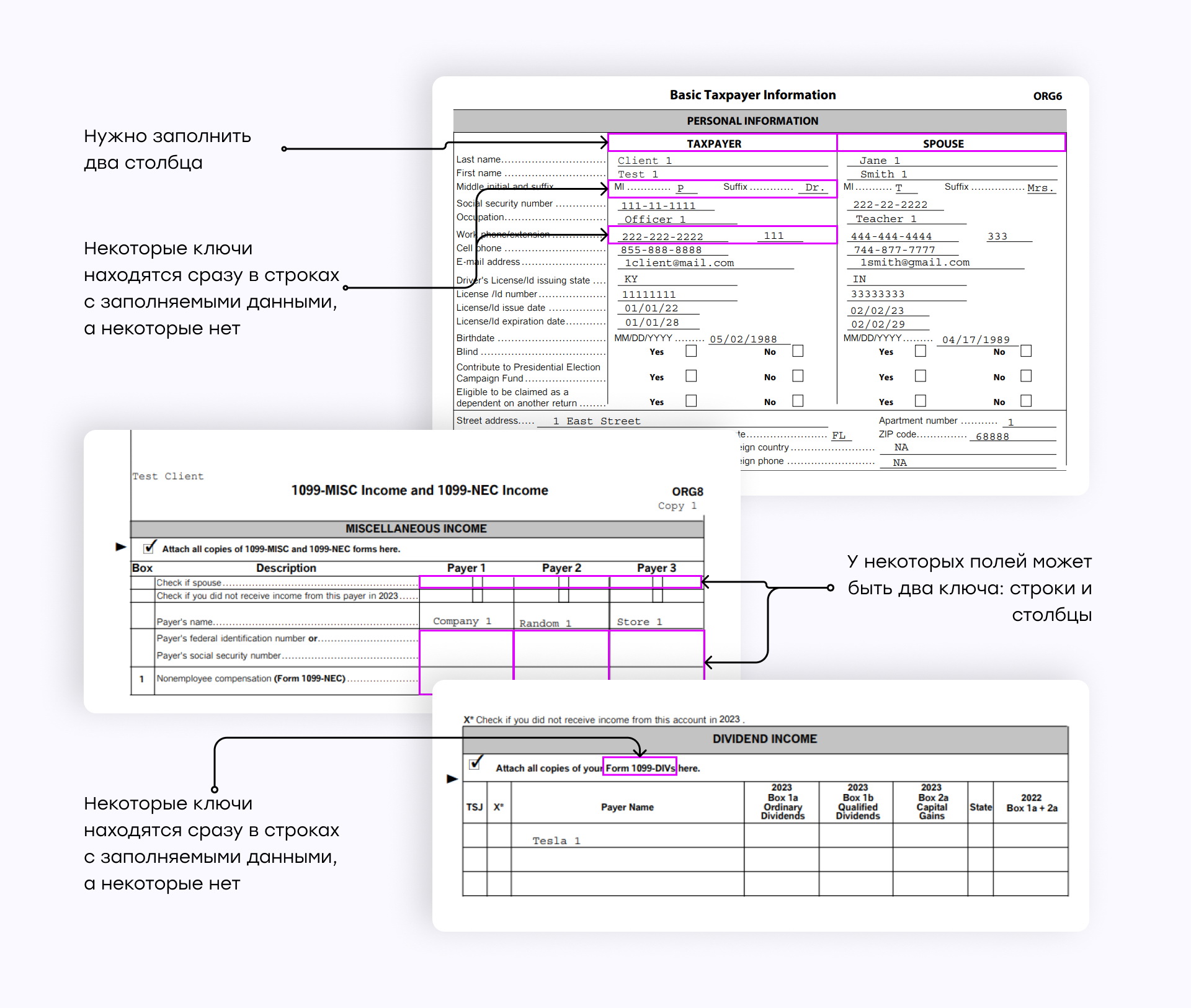
Сопоставление ключей и значений — одна из самых сложных задач. В подобных налоговых формах структура часто бывает запутанной: у части значений нет очевидных ключей, а у других одно значение может зависеть сразу от нескольких подписей из-за устройства таблиц, где смысл определяется строками, столбцами и их взаимным расположением на странице.
Такое сопоставление требует интерпретации макета страницы, пунктуации и визуальных признаков. Пары ключ-значение могут быть расположены и вертикально, и горизонтально, а сами ключи могут выделяться двоеточием, жирным шрифтом и другими способами.
Кроме того, часть PDF-документов, с которыми работает бизнес, содержит интерактивные заполняемые поля. Поэтому современный сервис извлечения данных должен уметь корректно работать и с такими документами.
Сравнение сервисов
Существует несколько OCR-решений, которые позволяют извлекать пары ключ-значение из документов. Среди них AWS Textract и Azure Document Intelligence. Это известные рыночные решения, которые часто выбирает крупный бизнес.
При этом у таких сервисов есть ограничения, поэтому мы выработали собственный подход к обработке документов, который позволяет точнее адаптировать извлечение данных под конкретные формы. Перейдем к сравнению.
AWS intelligent document processing
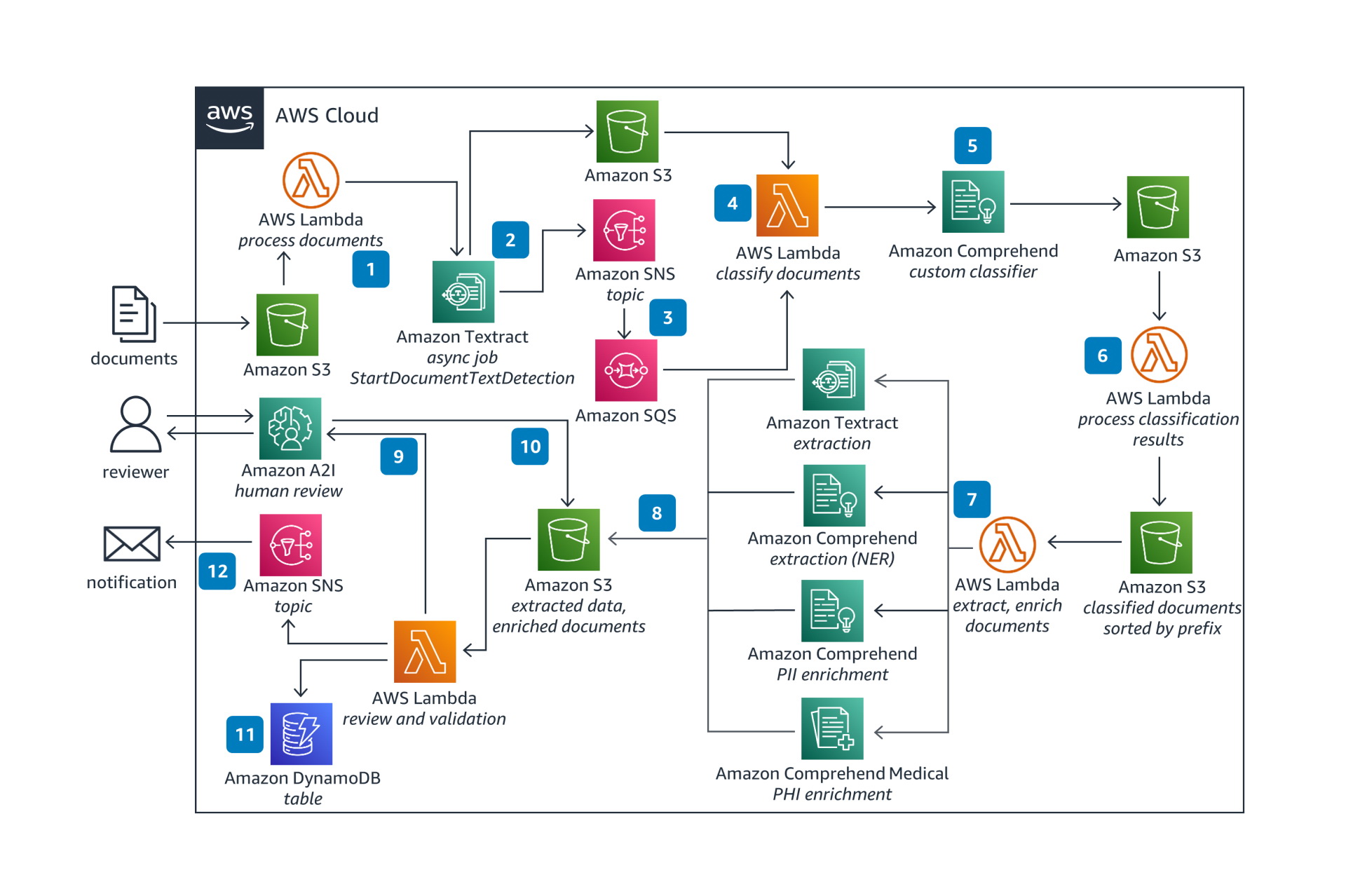
AWS Intelligent Document Processing — это набор ML-сервисов для автоматизации обработки документов.
Платформа использует OCR и NLP для чтения и интерпретации документов, а также для извлечения нужных слов, терминов и фрагментов данных.
Такой подход помогает сократить объем ручной работы и ускорить обработку документов. Среди ключевых особенностей AWS Intelligent Document Processing можно выделить следующие:
- Готовые модели: AWS предоставляет набор предобученных компонентов, включая Amazon Textract для извлечения текста и Amazon Comprehend для извлечения информации из текстов документов.
- Инфраструктурный подход: решение можно разворачивать через infrastructure as code, в том числе с использованием AWS Cloud Development Kit и низкокодовых workflow-инструментов вроде AWS Step Functions.
- Извлечение данных: платформа умеет работать с печатным текстом, рукописным вводом и данными из различных документов.
- ИИ-технологии: используются ML-инструменты AWS без обязательного привлечения собственной команды ML-специалистов.
Ключевым компонентом в контексте анализа документов здесь является Amazon Textract. При этом у Textract есть ряд ограничений:
- PDF-файлы поддерживаются только через асинхронные операции; синхронный и асинхронный режимы работают с JPEG, PNG и TIFF. Для асинхронной обработки лимиты выше: до 500 МБ и 3000 страниц для PDF и TIFF. Для синхронной обработки — до 10 МБ и 1 страницы.
- Amazon Textract поддерживает до 15 запросов на страницу в синхронном режиме и до 30 запросов на страницу в асинхронном.
- Сервис не умеет классифицировать документы по типу: паспорт, налоговая декларация, форма 1040, расписание и т. д.
- Используется стандартная модель извлечения данных, которую нельзя дообучить или адаптировать под конкретную форму.
- Сервис не извлекает данные из заполняемых интерактивных полей.
- Кириллица поддерживается слабо.
Для запуска асинхронной обработки документы необходимо предварительно загрузить в S3, так как прямая отправка в Textract невозможна. Если документы уже лежат в S3, это не создает проблем. В противном случае появляется дополнительный шаг, который может занимать заметное время.
Azure AI Document Intelligence
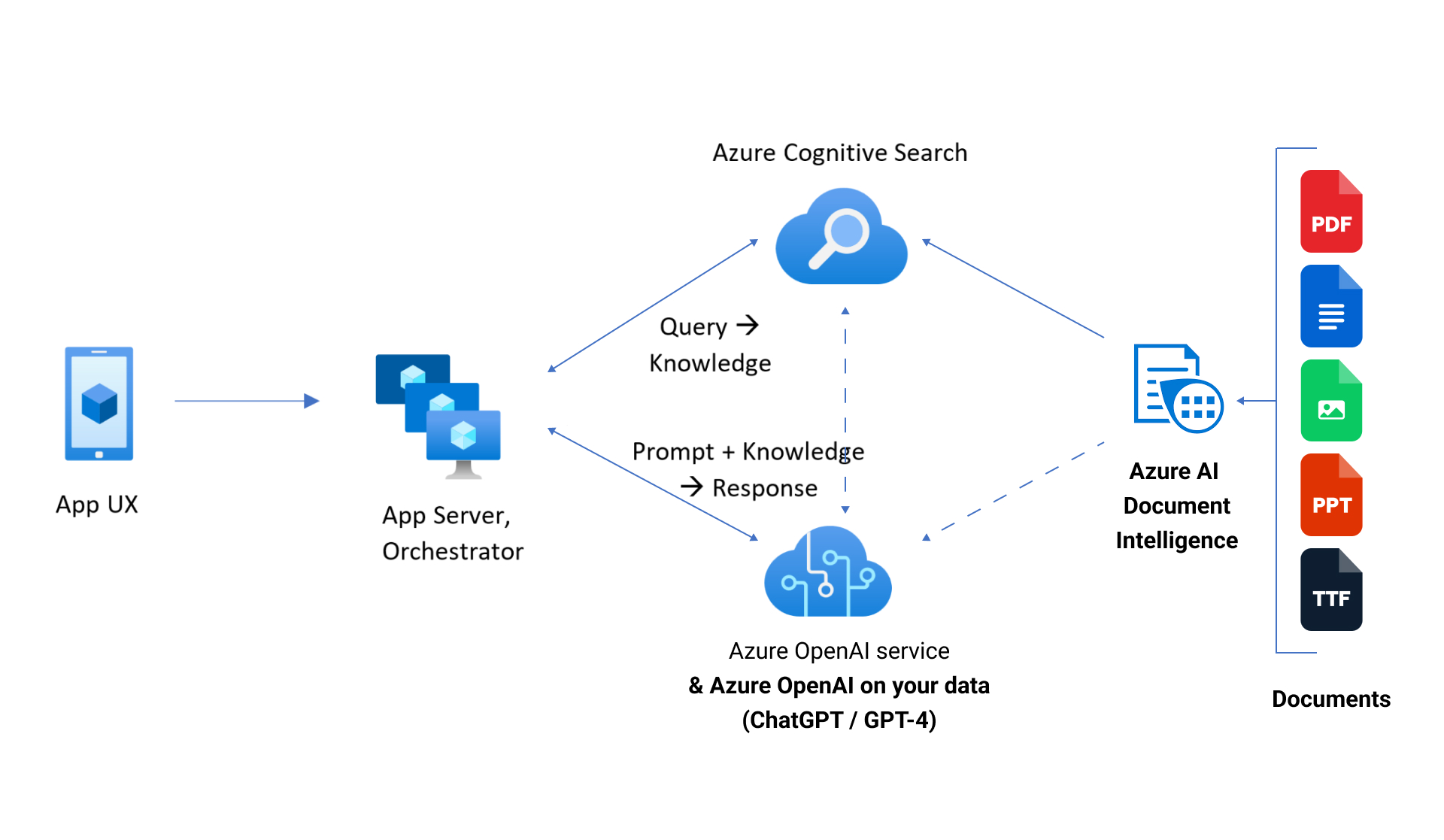
Azure AI Document Intelligence — это облачный сервис, использующий модели машинного обучения для извлечения текста, пар ключ-значение, таблиц и других структур из документов.
Платформа может использоваться для автоматизации обработки данных в приложениях и рабочих процессах, а также для задач, связанных с поиском по документам и построением data-driven процессов. Среди ее ключевых возможностей можно выделить следующие:
- Готовые модели: Azure предлагает предобученные модели, включая Read OCR для извлечения печатного и рукописного текста из PDF и сканов, а также Layout для извлечения страниц, таблиц и стилей.
- Пользовательские модели: сервис позволяет обучать собственные модели под конкретные бизнес-сценарии.
- Извлечение данных: можно извлекать текст, пары ключ-значение, таблицы и другие структуры из печатных и рукописных форм, PDF и изображений.
- ИИ-технологии: сервис использует OCR и document understanding для извлечения структурированных данных.
- Поддержка кириллицы: Azure Document Intelligence работает с кириллическими документами.
Работу можно начинать как с готовых моделей, так и с пользовательских, локально или в облаке, используя AI Document Intelligence Studio или SDK.
Чтобы добиться высокого качества извлечения данных, обычно требуется обучение собственной модели средствами Azure Document Intelligence. При этом обучение пользовательских моделей бесплатно.
У Azure AI Document Intelligence также есть ограничения:
- У Microsoft есть готовая модель для общих форм, но ее качество для документов вне списка предобученных сценариев может быть недостаточным. Если документ не относится к числу поддерживаемых типов, например не является англоязычной квитанцией, счетом, удостоверением личности или визиткой, потребуется обучение своей модели.
- Готового универсального сервиса общего назначения для извлечения пар ключ-значение нет.
- Пользовательских нейронных моделей можно обучать не более 20 в месяц.
- Для PDF и TIFF поддерживается до 2000 страниц, а на бесплатном тарифе обрабатываются только первые две страницы.
- Сервис не извлекает данные из заполняемых интерактивных полей.
Подход Технологики к обработке документов (IDP)

Наш подход к обработке и извлечению данных из документов предполагает подачу на вход PDF-документа и возврат на выходе JSON-файла с извлеченными значениями и координатами границ целевых полей в формате ключ-значение.
В основе нашего подхода лежит индивидуальная работа с каждой формой. Такой подход позволяет точно настраивать обработку сложных документов, работать с заполняемыми полями и поддерживать документы на кириллице. Это достигается за счет использования следующего технологического стека:
- OpenCV — библиотека для задач компьютерного зрения в реальном времени.
- Docotic.Pdf — SDK для работы с PDF-документами и изображениями.
- AWS Textract Detect Document Text API (опционально) — OCR-инструмент для извлечения текста. При необходимости наш подход допускает интеграцию и других инструментов. Например, если PDF не содержит текстового слоя, для распознавания символов может использоваться OCR от AWS.
Извлечение данных из форм в рамках нашего подхода происходит в несколько этапов:
- С помощью OpenCV определяются геометрические объекты страницы: вертикальные и горизонтальные линии, ячейки.
- Извлекается текст вместе с координатами ограничительных рамок при помощи Docotic.Pdf, если в документе есть текстовый слой, либо через OCR, если текстового слоя нет.
- На основе полученных данных определяется тип документа: налоговая декларация, ваучер, удостоверение личности, платежная квитанция и т. д.
- Строится карта документа, после чего извлекаются целевые поля с использованием относительных координат слов и геометрических объектов на странице или в таблицах.
Ограничения нашего подхода:
- Для каждой формы требуется разработка отдельного детектора.
- Если документ не содержит текстового слоя, необходимо использовать OCR-технологию AWS Textract или Azure Document Intelligence, а значит, появляются соответствующие квоты и ограничения.
Заинтересовал наш IDP подход?
Напишите нам, чтобы обсудить применение нашего подхода к обработке документов на ваших документах.
Сравнение производительности сервисов
Для сравнения эффективности работы всех трех сервисов был взят налоговый документ из ProSeries Tax organizer.
| Наш IDP подход | AWS Textract | Azure Document Intelligence | |
|---|---|---|---|
| Одностраничный документ | 8 секунд | 53 секунды | 13 секунд |
| Документ из 66 страниц | 18 секунд | 99 секунд | 47 секунд |
Как видно из анализа производительности, наш подход показывает самые быстрые результаты, потому что не является облачным решением.
Результаты извлечения пар ключ-значение из форм
Azure Document Intelligence
Общая модель Azure Document Intelligence пропустила большое количество пар ключ-значение и допустила много ошибок в найденных полях в разделе «Личная информация».
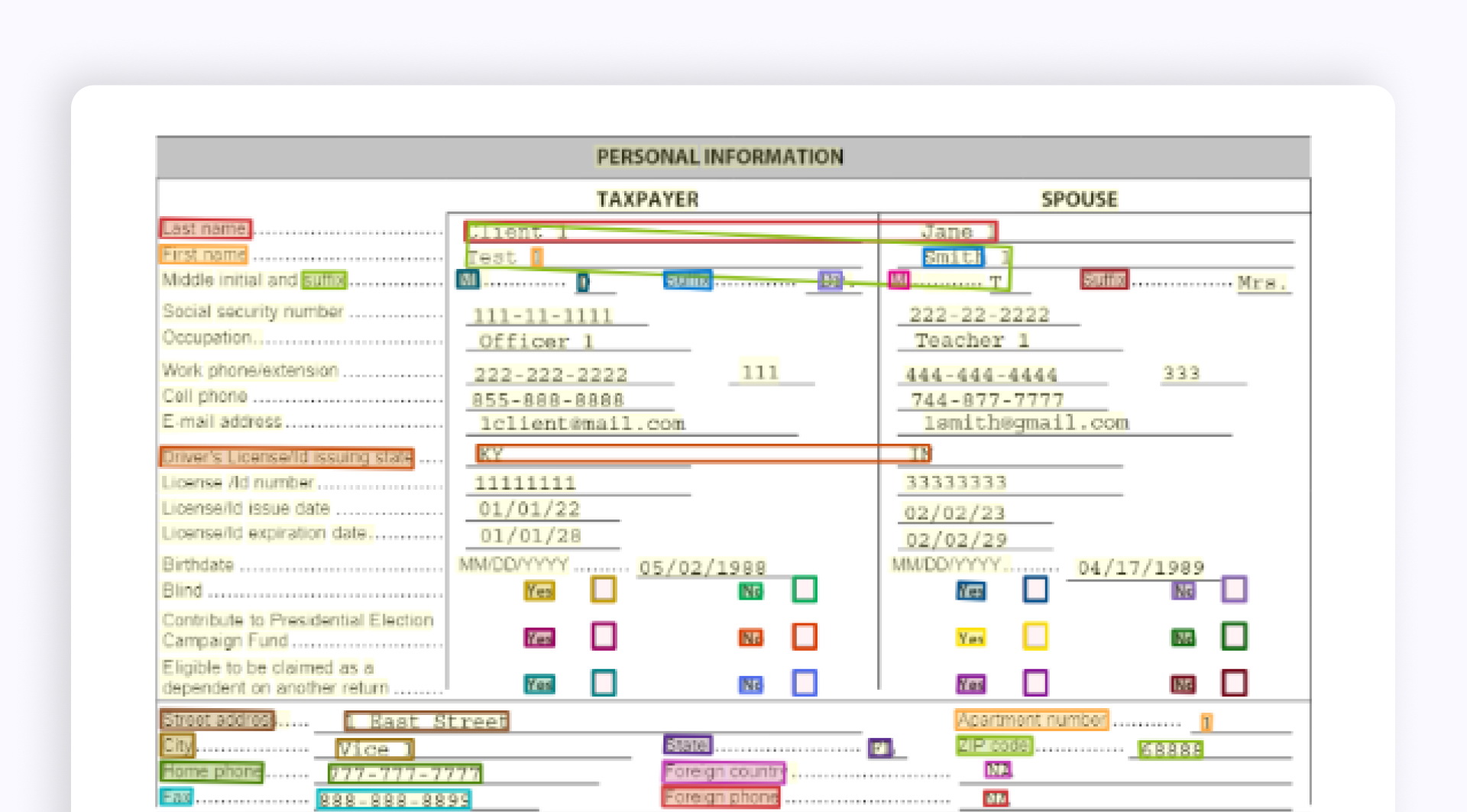
Если распознавать этот раздел как таблицу, общая модель также ошибается в структуре таблицы. В результате на разбор и дополнительную обработку такой таблицы потребуется время. При этом структура таблицы может меняться от документа к документу, поэтому адаптировать алгоритм заранее бывает трудно.
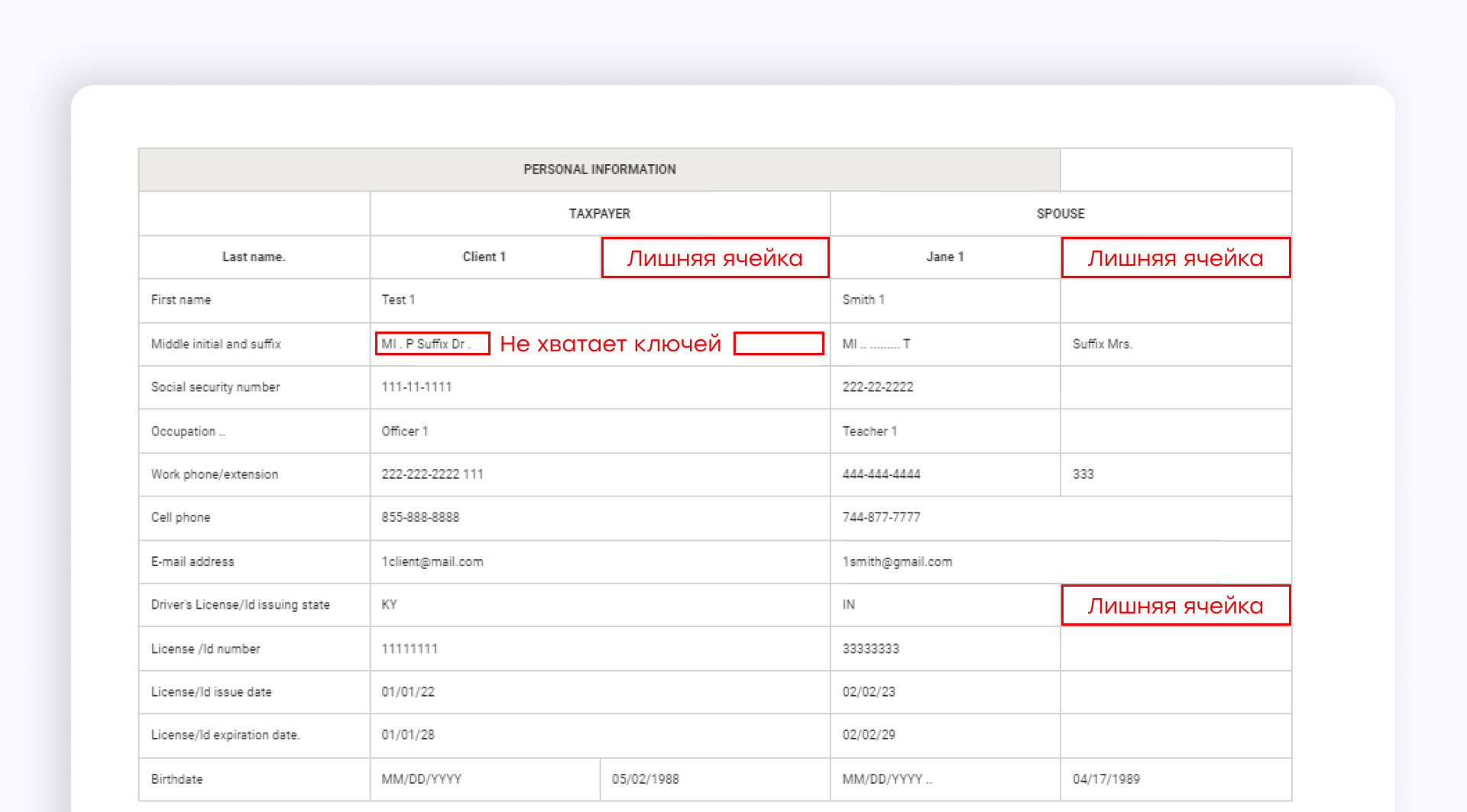
Альтернативный вариант — обучить собственную модель под конкретную форму. Azure Document Intelligence предоставляет такую возможность, и это позволяет решить описанные выше проблемы.
AWS Textract (формы + таблицы)
AWS Textract извлекает пары ключ-значение немного лучше, чем общая модель Azure, но все равно допускает много ошибок. В документе остаются пропущенные ключи и значения, особенно заметные, например, в колонке «Spouse».
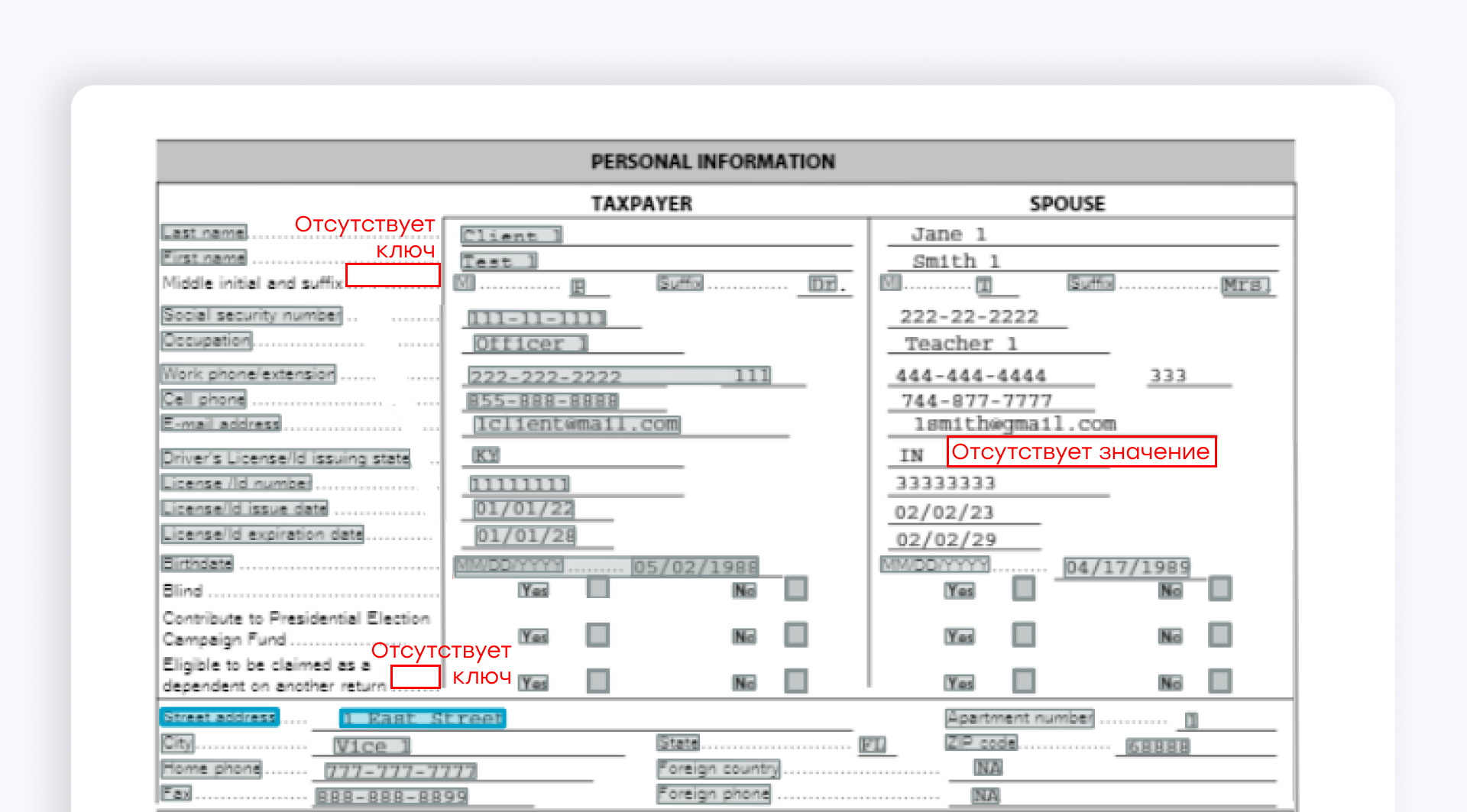
Если распознавать этот раздел как таблицу с помощью AWS Textract, часть полей с несколькими ключами или несколькими значениями объединяется в одну ячейку. Из-за этого структура документа нарушается.
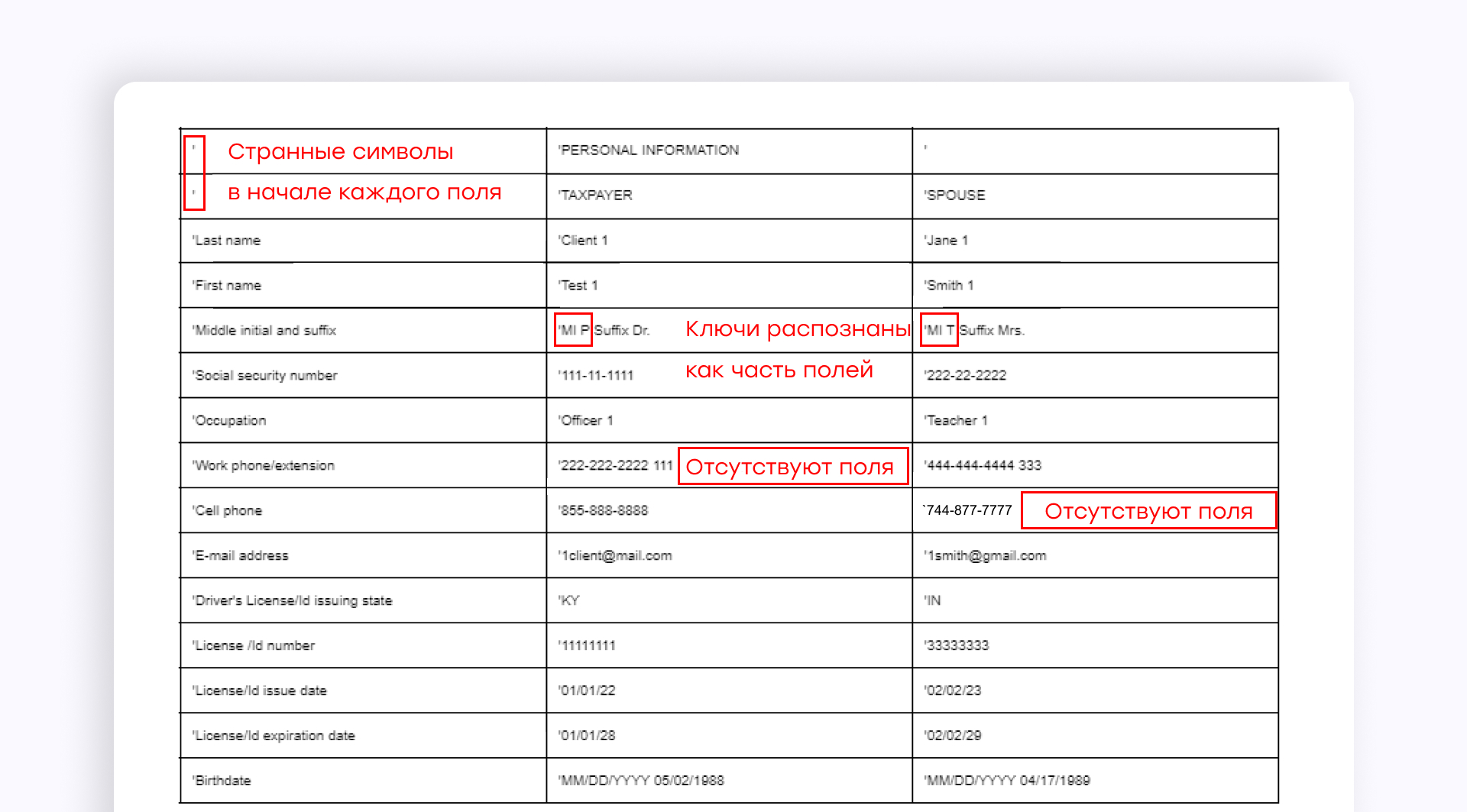
Кроме того, в отличие от Azure, AWS Textract не позволяет обучать собственную модель или настраивать существующую модель под конкретную задачу.
Наш подход
Наш подход позволяет точно настраивать детекторы для каждой отдельной формы. За счет этого результат оказывается лучше, чем у обобщенных моделей Azure и AWS.

Все ключи и значения были найдены и извлечены из описывающих их прямоугольников, что может быть полезно для дальнейшего маппинга в пользовательском интерфейсе. При этом решение этой задачи потребовало дополнительного анализа структуры документа и реализации специального детектора для данного раздела.
Цены на сервисы
Рассмотрим различные тарифные планы сервисов интеллектуальной обработки документов в зависимости от количества страниц (10 тысяч, 100 тысяч, 1 миллион).
Отметим, что любая цена не включает настройку под конкретные формы и стоимость хостинга/инфраструктуры. Общая стоимость зависит от количества форм, нагрузки, пиковой нагрузки, развертывания облака/внутренней инфраструктуры и т. д.
| Цена указана за 1 тыс. стр. | Тарифный план 1: Обработка 10 тысяч страниц | Тарифный план 2: Обработка 100 тысяч страниц | Тарифный план 3: Обработка более 1 млн. страниц |
|---|---|---|---|
| Наш подход (Single Server or Single Application) | $99.50 | $9.95 | $0.99 или меньше |
| Наш подход (Single Server or Single Application + OCR) | $101.00 | $11.45 | $2.49-$1.50 / $1.49-$0.50* |
| Наш подход (Scalable solution) | $329.50 | $32.95 | $3.29 или меньше |
| Наш подход (Scalable solution + OCR) | $331.00 | $34.45 | $4.79-$1.50 / $3.79-$0.50* |
| AWS Textract | $65.00 | $65.00 | $65.00 / $50.00* |
| Azure Document Intelligence | $50.00 | $50.00 | $50.00 |
* Более 1 миллиона страниц в месяц.
Выводы
Облачные сервисы с готовыми решениями для интеллектуальной обработки документов остаются сравнительно дорогими: порядка 5–6,5 цента за страницу. Из-за этого внедрение ИИ-обработки документов не всегда оказывается экономически оправданным. Кроме того, для использования таких сервисов требуется возможность оплачивать зарубежные решения.
При этом облачные платформы предоставляют качественные и относительно недорогие OCR-инструменты для извлечения неструктурированного текста. Но они по-прежнему не умеют извлекать данные из интерактивных документов с заполняемыми полями, хотя именно такие документы часто встречаются в судебной, налоговой и бухгалтерской практике.
Дополнительную проблему представляют документы на кириллице. Если Azure Document Intelligence еще в определенной степени поддерживает кириллицу, то AWS Textract справляется с ней значительно хуже.
Azure Document Intelligence показывает быстрый отклик на одностраничных документах и хорошо масштабируется при увеличении количества страниц. Однако использование общей модели продемонстрировало низкое качество извлечения пар ключ-значение и таблиц.
При этом у Azure есть возможность обучить собственную модель под конкретную форму, и в ряде случаев она работает хорошо. Но у этого подхода есть ограничения по количеству моделей и обучающих примеров. Также существуют предобученные модели для ограниченного числа распространенных форм.
AWS Textract демонстрирует довольно медленный асинхронный отклик, что ставит под сомнение его применение в сценариях обработки документов в реальном времени. Кроме того, точность разбора форм в некоторых разделах анализируемого налогового документа оказалась низкой. В AWS Textract нет возможности обучить пользовательскую модель или существенно улучшить общую модель под конкретную форму.
Наш подход работает быстро и подходит для обработки как одностраничных, так и многостраничных документов в режиме реального времени. Качество извлечения пар ключ-значение и таблиц получается высоким, но требует индивидуальной настройки под каждую конкретную форму.
Стоимость распознавания одной страницы при таком подходе заметно ниже по сравнению с облачными сервисами. Кроме того, он позволяет работать с интерактивными документами с заполняемыми полями и хорошо обрабатывает кириллические тексты. Однако если исходный документ не содержит текстового слоя, для такого сценария необходимо подключать качественный OCR, например AWS Textract OCR или Azure Document Intelligence Read.