ИИ для оцифровки и парсинга медицинских анкет пациентов

Бизнес-логика
Клиенту требовалось автоматизировать обработку бумажных анкет пациентов, которые заполняются вручную перед визитом к врачу, а также заполняют сами врачи на приёме. Эти анкеты содержат информацию о симптомах, состоянии пациента и используются врачами для первичной диагностики и принятия решений о дальнейшем лечении. А также для отслеживания динамики пациента.
До внедрения решения все данные обрабатывались вручную: после приема анкеты сканировались и хранились в виде PDF-файлов без возможности быстрого поиска по ответам и фильтрации.
Задача проекта – преобразовать рукописные и печатные формы в структурированный цифровой формат, чтобы врачи могли быстро находить и анализировать информацию по пациентам.
Обдумываете IDP решение?
Мы создаем индивидуальные системы по обработке документов при помощи искусственного интеллекта.
Челленджи и ограничения проекта
Неструктурированные и постоянно меняющиеся формы
Изначально предполагалось, что будет около 5 различных типов форм, однако на практике клиент предоставил более 40 различных шаблонов.А также в процессе работы над проектом добавлялись новые формы. Они отличались по структуре и логике заполнения.
Это делало невозможным масштабирование через обучение отдельной модели Azure Document Intelligence под каждую форму.
Сложные сценарии заполнения
В анкетах использовались:
- чекбоксы
- текстовые ответы
- комбинированные поля (true/false + комментарии к ним)
Дополнительно врачи иногда отмечали ответы нестандартным способом, например, проводили вертикальную линию через несколько вариантов, что не распознается классическими OCR-инструментами как отдельные ответы.
Рукописный текст и его вариативность
Несмотря на хорошее качество распознавания, почерк пациентов и врачей (особенно при наличии тремора у пациента) приводил к ошибкам в интерпретации данных.
Ограничения стандартных OCR-решений
Базовые возможности OCR не справлялись с:
- объединенными ячейками таблиц
- сложной логикой чекбоксов
- сопоставлением вопросов и ответов, а также с комментариями к ответам (некоторые формы содержали и такой функционал)
Требование к контролю качества данных
Клиенту было важно не только извлекать данные, но и понимать уровень уверенности системы, чтобы вручную проверять потенциальные ошибки.
Решение
Мы реализовали гибридный AI-пайплайн для обработки документов, который сочетает OCR, CV и LLM.
1. Предобработка и стандартизация форм
На старте проекта команда переработала формы, чтобы они были максимально структурированы и формализованы, потому что изначально было очень много форм с полями для больших блоков рукописных ответов пациентов, а вопросы с вариантами ответов обводились в кружочек, что было крайне сложно распарсить.
Что было сделано:
- привели формы к табличному виду
- унифицировали структуру
- заменили текстовые варианты ответов на чекбоксы
Это позволило значительно повысить качество дальнейшего распознавания.

2. Классификация документов
Система автоматически определяет тип формы с помощью классификатора на базе Azure Document Intelligence и направляет документ в соответствующий сценарий обработки.
Мы обучили классификатор: подготовили обучающую выборку, натренировали модель, и теперь она знает, где в документе какая форма. Это позволило нам в большом отсканированном документе на нескольких пациентов с множеством форм, определить отдельные формы и анкеты, и далее уже отдельные формы подавать в пайплайн.
Хотите заказать решение для медицинских документов?
Напишите нам! И мы разработаем решение для обработки ваших медицинских документов!
3. Извлечение данных и гибридный подход
Мы применяем Azure Document Intelligence для:
- распознавания печатного текста
- распознавания рукописного текста
- получения координат элементов и confidence score для каждого поля
На старте проекта этот подход давал точность около 65-70%. Это крайне низкая точность, поэтому мы стали применять гибридный подход – после первичного извлечения данные передаются в LLM Gemini, которая:
- корректирует ошибки OCR
- интерпретирует сложные ответы
- сопоставляет вопросы и выделенные чекбоксы с соответствующими ответами
Применение такого подхода увеличило показатели качества до 95% на простых анкетах и 90% на сложных многостраничных анкетах.

Детекция нестандартных чекбоксов
Для случаев с “вертикальными линиями” была внедрена CV-модель (YOLO), которая:
- находит линии на изображении
- определяет пересечения с ячейками
- корректно восстанавливает ответы на основе координат, которые подготовил Azure Document Intelligence

4. Постобработка и формирование результата
Система формирует итоговый документ в формате Word, где:
- все данные структурированы
- ответы приведены к единому виду
- поля с низким confidence выделены красным цветом для ручной проверки и привлечения внимания врача
5. UI системы
После того как парсинг документов достиг достаточного уровня качества, удовлетворяющего клиента и команду разработки, мы подготовили дизайн системы, чтобы клиент мог увидеть статус по каждой анкете, причину отказа обработки сервисами Azure и Gemini, если данный сценарий произошел, а также возможность скачать результат распознавания по клику.
Для быстрой разработки дизайна системы мы применили ChatGPT.
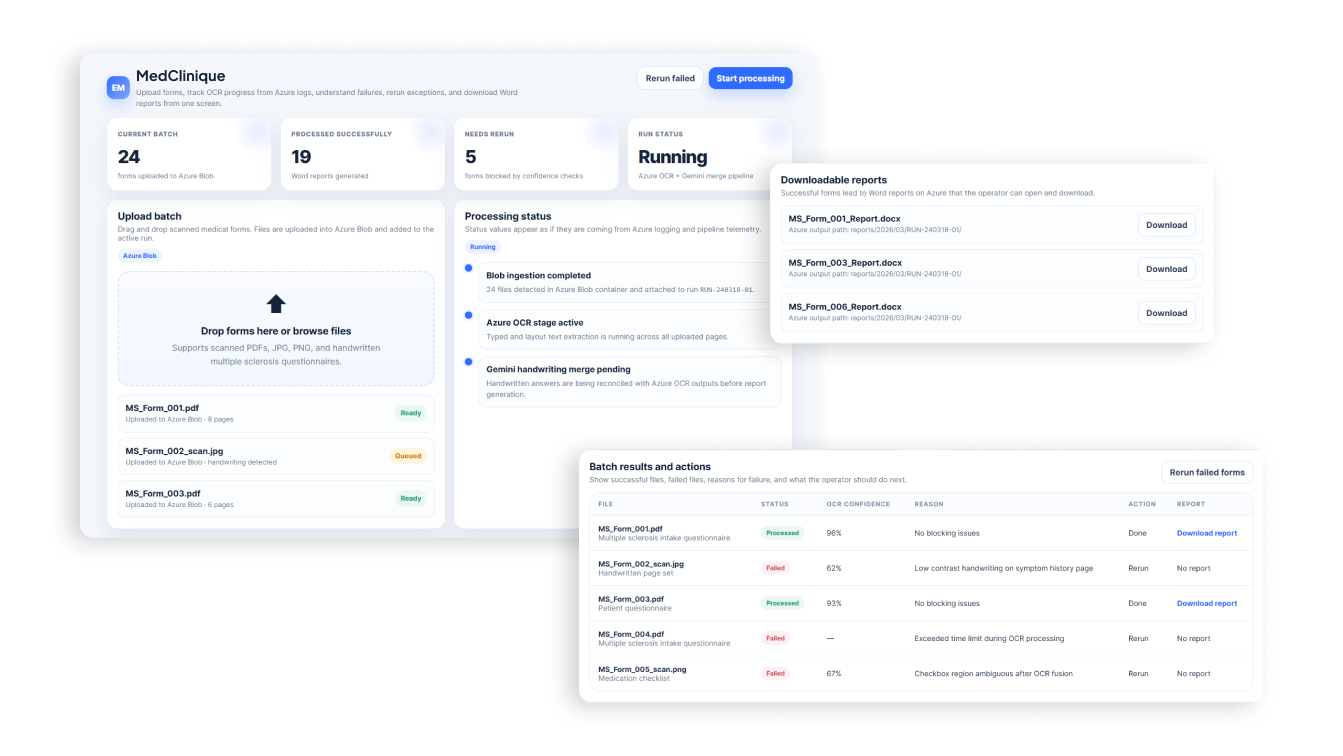
6. Пайплайн обработки анкет
- Пользователь загружает отсканированный PDF с анкетами в облачное хранилище
- Сервис автоматически подхватывает документы
- Выполняется классификация формы
- OCR извлекает текст и структуру
- CV-модель обрабатывает сложные визуальные паттерны
- LLM нормализует и структурирует данные
- Генерируется итоговый документ в формате word.
Результаты и развитие проекта
В ходе проекта удалось не только решить исходную задачу по оцифровке медицинских анкет, заполненных вручную, но и существенно повысить качество распознавания по сравнению с первоначальным подходом с 65% до 95%.
Это позволило практически исключить необходимость ручного ввода данных и перевести работу с анкетами в цифровой формат. Врачи получили возможность быстро ориентироваться в информации о пациентах, искать данные по симптомам и использовать их для принятия решений без необходимости просматривать сканы документов и разбирать почерк разных людей.
При этом важной частью решения стала система оценки confidence – потенциально неточные данные автоматически выделяются красным цветом в итоговом документе. Такой подход позволил сохранить баланс между автоматизацией и контролем качества, что особенно критично в медицинском контексте.
Несмотря на достигнутые результаты, проект продолжает развиваться. В процессе эксплуатации выявились новые требования со стороны бизнеса. В результате проект постепенно эволюционирует из набора backend-сервисов в полноценный пользовательский инструмент, ориентированный не только на качество распознавания, но и на удобство и предсказуемость работы для конечных пользователей.