ИИ для подбора мебели по архитектурным чертежам и каталогам

Бизнес-логика
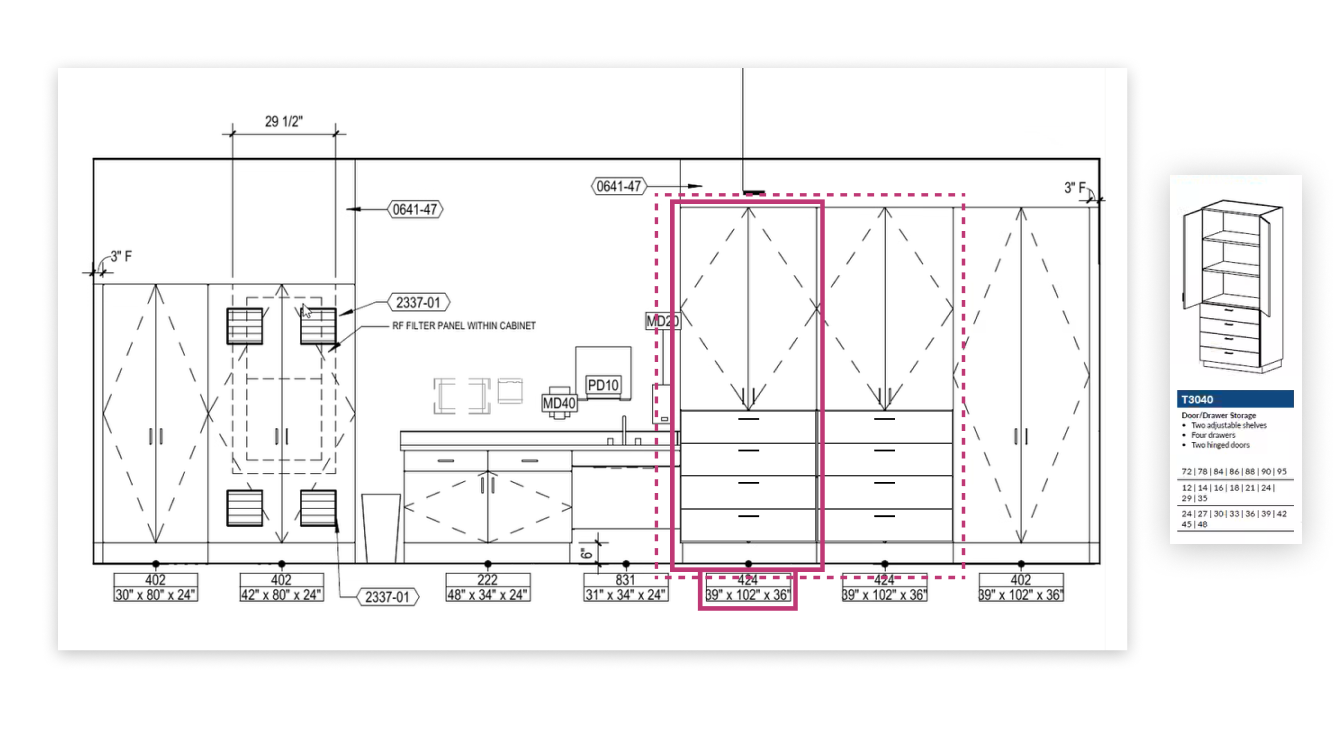
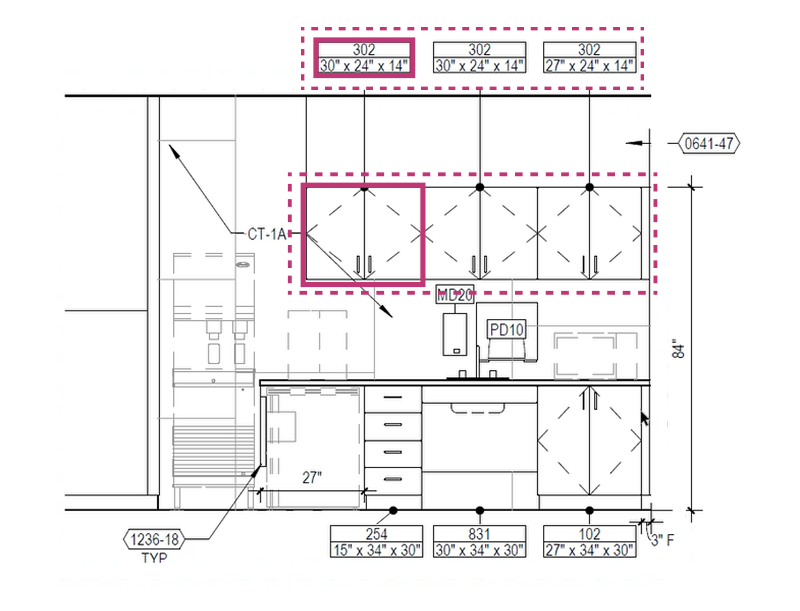
Клиент — поставщик мебели для строительных проектов. В рамках тендеров и конкурсов он получает архитектурные чертежи, где указаны помещения и размещение мебели, например, шкафов, стеллажей и других элементов. Это 2D схематичные чертежи.
Чтобы подать коммерческое предложение, необходимо:
- проанализировать чертежи,
- определить, какая мебель требуется,
- подобрать подходящие позиции из каталога,
- сформировать смету.
Ранее этот процесс выполнялся вручную: специалисты изучали чертежи, извлекали размеры и параметры мебели, а затем сопоставляли их с каталогом. Это занимало значительное время и замедляло участие в тендерах.
Задача проекта — автоматизировать этот процесс с помощью ИИ: от разбора чертежа до подбора мебели из каталога.
Хотите заказать решение для обработки чертежей?
Напишите нам!
И мы разработаем решение для обработки ваших чертежей!
Решение
Система обнаруживает мебель на чертеже и извлекает параметры объектов. Для этого используются модели компьютерного зрения и OCR, после чего LLM формирует формализованное описание каждого шкафа, включая размеры и конфигурацию (количество дверей, полок, ручек и других элементов).
Далее объекты группируются по типам с помощью кластеризации: для каждого найденного шкафа вычисляются embedding-векторы изображения, и близкие по структуре объекты объединяются в один тип мебели с вариациями размеров.
Весь каталог поставщика был преобразован в структурированный JSON-формат. Для каждой позиции каталога была сформирована текстовая конфигурация мебели (количество дверей, полок, секций и т.д.).
После этого подбор выполняется через комбинированное сравнение — семантическое сопоставление текстовых описаний и анализ визуального сходства объектов.
Архитектура решения
Система объединяет обработку изображений, текстовый анализ и семантическое сопоставление для автоматизации подбора мебели по архитектурным чертежам.
Анализ архитектурных чертежей
- Детекция объектов мебели на изображении с помощью YOLO
- Извлечение текстовых данных (размеров, подписей) через PaddleOCR
- Дополнительная интерпретация с помощью LLM (Gemini)
На выходе формируется структурированное описание мебели в фиксированном формате (JSON), включая тип объекта, размеры и конфигурацию (количество дверей, полок и т.д.).
Кластеризация объектов
- Группировка мебели по типам с помощью Agglomerative Clustering
- Использование эмбеддингов изображений
Это позволяет объединять схожие объекты в группы и подбирать один тип мебели с вариациями вместо обработки каждой позиции отдельно.
Подготовка каталога
Изначально каталог представлял собой PDF с 3D-визуализациями без структурированных описаний.
- Каталог преобразован в структурированный JSON
- Для каждой позиции сформировано текстовое описание конфигурации (двери, полки, штанги и т.д.)

Сопоставление объектов мебели
- Семантическое сравнение текстов (эмбеддинги)
- Лексическое сравнение (N-grams)
- Дополнительно — сравнение изображений (на ранних этапах)
Сопоставление выполняется на основе комбинированного анализа текстовых и визуальных признаков, что повышает точность подбора мебели из каталога.
Челленджи в разработке и их решения
Неточное извлечение параметров с чертежей
На первых этапах система некорректно определяла размеры и конфигурации мебели: LLM путалась в обозначениях, не всегда правильно интерпретировала, какие именно параметры важны (например, количество дверей или секций). Это напрямую влияло на качество дальнейшего подбора.
Чтобы решить проблему, команда переработала промпты и перешла на более точную модель от Gemini, а также ввела фиксированный формат описания объектов. Это позволило стандартизировать извлекаемые данные и снизить количество ошибок.
Сложность сопоставления с каталогом
Изначально каталог представлял собой большой PDF на более чем 300 страниц с 3D-визуализациями и минимальным текстовым описанием. LLM не справлялась с задачей прямого поиска подходящих позиций: слишком много пересечений было у объектов.
Мы приняли решение полностью преобразовать каталог в структурированный JSON. Для каждой позиции вручную сформировали описание конфигурации (двери, полки, штанги и другие параметры), что позволило перейти от неструктурированного поиска к более точному сопоставлению по признакам.
Большое количество похожих объектов на чертеже
На одном плане может быть много одинаковых или почти одинаковых шкафов, и обрабатывать их по отдельности неэффективно – это увеличивает время и создает дублирование при подборе.
Для решения задачи внедрили кластеризацию: объекты группируются по визуальному сходству с использованием эмбеддингов. В итоге система определяет группы одинаковых шкафов и подбирает для них один тип мебели с вариациями.
Неоднородность данных: текст + графика
Ключевая сложность проекта – необходимость одновременно работать с графическими чертежами и текстовыми данными, которые часто неполные или неоднозначные. Часть информации присутствует только в виде изображений, а часть – в виде подписей.
Это потребовало комбинирования нескольких подходов: CV-моделей для детекции объектов, OCR для извлечения текста и LLM для интерпретации. Дополнительно задачу разбили на этапы, чтобы последовательно обрабатывать и уточнять данные.
Ограничения LLM при работе со сложными объектами
При попытке "в лоб" сопоставлять объекты с каталогом через LLM модель часто ошибалась — особенно в случаях с похожими конфигурациями или нестандартными решениями.
В итоге подход был пересмотрен: вместо полного доверия LLM мы внедрили гибридную схему, где используется комбинация семантического (эмбеддинги) и лексического (N-grams) сравнения. Это позволило сделать процесс подбора более устойчивым и контролируемым.
Результаты
Мы разработали прототип системы автоматического подбора мебели по архитектурным чертежам.
Автоматизированы ключевые этапы:
- извлечение объектов с чертежей,
- структурирование спецификаций,
- сопоставление с каталогом.
Реализован переход от неструктурированного PDF-каталога к формализованной базе данных. Уже на уровне прототипа существенно ускорен процесс подготовки смет. Далее мы будем работать над автоматическим формированием смет.
Проект находится в стадии активной оптимизации: основное внимание уделяется повышению точности сопоставления и улучшению качества извлечения параметров.
Попробуйте наше Демо!
Мы разработали сервис, в котором можно протестировать, как обученная нами AI-модель распознаёт ваши рабочие чертежи.