Оптимизация пайплайна N8N для массовой обработки товарных каталогов

Задача
Наш клиент — реселлер бытовой электроники, который работает сразу с несколькими поставщиками и постоянно обновляет ассортимент. Каждый день в компанию приходят прайс-листы от поставщиков с тысячами позиций, и все эти товары нужно сопоставить с внутренней базой, где хранятся актуальные складские остатки.
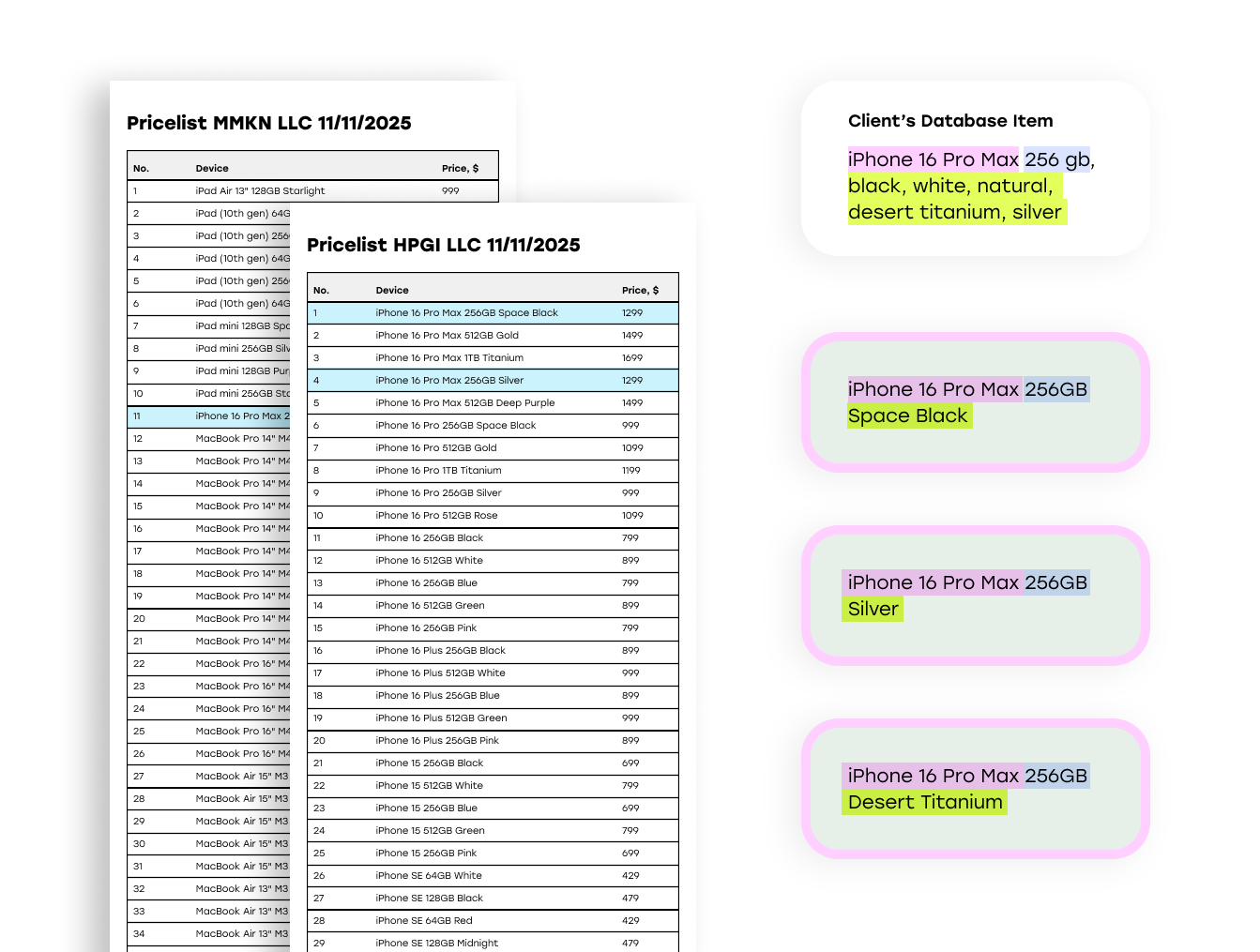
Проблема в том, что даже одинаковые устройства у разных поставщиков называются по‑разному: отличаются формулировки, порядок слов, артикулы и дополнительные пометки. Из‑за этого автоматическое сопоставление часто даёт сбой, а команде приходится вручную разбирать «подозрительные» строки, искать дубликаты и относить новые позиции в нужные категории.
У клиента уже был конвейер обработки в n8n, который помогал разбирать входящие прайс-листы, но на реальной нагрузке он перестал справляться:
- ежедневные импорты с более чем 1500 товарами обрабатывались слишком медленно;
- шаги с LLM работали нестабильно из‑за свободных, неструктурированных промптов, что снижало точность классификации;
- каждая позиция запускала отдельный SQL-запрос к базе, и при росте каталога это стало главным узким местом по производительности.

В этом проекте n8n используется как основной конвейер обработки прайс‑листов: через него проходят загрузка файлов, вызовы LLM и поиск по базе.
n8n — это платформа для автоматизации рабочих процессов и интеграции разных сервисов, которую можно запускать как в облаке, так и на своих серверах. Она позволяет собирать процессы из визуальных блоков (узлов), подключать базы данных, API и AI‑модели без большого объёма кода, а при необходимости дописывать логику на JavaScript или Python.
Клиенту нужна была оптимизация всего пайплайна: ускорить обработку крупных прайс-листов, повысить точность автоматического матчинга и свести ручную работу к минимуму.
Решение
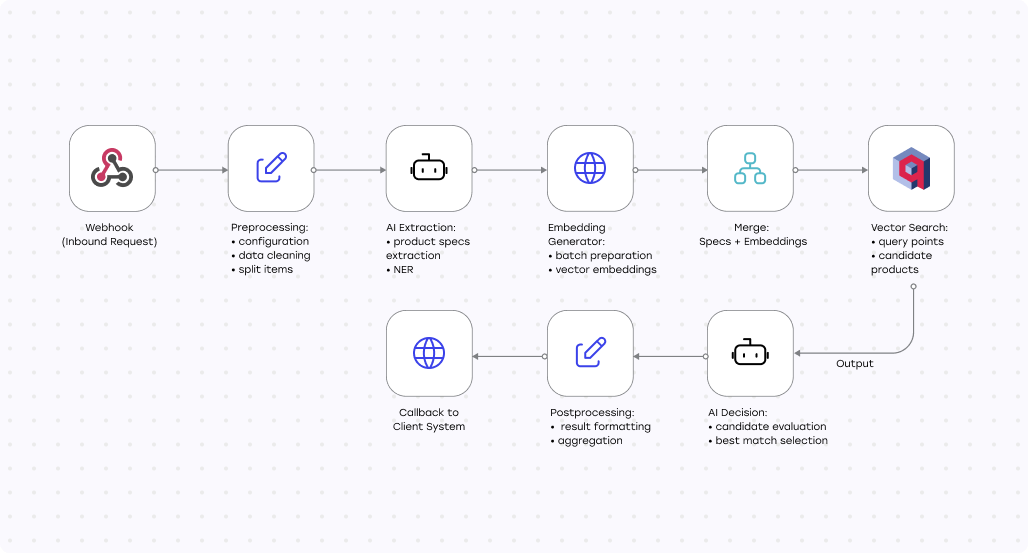
Мы переработали весь пайплайн так, чтобы он выдерживал ежедневную загрузку крупных прайс-листов и при этом оставался предсказуемым и простым в сопровождении. Основной фокус на производительности, стабильной работе LLM и отказе от медленных точечных SQL-запросов.
Ищете партнёра для внедрения ИИ-решений?
Свяжитесь с нами, чтобы начать трансформацию вашего бизнеса.
Оптимизация промптов LLM
Раньше для одной позиции использовалось несколько разрозненных промптов: один для классификации, другой для поиска похожих товаров, из-за чего LLM вызывалась по нескольку раз.
Мы собрали эту логику в один структурированный промпт с чёткими инструкциями, что сделало ответы более стабильными и сократило число обращений к модели; в результате LLM-часть пайплайна стала работать примерно в 2,5 раза быстрее.
Упрощение сценариев в n8n
Изначальный workflow в n8n содержал лишние ветвления и сервисные шаги, которые замедляли обработку больших файлов. Мы отрефакторили конвейер, минимизировав количество шагов обработки и сфокусировавшись на производительности.
В результате рабочий процесс теперь способен обрабатывать ежедневные импорты из тысяч записей без задержек, с которыми ранее сталкивался клиент.
Переход от SQL к векторному поиску
Ключевым источником задержек была база данных: для каждого товара выполнялся отдельный SQL-запрос, и при росте каталога это происходило всё медленнее.
Мы внедрили векторную базу данных Qdrant, чтобы включить семантическое сопоставление и пакетный поиск по похожести, обеспечив быстрый поиск релевантных кандидатов и более точное сопоставление товаров, несмотря на различия в схемах именования у поставщиков.
Что это нам дало:
- Сравнение сотен кандидатов одновременно,
- Более точное сопоставление на основе семантики товаров, а не буквальных названий,
- В 5–10 раз более быстрое извлечение по сравнению с последовательными SQL-запросами.
Результаты
После доработки пайплайна система перестала быть “узким горлышком” в ежедневной обработке прайс-листов:
- Полный цикл импорта теперь проходит примерно в 2,5 раза быстрее, чем до оптимизации.
- Шаги, связанные с LLM, стали выполняться в 2,5 раза быстрее благодаря консолидации промптов.
- Время поиска по базе данных сократилось в 5–10 раз с Qdrant. Вместо тысяч последовательных SQL-запросов система сразу подбирает и рассматривает подходящие варианты для каждой позиции.
- Повысилась точность сопоставления товаров, что сократило объем ручной проверки.
- Клиент получил масштабируемую архитектуру, готовую к росту ежедневных объемов данных.
Оптимизированный рабочий процесс теперь быстро и надежно обрабатывает крупные прайс-листы поставщиков, позволяя клиенту поддерживать актуальность товарного каталога при минимальном объеме ручного вмешательства.
Не подходят коробочные решения?
Разработаем кастомное ИИ-решение для работы над КП: анализ входящих запросов, интеллектуальный поиск по базе и автоматическое формирование КП.