Умный поиск по базе знаний компании на основе ИИ

Бизнес-логика
Заказчик - крупная организация с внутренней базой знаний по множеству проектов компании - внутренним и клиентским. Википедия или база знаний помогает сотрудникам быть в курсе решений и изменений на проектах, помогает делиться опытом друг с другом, потому что не всегда есть возможность очных встреч и созвонов с коллегами из разных проектов, более того, не всегда есть осведомленность о применяемом на проектах опыте.
Локальная википедия ведётся во многих компаниях. Но этот способ обмена информацией эффективен только тогда, когда имеет хороший поиск по тексту, тегам, грамотно составленная структура, когда сотрудникам удобно пользоваться базой знаний.
Именно за умным поиском на основе современных языковых моделей к нам и обратился заказчик. База знаний у клиента уже существует, ей пользуются сотрудники, но всегда можно сократить трудозатраты на более эффективные поиски информации.
Хотите внедрить в своей компании ии-поиск?
Напишите нам, чтобы начать трансформацию вашего бизнеса.
Решение
Внутренняя википедия заказчика содержит очень много информации, которая находится под NDA, частью данных можно пользоваться только внутри определенных отделов компании, и некоторый объем — на всю компанию.
Также она содержит специфичные вещи, о которых не имеет смысла рассказывать внешним языковым моделям, вроде ChatGPT, поскольку эта специфичная информация потом будет использоваться для ответов другим пользователям в сети.
Поэтому использование языковой модели, где данные отправляются во внешний сервис, например ChatGPT, в данном случае не подходит. Служба безопасности заказчика против такого решения, а также неэтично обучать LLM на такой специфической информации.
Наше решение состояло из трёх частей:
- Организация поиска по данным
- Обучение локальной языковой модели
- Внедрение моделей ИИ в инфраструктуру компании
Организация поиска по данным
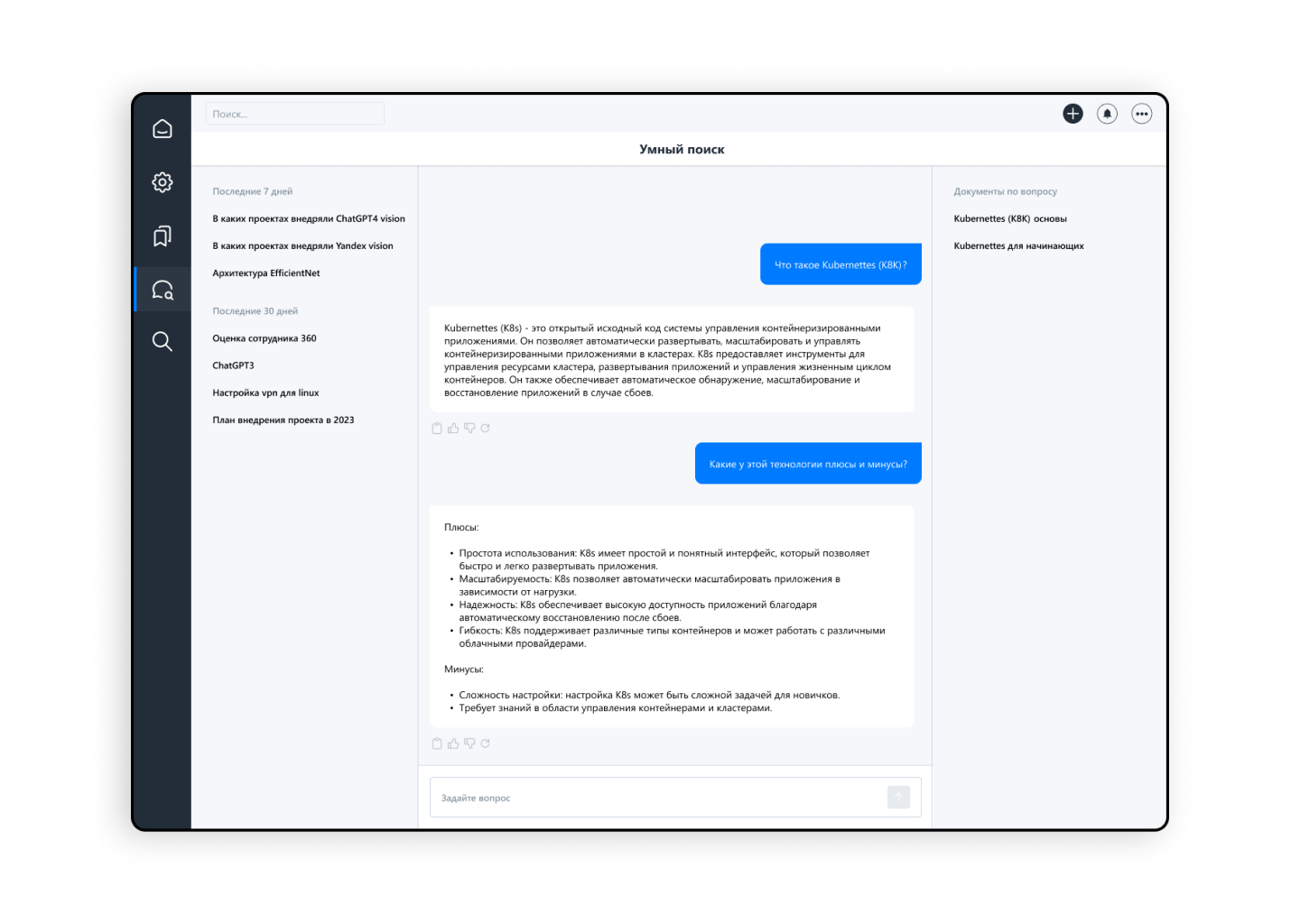
Для того, чтобы найти текст в википедии, по ней надо организовать эффективный поиск. Модель должна уметь искать куски текста, в которых возможно содержится ответ на вопрос, который задает пользователь.
Мы использовали две модели: retriever, который делал семантический поиск, и reranker, который ранжировал найденные куски текста по качеству.
Ввиду этических и правовых моментов, мы не могли использовать ChatGPT - самую популярную и эффективную на данный момент языковую модель. Но на рынке уже существует множество более маленьких и более дешевых языковых моделей или моделей с открытым кодом, которые при должной настройке могут давать ответы не хуже чем ChatGPT.
Выбранная нами языковая модель LLama2 читает вопрос и найденные тексты из Википедии, сличает эти тексты между собой и выбирает самый подходящий. Иногда вопросы требуют объединения нескольких текстов для ответа. Это тоже под силу нашей языковой модели.
Результаты
Заказчик получил более эффективный поиск по базе знаний, сократив время обращения к информации у своих сотрудников на 30-35%. А сотрудники получили более углубленную экспертизу по проектам компании, поскольку теперь имеют доступ к данным, к которым ранее у них не было доступа, ведь локальная языковая модель обучается на всех данных заказчика.
В планах у заказчика организовать работу со своей базой знаний через интеллектуального помощника (чат-бота). Общение с базой знаний в формате мессенджера будет более привычным современному пользователю, привыкшему к общению с такими ботами у популярных сервисов.
Также будет организовано логирование запросов пользователей и можно будет анализировать актуальные потребности сотрудников, а значит, оптимизировать базу знаний.
Попробуйте наше Демо!
Чтобы показать, как RAG выглядит не в теории, а в реальных условиях, мы подготовили интерактивную демонстрацию работы RAG с корпоративными документами.